ARTS #004
ARTS #004
ARTS is an activity initiated by
由左耳朵耗子--陈皓: Do at least one leetcode algorithm question every week, read and comment on at least one English technical article, learn at least one technical skill, and share an article with opinions and thoughts. (That is, Algorithm, Review, Tip, and Share are referred to as ARTS) and persist for at least one year.
ARTS 004
This is the fourth article. It is relatively poorly written. I hope it will get better and better in the future.
Algorihm algorithm question
leetcode algorithm question 321 Create Maximum Number (maximum splicing number) Could it be: difficult
Given two arrays of length m and n with digits 0-9 representing two numbers. Create the maximum number of length k <= m + n from digits of the two. The relative order of the digits from the same array must be preserved. Return an array of the k digits.
Note: You should try to optimize your time and space complexity.
Example 1:
Input:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
Output:
[9, 8, 6, 5, 3]
Example 2:
Input:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
Output:
[6, 7, 6, 0, 4]
Example 3:
Input:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
Output:
[9, 8, 9]
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
示例 1:
输入:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
输出:
[9, 8, 6, 5, 3]
示例 2:
输入:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
输出:
[6, 7, 6, 0, 4]
示例 3:
输入:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
输出:
[9, 8, 9]
Problem-solving ideas:
-
1 Determine how many numbers each of the two arrays takes, for example, k=5, which can be split into 1, 4; 2, 3; 3, 2; 4, 1; and it must be smaller than the number of nums1 or nums2. This step is relatively simple.
-
2 Combine the subarrays that meet the conditions into one This step is more complicated. For example, nums1 = [6, 7, 0]; nums2 = [6, 0, 4], k=5; k can be split into 2, 3; 3, 2; Now consider the cases 2 and 3, nums1_1 = [6, 7]; nums2_1 = [6, 0, 4]; So how do you combine these two sub-arrays into a maximum number? At first glance, it seems quite simple. Just take one from each of the two arrays and choose whichever is larger. But there is a pitfall here. What should I do if the sizes are the same? For example, the first numbers of nums1_1 and nums2_1 are both 6, which one should be chosen? Let’s see what’s different. If you take 6 from nums2_1 for the first time, after taking it, nums1_1 = [6, 7]; nums2_1 = [0, 4]; The second time nums1_1 takes 6, nums2_1 can only take 0, 6 is larger than 0, so take 6, after taking it, nums1_1 = [7]; nums2_1 = [0, 4];, the final result is [6,6,7,0,4]
If you take 6 from nums1_1 for the first time, after taking it, nums1_1 = [7]; nums2_1 = [6,0, 4]; For the second time, nums1_1 takes 7, and nums2_1 takes 6. 7 is larger than 6, so 7 is taken. After taking it, nums1_1 = []; nums2_1 = [6,0, 4];, the final result is [6,7,6,0,4]
The results are different, obviously the second one is right. Is the merging method we used above similar to the algorithm used in merge sort, but when merging arrays in merge sort, the two arrays are in order, but the two arrays we merge here are unordered, so we will encounter this problem. My internship code is as follows:
/**
* Return an array of size *returnSize.
* Note: The returned array must be malloced, assume caller calls free().
*/
int maxInexd(int* nums,int max,int min){
int maxindex = min;
int count = nums[maxindex];
for (int i = min; i<=max; i++) {
if (nums[i] > count) {
count = nums[i];
maxindex = i;
}
}
return maxindex;
}
int* maxNumber1(int* nums, int numsSize, int numcount){
int *a = (int *)malloc(numcount*sizeof(int));
int index = -1;
for (int i = 0; i < numcount; i++) {
index = maxInexd(nums, numsSize - numcount +i, index+1);
a[i] = nums[index];
}
return a;
}
int* merge(int* num11, int nums1count, int* num22, int nums2count, int k){
//把两个数组合并为一个
int* tempReturnSize = (int *)malloc(k*sizeof(int));
int mm = 0;
int nn = 0;
for (int i = 0; i < k; i++) {
if (mm == nums1count) {
int a = num22[nn];
tempReturnSize[i] = a;
nn++;
continue;
}
if (nn == nums2count) {
int b = num11[mm];
tempReturnSize[i] = b;
mm++;
continue;
}
int aa = num11[mm];
int bb = num22[nn];
if (aa >bb) {
tempReturnSize[i] = aa;
mm++;
}
else if (aa == bb){
int aa1 = aa;
int bb1 = bb;
int ii = 0;
while (mm + ii +1 != nums1count && nn + ii+1 != nums2count && aa1 ==bb1 ) {
ii++;
aa1 = num11[mm + ii];
bb1 = num22[nn + ii];
}
if (aa1 > bb1) {
tempReturnSize[i] = aa;
mm++;
continue;
}
else if(aa1 < bb1){
tempReturnSize[i] = bb;
nn++;
continue;
}
if (mm + ii +1 == nums1count) {//说明没有下一个
tempReturnSize[i] = bb;
nn++;
continue;
}
if (nn + ii +1 == nums2count) {//说明没有下一个
tempReturnSize[i] = bb;
mm++;
continue;
}
}
else{
tempReturnSize[i] = bb;
nn++;
}
}
return tempReturnSize;
}
int* maxNumber(int* nums1, int nums1Size, int* nums2, int nums2Size, int k, int* returnSize) {
