Data Structures 1 - Drilling down into data structures
Data Structures — Diving Into Data Structures (Part 1)
Data Structures — Diving Into Data Structures (Part 1) Data Structures - Diving Into Data Structures (Part 1)
Article source: https://medium.com/omarelgabrys-blog/diving-into-data-structures-6bc71b2e8f92
[TOC]
When we have a programming problem, we dive into the algorithm, while ignoring the underlying data structure. And even worse, we think that using another data structure won’t make much of a difference, although we could vastly improve the performance of our code by picking an alternative data structure. When we encounter a programming problem, we delve into algorithms while ignoring the underlying data structures. To make matters worse, we don’t think using another data structure will make much of a difference, even though we could greatly improve the performance of our code by choosing another data structure.
What Is A Data Structure What is a data structure
It doesn’t start without asking: What the heck data structure is? It doesn’t start by asking: What the hell is the data structure?
It’s an intentional arrangement of a collection of data that we’ve built. is an intentional arrangement of the data collection we construct.
Intentional Arrangement Deliberate arrangement
The intentional arrangement means the arrangement done on purpose to impose, to enforce, some kind of systematic organization on the data. Intentional arrangement refers to a purposeful arrangement aimed at some systematic organization of data. Deliberate arrangement refers to the deliberate arrangement of data into some systematic organization. Intentional arrangement refers to an intentional arrangement that enforces a certain systematic organization of data.
Because it’s useful, it makes our lives easier, and it’s easy to manage when you keep related information together. Because it is useful, it makes our lives easier and it is easy to manage when you put relevant information together.
Data Structures In our Life Data Structures in our life
We need data structures in our programs because we think this way as human beings. In our programs, we need data structures because that’s how we humans think.
A recipe is an actual data structure, as is a shopping list, a telephone directory, a dictionary, etc. They all have a structure, they have a format. A recipe is an actual data structure, just like a shopping list, phone book, dictionary, etc. They all have a structure, they all have a format.
Data Structure and Object Oriented Programming Data Structure and Object Oriented Programming
Now if you’re an object oriented programmer, you may be thinking, Well isn’t this what we do with classes and objects?. If you are an object-oriented programmer, you may be thinking, isn’t this what we do with classes and objects?
I mean, we define these real-world objects in a program because we think this way as human being, or at least we’re supposed to. I mean, we define these real-world objects in a program because we think like humans, or at least we’re supposed to think that way.
And yes, absolutely. Objects are a type of data structure, and not the only one. Yes, of course. An object is a data structure, not the only one.
Five Fundamental Behaviors Five Fundamental Behaviors
How to access, insert, delete, find, & sort. These are the operations that you will most likely going to perform. How to access, insert, delete, find and sort. These are the actions you are most likely to perform.
Not all of data structures have the five fundamental behaviors. Not all data structures have these five basic behaviors.
For example, many data structures don’t support any kind of searching behavior, It’s just a big collection, a big container of stuff, and If you need to find something, you just go through all of it yourself. And many don’t provide any kind of sorting behavior. Others are naturally sorted. For example, many data structures don’t support any kind of search behavior, it’s just a big collection, a big container of something, and if you need to find something, you just have to iterate over it yourself. And many don’t offer any sorting behavior. Other natural ordering.
Each data structure has it’s own different way, or different algorithm for sorting, inserting, finding, …etc, Why? Because, due to the nature of the data structure, there are algorithms used with specific data structure, where some other can’t be used. Every data structure has its own different way, or different algorithms for sorting, inserting, searching, etc. Why? Because, due to the nature of data structures, there are some algorithms that work with a specific data structure and some other algorithms cannot be used.
The more efficient & suitable the algorithm, the more you will have an optimized data structure. These algorithms might be built-in or implemented by developer to manage and run these data structures. The more efficient and applicable the algorithm is, the more optimized data structures can be obtained. These algorithms can be built-in or implemented by developers to manage and run these data structures.