*returnSize = k; //在leetcode提交的时候,不知道为什么要加上这个
if (nums1Size ==0) {
return nums2;
}
if (nums2Size ==0) {
return nums1;
}
int* relsut = (int*)malloc(sizeof(int) * k);
memset(relsut, 0, sizeof(int) * k);
int nums1count, nums2count;
for (nums1count = 1; nums1count <= nums1Size; nums1count++) {//nums1count 表示从nums1数组取的数的个数 最少是1 最大是nums1Size
nums2count = k - nums1count;
if (nums2count > nums2Size) {
continue;
}
if(nums2count == 0){//不能不从nums2取值
break;
}
//从nums1中按序取出nums1count个数,且这个几个数按序组装成整数之后是最大的
int *num11 = maxNumber1(nums1, nums1Size,nums1count);
//从nums2中按序取出nums2count个数,且这个几个数按序组装成整数之后是最大的
int *num22 = maxNumber1(nums2, nums2Size,nums2count);
//把两个数组合并为一个
int* tempReturnSize =merge( num11, nums1count, num22, nums2count, k);
//比较最大的数值
for (int i = 0; i < k; i++) {
int aa = tempReturnSize[i];
int bb = relsut[i];
if (aa > bb) {
for (int j = 0; j < k; j++){
relsut[j] = tempReturnSize[j];
}
break;
}
else if (bb >aa){
break;
}
}
free(tempReturnSize);
free(num11);
free(num22);
}
return relsut;
}
The running time in LeetCode is 20ms. The following code is a code submitted in LeetCode with a running time of 8ms. It feels similar to my implementation. I don’t know where it is faster:
void maxNum(int*, int, int, int*);
void merge(int*, int, int*, int, int*);
void max(int*, int*, int);
int* maxNumber(int* nums1, int nums1Size, int* nums2, int nums2Size, int k, int* returnSize)
{
*returnSize = k;
int* result = (int*)malloc(sizeof(int) * k);
memset(result, 0, sizeof(int) * k);
int* merged = (int*)malloc(sizeof(int) * k);
int *max1 = NULL, *max2 = NULL;
for (int i = 0; i <= k; i++) {
int n1 = i, n2 = k - i;
if (n1 > nums1Size || n2 > nums2Size)
continue;
max1 = realloc(max1, sizeof(int) * n1);
maxNum(nums1, nums1Size, n1, max1);
max2 = realloc(max2, sizeof(int) * n2);
maxNum(nums2, nums2Size, n2, max2);
merge(max1, n1, max2, n2, merged);
max(result, merged, k);
}
free(max1), free(max2), free(merged);
return result;
}
void maxNum(int* nums, int n, int k, int* r)
{
for (int i = 0, j = 0; i < n; i++) {
// drop last one
while (j > 0 && k - j < n - i && nums[i] > r[j - 1])
j--;
if (j < k)
r[j++] = nums[i];
}
}
void merge(int* nums1, int n1, int* nums2, int n2, int* r)
{
for (int i = 0, j = 0, k = 0; k < n1 + n2; k++) {
int val1 = i < n1 ? nums1[i] : -1;
int val2 = j < n2 ? nums2[j] : -1;
int t = 1;
while (val1 == val2 && val1 != -1) {
val1 = i + t < n1 ? nums1[i + t] : -1;
val2 = j + t < n2 ? nums2[j + t] : -1;
t++;
}
if (val1 > val2)
r[k] = nums1[i++];
else if (val1 < val2)
r[k] = nums2[j++];
else
// val1 == val2 == -1
r[k] = nums1[i++];
}
}
void max(int* nums1, int* nums2, int n)
{
int i;
for (i = 0; i < n; i++) {
if (nums1[i] < nums2[i])
break;
if (nums1[i] > nums2[i])
return;
}
if (i != n)
// set the new max
for (i = 0; i < n; i++)
nums1[i] = nums2[i];
}
Review
This article comes from: https://medium.com/exploring-code/why-should-you-learn-go-f607681fad65
Why should you learn Go? (Why should you learn Go)

Image from: http://kirael-art.deviantart.com/art/Go-lang-Mascot-458285682
“Go will be the server language of the future.” — Tobias Lütke, Shopify
In past couple of years, there is a rise of new programming language: Go or GoLang. Nothing makes a developer crazy than a new programming language, right? So, I started learning Go before 4 to 5 months and here I am going to tell you about why you should also learn this new language.
In the past few years, a new programming language has emerged: Go or GoLang. Nothing drives developers crazy except new programming languages, right? So, I started learning Go 4 to 5 months ago and here I will tell you why you should also learn this new language.
I am not going to teach you, how you can write “Hello World!!” in this article. There are lots of other articles online for that. I am going the explain current stage of computer hardware-software and why we need new language like Go? Because if there isn’t any problem, then we don’t need solution, right?
In this article, I’m not going to teach you how to write “Hello World!!”. There are already many similar articles on the Internet. “I’m going to explain now why we need a new language like Go at the current stage of computer hardware and software?” Because if there aren’t any problems, then we don’t need a solution, right?
#####Hardware limitations: Moore’s law is failing. First Pentium 4 processor with 3.0GHz clock speed was introduced back in 2004 by Intel. Today, my Mackbook Pro 2016 has clock speed of 2.9GHz. So, nearly in one decade, there is not too much gain in the raw processing power. You can see the comparison of increasing the processing power with the time in below chart.
摩尔定律失效了
Intel launched the first Pentium 4 processor with a 3.0GHz clock speed in 2004. Today, my Mackbook Pro 2016 has a clock speed of 2.9GHz. Therefore, for almost ten years, raw processing power has not improved much. You can see the increase in processing power versus time in the graph below.
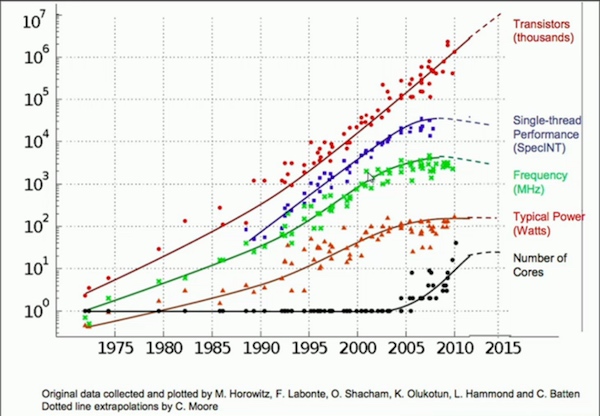
From the above chart you can see that the single-thread performance and the frequency of the processor remained steady for almost a decade. If you are thinking that adding more transistor is the solution, then you are wrong. This is because at smaller scale some quantum properties starts to emerge (like tunneling) and because it actually costs more to put more transistors (why?) and the number of transistors you can add per dollar starts to fall.
As you can see from the graph above, single-thread performance and processor frequency have remained stable for nearly a decade. If you think adding more transistors is the solution, you’re wrong. This is because at smaller scales, some quantum properties start to appear (like tunneling), and because putting more transistors actually costs more why, and the number of transistors that can be added per dollar starts to drop.
So, for the solution of above problem, So, the solution to the above problem is as follows,
- Manufacturers started adding more and more cores to the processor. Nowadays we have quad-core and octa-core CPUs available.
- Manufacturers began adding more and more cores to processors. Today we have quad-core and eight-core CPUs available.
- We also introduced hyper-threading.
- We also introduced Hyper-Threading.
- Added more cache to the processor to increase the performance.
- Added more cache to the processor to improve performance.
But above solutions have its own limitations too. We cannot add more and more cache to the processor to increase performance as cache have physical limits: the bigger the cache, the slower it gets. Adding more core to the processor has its cost too. Also, that cannot scale to indefinitely. These multi-core processors can run multiple threads simultaneously and that brings concurrency to the picture. We’ll discuss it later.
But the above solutions also have their own limitations. We can’t add more and more cache to the processor to improve performance because cache has physical limitations: the larger the cache, the slower you get. Adding more cores to a processor also has its costs. And, this doesn’t scale infinitely. These multi-core processors can run multiple threads simultaneously, bringing concurrency to images. We’ll discuss it later.So, if we cannot rely on the hardware improvements, the only way to go is more efficient software to increase the performance. But sadly, modern programming language are not much efficient. Therefore, if we cannot rely on hardware improvements, the only way out is to improve the performance of software. But unfortunately, modern programming languages are not very efficient.
“Modern processors are a like nitro fueled funny cars, they excel at the quarter mile. Unfortunately modern programming languages are like Monte Carlo, they are full of twists and turns.” — David Ungar
“现代处理器就像硝基燃料有趣的汽车,他们擅长四分之一英里。 不幸的是,现代编程语言就像蒙特卡罗,它们充满了曲折。“ - David Ungar
Go has goroutines!!
As we discussed above, hardware manufacturers are adding more and more cores to the processors to increase the performance. All the data centers are running on those processors and we should expect increase in the number of cores in upcoming years. More to that, today’s applications using multiple micro-services for maintaining database connections, message queues and maintain caches. So, the software we develop and the programming languages should support concurrency easily and they should be scalable with increased number of cores.
As mentioned above, hardware manufacturers are adding more and more cores to processors to improve performance. All data centers run on these processors, and we expect the core count to increase in the coming years. What’s more, today’s applications use multiple microservices to maintain database connections, message queues and maintain caches. Therefore, the software and programming languages we develop should easily support concurrency, and they should be scalable as the number of cores increases.
But, most of the modern programming languages (like Java, Python etc.) are from the ’90s single threaded environment. Most of those programming languages supports multi-threading. But the real problem comes with concurrent execution, threading-locking, race conditions and deadlocks. Those things make it hard to create a multi-threading application on those languages.
However, most modern programming languages like Java, Python, etc. come from the single-threaded environment of the 90s. Most programming languages support multithreading. But the real problems are concurrent execution, thread locking, race conditions and deadlocks. These things make it difficult to create multi-threaded applications on these languages.
For an example, creating new thread in Java is not efficient memory. As every thread consumes approx 1MB of the memory heap size and eventually if you start spinning thousands of threads, they will put tremendous pressure on the heap and will cause shut down due to out of memory. Also, if you want to communicate between two or more threads, it’s very difficult. For example, creating a new thread in Java is not memory efficient. Because each thread consumes about 1MB of memory heap size, and eventually if you start spinning thousands of threads, they will put huge pressure on the heap and cause shutdowns due to insufficient memory. Also, if you want to communicate between two or more threads, it’s very difficult.
On the other hand, Go was released in 2009 when multi-core processors were already available. That’s why Go is built with keeping concurrency in mind. Go has goroutines instead of threads. They consume almost 2KB memory from the heap. So, you can spin millions of goroutines at any time.
Go, on the other hand, was released in 2009, when multi-core processors were already available. This is why Go is built with concurrency in mind. Go has goroutines instead of threads. They consume about 2KB of memory from the heap. So you can spin up millions of goroutines at any time.
 How Goroutines work? Refrance: http://golangtutorials.blogspot.in/2011/06/goroutines.html
How Goroutines work? Refrance: http://golangtutorials.blogspot.in/2011/06/goroutines.html
Other benefits are:
- Goroutines have growable segmented stacks. That means they will use more memory only when needed.
- Goroutines have growable segmented stacks. This means they only use more memory when needed.