Always read the language documentation and check the performance of the algorithms used with the underlying data structure. Different algorithms might be used based on the data (it’s size, type, …) you have. Always read the language documentation and check the performance of the algorithms used with the underlying data structures. Different algorithms may be used based on the data (data size, type,…).
One-Dimensional Arrays One-dimensional array
The array is the most fundamental, the most commonly used data structure across all programming languages. The support for one-dimensional arrays is generally built directly into the core language itself. Arrays are the most basic and commonly used data structure in all programming languages. Support for one-dimensional arrays is usually built directly into the core language itself.
An array is an ordered collection of items, where each item inside the array has an index. An array is an ordered collection of items, and each item in the array has an index.
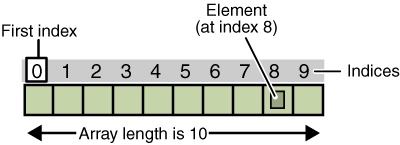
Indexes Index
The indexes are in order, they are zero-based index in most languages, but, that’s not the case with other few languages. Indexes are sequential, in most languages they are zero-based indexes, but in a few other languages this is not the case.
Size sizeThe simplest arrays are fixed size, also called immutable, meaning unchangeable arrays. They can be created initially at any size. But once the array is created, you can’t add or remove elements from it.
The simplest array is a fixed size, also known as an immutable array, meaning an array that cannot be changed. They can be initially created in any size. But once the array is created, elements cannot be added or removed from it.
Sometimes the ability to dynamically add or remove elements from it while the program is running is made available in the standard array in a language, and sometimes you have multiple different array types, depending on whether you need a fixed or resizable array. Sometimes the ability to dynamically add or remove elements while your program is running is available in the language’s standard arrays, and sometimes you can use several different array types, depending on whether you need a fixed array or a resizable array.
Data Type Data type
Simple arrays are typically restricted to a specific type of data. It’s an array of integers, or an array of booleans. But some languages allow you to create arrays of just generic objects, meaning you could put different data types. Simple arrays are usually limited to specific types of data. It is an array of integers, or an array of booleans. But some languages allow creating arrays of generic objects, which means different data types can be placed.
array = [123, true, "string", [1,2,3], object]
Multidimensional Arrays Multidimensional array
Taking the one dimensional array one step further, we can have arrays with two dimensions. Taking the one-dimensional array further, we can get a two-dimensional array.
It’s basically an array of arrays, where each item in this array itself contains another array. It is essentially an array of arrays, with each item in the array itself containing another array.
Therefore, any single array element is not accessed with just one index, but we need two numbers to get to it. Sometimes referred to as a matrix or a table because this is, effectively, rows and columns of information. Therefore, any single array element cannot be accessed with just one index, but two numbers are required to access it. Sometimes called a matrix or table because this is actually the rows and columns of information.
We can take the two-dimensional array further to three-dimensional arrays and even more. We can further develop two-dimensional arrays into three-dimensional arrays, and even more.
Jagged Arrays Jagged array
When we have a Multidimensional array, where each row, each item needs to have different number of items. It’s where Jagged arrays come into play. When we have a multidimensional array, each row and each item needs to have a different number of items. This is where jagged arrays come into play.
It’s a Multidimensional array where each item can have different sizes. is a multidimensional array, each entry can be of different sizes.
 Rows have different number of stones
rows with different numbers of stones
Rows have different number of stones
rows with different numbers of stones
When To Use Jagged Arrays When to use jagged arrays
If you have a multidimensional array which records the number of sales every day. The first index is for the month, while the second is for the day. If you have a multidimensional array recording daily sales. The first index is for the current month, and the second index is for the current day.
sales = [[124,153,135, …], [135,545,342,678,], …]
You can notice that Jan has 31 days, while Feb 29, and so on. So, either leaving the irrelevant elements empty, or setting them to 0 or -99 or some other value is not always desirable. But, you shouldn’t have elements that represent impossibilities. Like In February, where days 30 & 31 don’t exist. You can notice that January has 31 days, while February has 29, and so on. Therefore, it is not always advisable to keep irrelevant elements empty, or set them to 0 or -99 or other values. However, you should not have elements that represent the impossible. For example, in February, 30 and 31 days do not exist.