- Goroutines have a faster startup time than threads.
- Goroutines have faster startup time than threads.
- Goroutines come with built-in primitives to communicate safely between themselves (channels).
- Goroutines come with built-in primitives to safely communicate between them (channels).
- Goroutines allow you to avoid having to resort to mutex locking when sharing data structures.
- Goroutines allow you to avoid using mutex locks when sharing data structures.
- Also, goroutines and OS threads do not have 1:1 mapping. A single goroutine can run on multiple threads. Goroutines are multiplexed into small number of OS threads.
- Additionally, there is no 1:1 mapping between goroutines and OS threads. A single goroutine can run on multiple threads. Goroutines are multiplexed into a small number of OS threads.
You can see Rob Pike’s excellent talk [concurrency is not parallelism](https://blog.golang.org/concurrency-is-not-parallelism) to get more deep understanding on this.
All the above points, make Go very powerful to handle concurrency like Java, C and C++ while keeping concurrency execution code strait and beautiful like Erlang. The above points make Go very powerful. It can be as efficient as Java, C and C++ when handling concurrent operations, and as beautiful as Erlang.
 Go takes good of both the worlds. Easy to write concurrent and efficient to manage concurrency
Go excels in both worlds. Easy to write concurrency and efficient management of concurrency
Go takes good of both the worlds. Easy to write concurrent and efficient to manage concurrency
Go excels in both worlds. Easy to write concurrency and efficient management of concurrency
#####Go runs directly on underlying hardware(Go runs directly on underlying hardware.). One most considerable benefit of using C, C++ over other modern higher level languages like Java/Python is their performance. Because C/C++ are compiled and not interpreted. One of the biggest benefits of using C, C++ is their performance compared to other modern high-level languages like Java/Python. Because C/C++ is compiled not interpreted.Processors understand binaries. Generally, when you build an application using Java or other JVM-based languages when you compile your project, it compiles the human readable code to byte-code which can be understood by JVM or other virtual machines that run on top of underlying OS. While execution, VM interprets those bytecodes and convert them to the binaries that processors can understand. The processor understands binary files. Typically when building an application using Java or other JVM-based languages when compiling the project, it compiles human-readable code into byte code that can be understood by the JVM or other virtual machine running on top of the underlying operating system. When executed, the VM interprets these bytecodes and converts them into binaries that the processor can understand
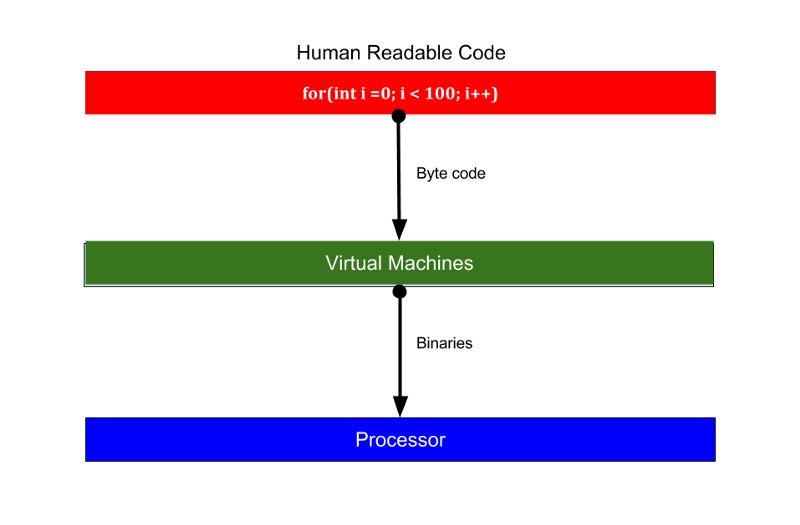 Execution steps for VM based languages
Execution steps for VM based languages
While on the other side, C/C++ does not execute on VMs and that removes one step from the execution cycle and increases the performance. It directly compiles the human readable code to binaries.
C/C++ on the other hand does not execute on the VM and removes this step from the execution cycle and improves performance. It compiles human-readable code directly into binaries.
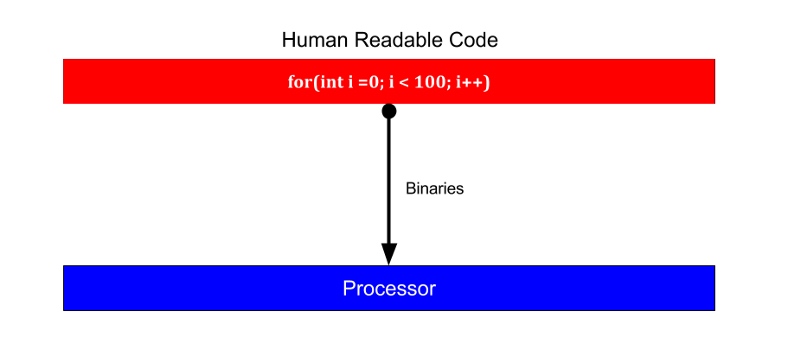
But, freeing and allocating variable in those languages is a huge pain. While most of the programming languages handle object allocation and removing using Garbage Collector or Reference Counting algorithms. However, freeing and assigning variables is a huge pain in these languages. While most programming languages use a garbage collector or reference counting algorithm to handle the creation and release of objects.
Go brings best of both the worlds. Like lower level languages like C/C++, Go is compiled language. That means performance is almost nearer to lower level languages. It also uses garbage collection to allocation and removal of the object. So, no more malloc() and free() statements!!! Cool!!! Go brings the best of both worlds. Like low-level languages like C/C++, Go is a compiled language. This means performance is almost close to lower level languages. It also uses garbage collection to allocate and delete objects. So, no more malloc() and free() statements! Cool! ! !
#####Code written in Go is easy to maintain (code written in Go is easy to maintain). Let me tell you one thing. Go does not have crazy programming syntax like other languages have. It has very neat and clean syntax. Let me tell you something. Go doesn’t have crazy programming syntax like other languages. It has a very neat and clear syntax.
The designers of the Go at google had this thing in mind when they were creating the language. As google has the very large code-base and thousands of developers were working on that same code-base, code should be simple to understand for other developers and one segment of code should has minimum side effect on another segment of the code. That will make code easily maintainable and easy to modify. The designers of Go had this in mind when they created the language at Google. Since Google has a very large code base with thousands of developers working on the same code base, the code should be easy to understand for other developers and one section of the code should have minimal side effects on another section of the code. This will make the code maintainable and easy to modify.
Go intentionally leaves out many features of modern OOP languages. Go intentionally leaves out many features of modern OOP languages.
- No classes. Every thing is divided into packages only. Go has only structs instead of classes.
- No class. Everything is divided into packages only. Go only has structs not classes.
Does not support inheritance. That will make code easy to modify. In other languages like Java/Python, if the class ABC inherits class XYZ and you make some changes in class XYZ, then that may produce some side effects in other classes that inherit XYZ. By removing inheritance, Go makes it easy to understand the code also (as there is no super class to look at while looking at a piece of code). *不支持继承. This will make the code easy to modify. In other languages like Java/Python, if class ABC inherits class XYZ and you make some changes in class XYZ, then this may have some side effects in other classes that inherit from XYZ. By removing inheritance, Go makes it easier to understand the code (since there is no superclass to look at when looking at a piece of code).- No constructors.
- No annotations.
- No generics.
- No exceptions.
Above changes make Go very different from other languages and it makes programming in Go different from others. You may not like some points from above. But, it is not like you can not code your application without above features. All you have to do is write 2–3 more lines. But on the positive side, it will make your code cleaner and add more clarity to your code. The above changes make Go very different from other languages, and programming in Go is also different from other languages. You may not like some of the points above. However, you can’t code your application without the above features. All you have to do is write 2-3 more lines. But on the positive side, it will make your code cleaner and add more clarity to your code.
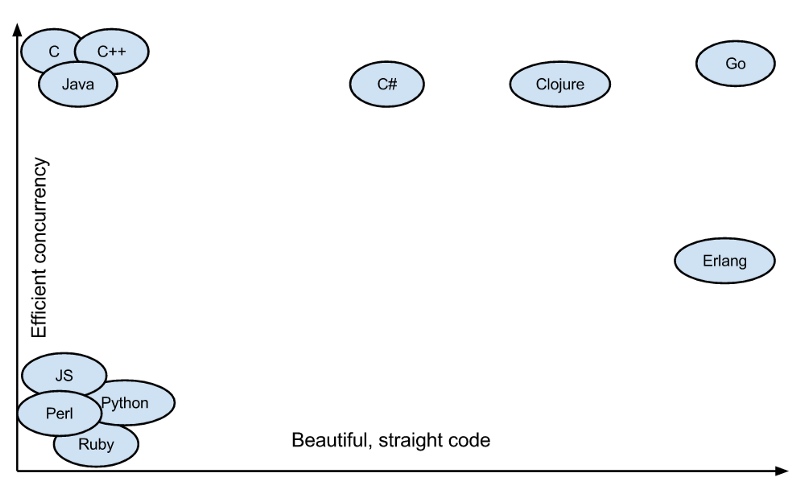
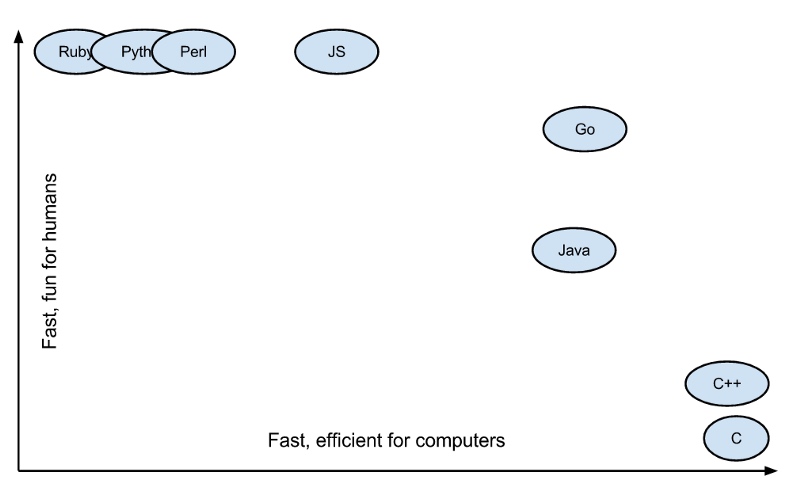 Code readability vs, Efficiency.
Code readability vs, Efficiency.
Above graph displays that Go is almost as efficient as C/C++, while keeping the code syntax simple as Ruby, Python and other languages. That is a win-win situation for both humans and processors!!! The above image shows that Go is almost as efficient as C/C++ while keeping the code syntax simple like Ruby, Python and other languages. It’s a win-win situation for both humans and processors!
Unlike other new languages like Swift, it’s syntax of Go is very stable. It remained the same since the initial public release 1.0, back in year 2012. That makes it backward compatible. Unlike other new languages such as Swift, Go’s syntax is very stable. It has remained unchanged since the initial public release of 1.0 in 2012. This makes it backwards compatible.##### Go is backed by Google.(Go is backed by Google.)