So, Using Jagged Arrays, we can get the average of sales in a month by grabbing all the sales in that month, add them all, and divide by the number of days in that month, without having to add logic to figure out the days we should be ignoring. So, using a jagged array, we can get the average sales for a month by grabbing all the sales for the month, adding them up, and then dividing by the number of days in the month, without adding logic to calculate the number of days that should be ignored.
Resizable Arrays Resizable arrays
Most languages provide some kind of resizeable array, or dynamic array, or mutable. In Java, the standard array is fixed-size and a fixed data type, but, you can also create a resizeable array using ArrayList. Most languages provide some sort of adjustable, dynamic, or mutable array. In Java, standard arrays are of fixed size and fixed data type, however, you can also create resizable arrays using ArrayList.
Adding & Removing Adding and Removing
The location where we add a new element or remove an existing one does matter, because adding or removing an element at the end is faster than at some where else. The position where you add a new element or remove an existing element does matter, as adding or removing elements at the end is faster than elsewhere.
So, elements will have to be shifted to the left or to the right, and re-indexed; re-ordered. Therefore, it does have a performance impact. Therefore, the element must be moved left or right and re-indexed; the item must be re-ordered. So it does have an impact on performance.
The way of shifting, differs from language to another, some will be shifting items in place, but, some other will just copy the entire contents of the old array into a new one with the item being added or removed. The way the conversion works, depending on the language, some will move the items in place, however, some will just copy the entire contents of the old array into a new array, adding or removing items at the same time.
Sorting Arrays Sorting arraySorting is always computationally intensive, you might need to do it but we want to minimize it. So, keeping aware about how much data we have and how often we’re asking to sort might lead us into choosing different data structures.
Sorting is always computationally intensive, you may need to do this but we want to minimize it. Therefore, understanding how much data we have and how often we require sorting may lead us to choose a different data structure.
 Sorting people by height —pleacher.com
Sort by height
Sorting people by height —pleacher.com
Sort by height
The Built-In Sorting Functionality The built-in sorting function
When we’re sorting arrays, there are things you need to understand the built-in sort functionality. When we sort an array, you need to know about the inbuilt sorting functionality.
Second, Is the built-in sort functionality will attempt to sort an existing array in place or will create another copy?. Most languages will attempt to sort an existing array in place, while a few will create new copy of the original array to contain the sorted array. Second, does the built-in sort function attempt to sort the existing array, or create another copy? Most languages will attempt to sort the existing array, while a few will create a new copy of the original array to contain the sorted array.
Sorting Custom Objects Sorting custom objects
In object oriented languages, you often have arrays of your own custom objects, not just arrays of simple numeric or even string values. In object-oriented languages, you usually have your own array of custom objects, not just a simple array of numbers or even an array of strings.
When you then ask that array to sort those objects using the built in sort functionality in the language. It simply won’t know how to do it. Because you need to provide a little more information on which property to sort accordingly. The array is then requested to sort these objects using the sorting functionality built into the language. It simply doesn’t know how to do it. Because you need to provide more information about the corresponding sorting properties.
So, for example, sort the users by their id, name, or birth date. This defines the object’s property to sort accordingly. For example, sort users by their id, name, or date of birth. This defines the properties of the object to sort accordingly.
Usually only needs a few lines and it’s typically called a comparator, or compare function, or compare method. Usually only a few lines of code are required and are often called comparators, comparison functions, or comparison methods.
##Searching Arrays Search array
If we wanted to know if a specific value exists somewhere in an array or not, we could loop over array elements, and check the value at that current position, and see if it’s equal to goal or not. If we want to know if a specific value exists in the array, we can loop through the array elements and check the value at the current position to see if it is equal to the goal.
 Keep searching even under the bed
Keep looking even under the bed
Keep searching even under the bed
Keep looking even under the bed
The best case scenario is that the first element is the value we’re looking for. The worst case is that the value is at the end or does not appear anywhere in the array. This method is referred to as a linear search or a sequential search. This is an inelegant brute-force method. Best case scenario, the first element is the value we are looking for. The worst case scenario is that the value appears at the end of the array or not anywhere in the array. This method is called linear search or sequential search. This is an inelegant brute force method.