- I know this is not a direct technical advantage. But, Go is designed and supported by Google. Google has one of the largest cloud infrastructures in the world and it is scaled massively. Go is designed by Google to solve their problems of supporting scalability and effectiveness. Those are the same issues you will face while creating your own servers. *I know this is not a direct technical advantage. However, Go is designed and supported by Google. Google has one of the largest cloud infrastructures in the world, and it’s massive. Go was designed by Google to solve the problems of supporting scalability and effectiveness. These are the same questions you will face when creating your own server.
- More to that Go is also used by some big companies like Adobe, BBC, IBM, Intel and even Medium.(Source: https://github.com/golang/go/wiki/GoUsers)
- What’s more important is that Go is also used by some big companies, such as Adobe, BBC, IBM, Intel and even Medium. (Source: https://github.com/golang/go/wiki/GoUsers)
Conclusion:
- Even though Go is very different from other object-oriented languages, it is still the same beast. Go provides you high performance like C/C++, super efficient concurrency handling like Java and fun to code like Python/Perl.
- Although Go is very different from other object-oriented languages, it is still the same beast. Go gives you high performance like C/C++, ultra-efficient concurrency processing like Java, and the joy of coding like Python/Perl.
- If you don’t have any plans to learn Go, I will still say hardware limit puts pressure to us, software developers to write super efficient code. Developer needs to understand the hardware and make their program optimize accordingly. The optimized software can run on cheaper and slower hardware (like IOT devices) and overall better impact on end user experience.
- If you don’t have any plans to learn Go, I would still say that hardware limitations put pressure on us as software developers to write super efficient code. Developers need to understand the hardware and optimize their programs accordingly. Optimized software can run on cheaper and slower hardware (such as IoT devices) and overall have a better impact on the end-user experience.
Tip
How to collect Crash logs through online APP
-
Use NSSetUncaughtExceptionHandler, a ready-made function provided in the iOS SDK. NSSetUncaughtExceptionHandler is used for exception handling. The usage is as follows:
//异常回调方法 void UncaughtExceptionHandler(NSException *exception) { NSArray *arr = [exception callStackSymbols]; NSString *reason = [exception reason]; NSString *name = [exception name]; NSLog(@"%@\n%@\n%@",arr, reason, name); } - (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions { // Override point for customization after application launch. NSSetUncaughtExceptionHandler(&UncaughtExceptionHandler);//注册异常回调方法 NSArray *arr = @[@(0), @(1)]; NSLog(@"%@", arr[2]); //模拟越界异常 return YES; }One thing you need to pay attention to when using it is that when multiple crash log collection services coexist, for example, the third-party SDK used in the project may have its own integrated crash collection service. When there are multiple Crash collection services, competition will occur, causing some Crash services to not work properly. If multiple parties register exception handlers through NSSetUncaughtExceptionHandler at the same time, the peaceful approach is: the later registrant will use NSGetUncaughtExceptionHandler to take out and back up the handler previously registered by others, and after its own handler is processed, consciously register other people’s handlers back, and pass them on in an orderly manner. The consequence of not passing the forced override is that the Crash log written by the log collection service registered before will lose the Last Exception Backtrace and other information because it cannot get the NSException. (P.S. The Crash Reporter that comes with the iOS system is not affected) During the development and testing phase, you can use the fishhook framework to hook the NSSetUncaughtExceptionHandler method, so that you can clearly see where the handler’s delivery process is broken, and quickly locate environmental polluters. It is not recommended to use the debugger to add symbolic breakpoints to check because some crash collection frameworks do not work in debugging state.
Detection code example:
static NSUncaughtExceptionHandler *g_vaildUncaughtExceptionHandler; static void (*ori_NSSetUncaughtExceptionHandler)( NSUncaughtExceptionHandler * ); void my_NSSetUncaughtExceptionHandler( NSUncaughtExceptionHandler * handler) { g_vaildUncaughtExceptionHandler = NSGetUncaughtExceptionHandler(); if (g_vaildUncaughtExceptionHandler != NULL) { NSLog(@"UncaughtExceptionHandler=%p",g_vaildUncaughtExceptionHandler); } ori_NSSetUncaughtExceptionHandler(handler); NSLog(@"%@",[NSThread callStackSymbols]); g_vaildUncaughtExceptionHandler = NSGetUncaughtExceptionHandler(); NSLog(@"UncaughtExceptionHandler=%p",g_vaildUncaughtExceptionHandler); }The above paragraph is excerpted from - Talking about iOS Crash Collection Framework: http://www.cocoachina.com/ios/20150701/12301.html
-
Using signal, NSSetUncaughtExceptionHandler cannot handle all exceptions. For crashes caused by EXC_BAD_ACCESS, NSSetUncaughtExceptionHandler is powerless. In this case, signal needs to be used to handle it. What is Signal?
In computer science, signals are a restricted method of inter-process communication in Unix, Unix-like, and other POSIX-compliant operating systems. It is an asynchronous notification mechanism used to remind the process that an event has occurred. When a signal is sent to a process, the operating system interrupts the normal flow of control of the process. At this time, any non-atomic operations will be interrupted. If the process defines a signal handler, it will be executed, otherwise the default handler will be executed.
The usage method is the same as above, which is also achieved by registering callbacks. 1 Register
void InstallUncaughtExceptionHandler(void){ //设置信号类型的异常处理 signal(SIGABRT, HandleSignal); signal(SIGILL, HandleSignal); signal(SIGSEGV, HandleSignal); signal(SIGFPE, HandleSignal); signal(SIGBUS, HandleSignal); signal(SIGPIPE, HandleSignal); } void HandleSignal(int signal){ int32_t exceptionCount= OSAtomicIncrement32(&exceptionCount); if (exceptionCount>exceptionMaximum) { return; } NSMutableDictionary *userInfo=[NSMutableDictionary dictionaryWithObject:[NSNumber numberWithInt:signal] forKey:UncaughtExceptionHandlerSignalKey]; NSArray *callBack=[UncaughtExceptionHandler backtrace]; [userInfo setObject:callBack forKey:UncaughtExceptionHandlerAddressesKey]; UncaughtExceptionHandler *uncaughtExceptionHandler=[[UncaughtExceptionHandler alloc] init]; NSException *signalException=[NSException exceptionWithName:UncaughtExceptionHandlerSignalExceptionName reason:[NSString stringWithFormat:@"Signal %d was raised.",signal] userInfo:userInfo]; [uncaughtExceptionHandler performSelectorOnMainThread:@selector(handleException:) withObject:signalException waitUntilDone:YES]; }For details, please refer to the code: https://github.com/dandan2009/Signal
iOS Crash collection is a big topic. This article is a preliminary introduction. If you want to go deeper, you need to understand the operating system and other knowledge. Let’s study it in depth later.
Reference: Talking about iOS Crash collection framework: http://www.cocoachina.com/ios/20150701/12301.html iOS crash analysis: https://www.jianshu.com/p/1b804426d212、http://www.qidiandasheng.com/2016/04/10/crash-xuebeng/ iOS application crash log analysis: http://www.cocoachina.com/industry/20130725/6677.html iOS exception capture: http://www.iosxxx.com/blog/2015-08-29-iosyi-chang-bu-huo.html Use signal to allow the app to crash calmly: https://www.cnblogs.com/daxiaxiaohao/p/4466097.html https://github.com/walkdianzi/DSSignalHandlerDemo
Share
Share some English learning methods for students who have not passed CET-4, have a poor English foundation, and want to improve their English: (Most of the following content is excerpted, please click on the corresponding link for details)
-
Learning English APP: In fact, go to the App Store and search for the keywords English and English reading. There are many APPs, some are paid and some are free. You can choose according to your needs.
-
English learning website https://www.rong-chang.com/ http://www.bbc.co.uk/learningenglish/ https://dictionary.cambridge.org/ http://www.dictionary.com/ English scientific articles: https://medium.com/
-
Pronunciation practice: Himalaya Lai Shixiong’s Phonetic Symbol Course4. Mouse in the left ear–Chen Hao’s suggestion (see https://time.geekbang.org/column/intro/48 Chen Hao’s course for details):
- Stick to Google English keywords instead of searching Chinese in Google. 2 Only in English on GitHub. Write code comments in English, write Code Commit information, write Issues and Pull Requests in English, and write Wiki in English. 3 Commit to watching 5 minutes of videos on YouTube every day. There are related machine subtitles on YouTube. If it doesn’t work, just turn on the subtitles.
- Insist on using an English dictionary rather than a Chinese one. For example: Cambridge English Dictionary (https://dictionary.cambridge.org/) or Dictionary.com (http://www.dictionary.com/). You can install a Chrome extension called Google Dictionary (https://chrome.google.com/webstore/detail/google-dictionary-by-goog/mgijmajocgfcbeboacabfgobmjgjcoja).
- Insist on using English teaching materials instead of Chinese ones. For example: BBC’s Learning English (http://www.bbc.co.uk/learningenglish/), or check out some ESL websites, such as ESL: English as a Second Language (https://www.rong-chang.com/), which has some courses. 6 Spend money to take some online English courses and practice with foreigners using videos.
-
How did I learn English from tinyfool (How to break through listening, speaking, reading and writing without passing CET-4) (https://mp.weixin.qq.com/s?__biz=MjM5MjUwNzIyMA==&mid=207623278&idx=1&sn=051a2ecae8f0392631eb0967eefc607a#rd)摘录: Reading the documentation doesn’t require your English to be as good as mine. Just look it up in a dictionary. There are only a few hundred words in the technical documentation. You don’t need to memorize it at all. Just look it up every time you don’t understand something. You can basically master it after watching it for a week. This method has been said countless times, and those who refuse to try it will remain technically illiterate in English for the rest of their lives.
I haven’t passed CET-4… Anyway, when I look at the document, if I encounter a word I don’t know, I just use Google Translate… I check the API 3 or 5 times and you can’t even remember it… There are only a few technical words…
-
Learn hard. You have to watch American dramas that you don’t understand, you have to listen to podcasts that you don’t understand, you have to read books that you don’t understand, you have to have conversations with foreigners that you can’t understand, and you have to write English articles that you can’t write well.
-
Step by step. Although it is hard learning, you will definitely progress from the shallower to the deeper at the beginning, so that you always have a sense of accomplishment.
-
Pursue the maximum amount of material. The purpose of step-by-step is to never feel frustrated, so you can spend a lot of time watching American TV series (at least thousands of hours), listening to podcasts (hundreds of hours), talking nonsense to foreigners, and writing articles.
-
Gradually improve, and slowly evolve from learning the language itself to learning culture and learning to communicate with the world. The deeper this process is, the more motivated you will be to learn.
-
Don’t be impatient and don’t advance rashly. Every day will make you a pawn, and you won’t achieve anything quickly. It took me half a year to break through watching American TV series, but I still watch it now. It took me a month to listen to the Podcast for breakthrough. It took a few months to speak and a few months to write. It sounds like a waste of time, but after a few years, when I want to improve my abilities, I feel that the time I spent is not much, very little, and it is very worthwhile.