While linear searches are simple to understand and they are easy to write and they will work, but, they’re slow. And the more elements you have, the slower they get. Although linear searches are easy to understand, easy to write, and they work, however, they are slow. The more elements there are, the slower it is.
Data Needs To Be Ordered Need to sort the data
If there is no order, no predictable sequence to the values in the array, then, there may be no other options than check all the array elements. If the values in the array have no order, no predictable sequence, then there may be no option other than checking all array elements.
So, data must be ordered in a way so that we can use an algorithm other than linear search. Therefore, having some kind of order to those elements is more and more significant. Therefore, the data must be sorted in some way so that we can use algorithms other than linear search. Therefore, it becomes increasingly important to sort these elements
The Inherit Challenge of Data Structures The inheritance challenge of data structures
You may sometimes agree to use a slow search ability, because the only way of fixing that is to sort the array, which in turn will add a performance hit that it’s simply not worth it. Sometimes you may agree to use a slow search function because the only way to solve the problem is to sort the array, which in turn adds a performance penalty that is simply not worth it.
So, If you are going to search on an array once, It’s better to have a complexity of O(N) for linear search, than O(NLogN) for sorting + O(LogN) for searching. If, however, you are going to search a lot, then, you may first sort the array once at the beginning, and now, you can search with O(LogN) every time instead of linear search O(N). So, if you were to search once on an array, it would be O(N) more complicated for a linear search than O(NLogN) sorting + O(LogN). However, if you are going to do a lot of searches, then you can first sort the array once at the beginning, and now you can search with O(LogN) each time instead of O(N) with a linear search.You cannot have a data structure that is equally good in all situations. A naturally sorted data structure requires less time in searching for an element, and more time in inserting because it keeps the array sorted. While a basic array requires more time in searching, and less time in inserting elements to the end of the array. You can’t have a data structure that is equally good in all situations. A naturally ordered data structure requires less time to search for elements and more time to insert because it maintains the ordering of the array. While basic arrays require more searching time, inserting elements at the end of the array takes less time
##Lists list
Lists are pretty simple data structures. It’s structure keeps track of sequence of items. Lists are very simple data structures. It’s structured to keep track of the order of items.
It’s a collection of items (called nodes) ordered in a linear sequence.
它是按线性顺序排列的项(称为节点)的集合。
These nodes don’t need to be allocated next to each other in the memory like an array is. The nodes do not need to be allocated adjacently in memory like arrays.
There is a general theoretical programming concept of a list, and there is the specific implementation of a list data structure, which may have taken this basic list idea and added a whole bunch of functionality. Lists are implemented either as linked lists (singly, doubly, circular, …) or as dynamic array. There’s a general theoretical programming concept of lists, and there’s a specific implementation of a list data structure that probably takes this basic list concept and adds a bunch of functionality. Lists can be implemented as linked lists (singly linked lists, double linked lists, circular linked lists, circular linked lists) or as dynamic arrays.
An Array Vs A List Array Vs List
A list is a different kind of data structure from an array. Lists are a different data structure than arrays.
The biggest difference is in the idea of direct access Vs sequential access. Arrays allow both; direct and sequential access, while lists allow only sequential access. And this is because the way that these data structures are stored in memory. The biggest difference is the concept of direct access and sequential access. Arrays allow both; direct and sequential access, whereas lists allow only sequential access. This is because of the way these data structures are stored in memory.
The structure of the list doesn’t support numeric index like an array is. The structure of a list does not support numerical indexing like an array.
##Linked Lists Linked List
It’s a collection of nodes, where each node has a value and a link to the next node in the list.
它是节点的集合,每个节点都有一个值和到列表中下一个节点的链接。
The pointer of the last node points to NULL, or terminator, or a dummy node. The pointer of the last node points to NULL, or terminator, or virtual node.