-
Stay happy, so you can persist in lifelong learning. Is my English level high? It is much higher than before. Is it high enough? Not high enough. But what I can be proud of is that now my English learning is lifelong learning. It doesn’t matter if you are higher than me. Most people don’t learn as fast as me, and unlike me who keeps learning, one day I will surpass you. (Of course, the most important thing is always to pursue yourself every day to surpass yesterday.)
-
-
Q&A from Zhihu: But in the end, I found that the most effective method is actually the stupidest method - read more, listen more, take more notes, write more, summarize, practice again and again…
In fact, there are not so many ways to learn English.
If you think about it carefully, many times, the so-called “most efficient” learning methods are often the least efficient. Because they only give you short-term satisfaction.
The key to long-term progress is whether you can persist. Persistence means doing the same thing over and over again.
And I gradually realized,
I will never learn English,
Because there are always words and usages that I don’t know,
But I am willing to keep learning until the last day.
Because lifelong learning is the coolest way for a person to live.
======== https://www.zhihu.com/question/19853667/answer/134793017 My method is very simple and brainless, and it should work for students who really love and really want to learn English well.
Whenever I see someone memorizing words seriously, I feel that this person must not be able to learn English well. The more words he memorizes and the more seriously he memorizes them, the farther away he is from the goal of being an English master.
I remember when I was in college, I always heard some classmates reciting “abandon, abandon, a, b, a, n, d, o,” loudly in the corridor.
n, a, b, a, n, d, o, n" over and over again. The more I recite it, the more passionate I become. I start reciting it from the first page of the vocabulary book. I can recite several pages in one night. I am so passionate about learning. It is not a waste of effort. I probably will forget everything the next day after I go back to sleep at night.
If a primary school student or a middle school student memorizes words like this to learn English, I think there is nothing wrong with it. If a college student who wants to take the CET-6 exam memorizes words like this to prepare for the exam, I really want to go over and take away his books and give him a mouthful. Is this really learning English? Later, I saw that those people who memorized words had relatively developed limbs, so I gave up the idea.
But I want to say, if you follow this learning method to learn English, then you should learn Chinese like this. Starting from the first page of the vocabulary list, you should memorize like this:
“One, one, horizontal, horizontal, horizontal.”
“Two, two, horizontal, horizontal, horizontal.”
“Three, three, horizontal, horizontal, horizontal, horizontal, horizontal.”
“Four, four, vertical, horizontal fold, left-handed, right-handed, horizontal, vertical, horizontal fold, left-handed, right-handed, horizontal, vertical, horizontal fold, left-handed, right-handed, horizontal.”
. . . . . .
If you fucking memorize the “biang biang noodles” of Shaanxi, I think you will die.
Let’s see how to write the word biang! This is really not how you learn English. I have never seen anyone learn Chinese this way, but many people learn English this way. Although English and Chinese are different, the principles are the same.
So how should we learn it?
In fact, you can imagine how you learn Chinese, and you can learn English from it.
When we were young, we learned to write Chinese characters, write new characters, and recognize words. This can be compared to memorizing words, but these are things you do when you are in elementary school. You can do this when you first learn a language, because your foundation is very poor at this stage, and you do not know the most common words, so you need to You have to write new words and memorize words, but you are already in high school, you are learning Chinese, and you start writing new words from the vocabulary list in primary school textbooks. What is the concept of writing new words? You are in college and have to take the CET-6 exam. You spend most of your time studying English memorizing words. I don’t believe you can learn English well.
How do we learn Chinese in high school?
Reading, reading, and reading again, in English are reading, reading, and reading, writing, writing, and writing again, in English are writing, writing, and writing.
Some people will definitely refute me and say, how can I read if I don’t know the words?
You can find some articles that are suitable for you to read and read a lot. During the reading process, you will definitely encounter many words that you do not know. You will also encounter unknown words or words that you do not understand during Chinese reading. This is normal. What should you do? Just look it up in the dictionary and then continue reading. As your reading volume increases, you will find that articles of this level require you to look up fewer and fewer words, and then you will switch to a high-level article to read. Just keep doing this. When your English reading volume reaches a certain level, your vocabulary will naturally increase.
Do you understand what I mean? Don’t memorize words, it will be too boring to remember. Read a lot, read like crazy. When your reading reaches a certain level, except for listening and speaking, your English will pass.
I’m afraid that my English will deteriorate if I forget to read in English one day, so my phone is always in English mode. Sometimes people want to use my phone but they can’t.
Learning English is so simple and so brainless. https://www.zhihu.com/question/26677313/answer/230847636?group_id=892423340218806272
=======
Many of the above contents are excerpts. For details, please click on the corresponding link: To summarize the above method, don’t be afraid of English, but learn it hard. The meaning of learning here is to dare to read English articles and not give up. When you encounter words you don’t know, you should actively look up the dictionary instead of giving up. It should not be painful. Once you feel that learning English is painful, you should stop learning. Really, the effect must be very poor at this time.
In fact, my English score during the college entrance examination went from a low score of 30 to more than 100. How did I improve at that time? It was actually reading. When reading, I would look up words in the dictionary and then memorize them. Memorizing words through reading articles is much better than memorizing words alone. If the foundation is not good, , you can start with simple articles first, and then gradually increase the difficulty. For technical articles, you can actually read most of them with the help of Google Translate. It depends on whether you can persist. As long as you can persist for half a year and read three English articles a week, I think your English 读 ability will also improve.
=======
What to read next
Want more posts about ARTS?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #iOS?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home