 Linked List — wikipedia
List of links - Wikipedia
Linked List — wikipedia
List of links - Wikipedia
Because of the way it’s built, adding, and removing elements is much, much easier than with an array. Because of the way it is built, adding and removing elements is much simpler than an array.
But, with arrays, it requires shifting to the left or to the right to keep its meaningful ordered structure. Even adding elements at the end of the array can still require reallocation of the entire array in order to store the array in a contiguous area of memory. However, with arrays, it needs to be shifted left or right to maintain a meaningful ordered structure. Even if you add an element to the end of the array, you still need to reallocate the entire array so that the array is stored in a contiguous memory area.
##Doubly Linked List Doubly linked list
What we have introduced is a linked list, But to be yet a little more specific, this is a called a “Singly Linked List”. We can also have a “Doubly Linked List”. We introduced a linked list, but to be more specific, this is a so-called “singly linked list”. We can also have a “double linked list”.
Instead of each node having a reference just to the next node, we add one more piece of data that it also has a reference to the previous node as well. So, it allows us to go forward and backward, to traverse the list in any direction. Instead of each node having only a reference to the next node, another piece of data is added that also has a reference to the previous node. So, it allows us to go forward and backward, traversing the list in any direction.
 Doubly Linked List — wikipedia
Doubly linked list - Wikipedia
Doubly Linked List — wikipedia
Doubly linked list - Wikipedia
Linked lists in most of the languages are typically implemented as doubly linked lists. In most languages, > linked lists are usually implemented as doubly linked lists.
The Singly Vs Doubly Linked List The Singly Vs Doubly Linked List
Adding operation is clearly less work in a singly linked list, because doubly linked list requires changing more links than a singly linked list. Adding a ** operation to a singly linked list is obviously less work since a doubly linked list requires more link changes than a singly linked list.
For singly linked list, we assume that we insert at the head or after some given node. For singly linked lists, we assume insertion after the head node or some given node.
In case of adding before some given node, you need to know the node before that given node, which will require you to sequentially access all the nodes until you find the node you’re looking for. If you want to add a node before a given node, you need to know the nodes before that node, which will require you to visit all the nodes sequentially until you find the node you are looking for.
Removing is simpler and potentially more efficient in doubly linked list, because in singly linked list, you need to know the node before the node to be deleted. In a doubly linked list, deletion is simpler and probably more efficient, since in a singly linked list you need to know the node before the node you want to delete.
##Circular Linked List Circular Linked ListIn a singly linked list, If the next pointer of the last node points back to the first node. Then, it’s “Circular Linked List”. And if the previous pointer of the first node points to the last node as well. Now this would be considered a “Circular Doubly Linked List”. In a singly linked list, if the next pointer of the last node points to the first node. Then there is the “circular linked list”. If the previous pointer of the first node points to the last node. Now, this would be considered a “circular doubly linked list”.

Circular Linked List — wikipedia Circular linked list - Wikipedia
It’s not common, but it can be useful for certain problems. So, if we get to the end of the list and say next, we just start again at the beginning. This is not common, but it can be useful for certain problems. So if we get to the end of the list, say next one, we start where we started.
##Stacks stack
Just like the arrays and lists, stacks and queues are also collection of items. They are just different ways we can hold multiple items. It’s last in, first out data structure, with no care about numeric indexes. Just like arrays and lists, stacks and queues are collections of items. They’re just different ways we can accommodate multiple projects. It is a last-in, first-out data structure and does not care about numerical indexes.
It’s a collection of items where we add and remove items to and from the top of the stack.
它是一个项集合,我们在堆栈顶部添加和删除项。
 Stack of dirty plates
pile of dirty dishes
Stack of dirty plates
pile of dirty dishes
Stack Implementation Stack implementation
A stack can be easily implemented either using an array or a linked list Stacks can easily be implemented with arrays or linked lists
Usage of Stacks Usage of stack
Stack is not limited to only model the real world situations (same for queues). One of the best uses for a stack in programming is when parsing code or expressions, where you need to do something like validating the correct amount of opening and closing curly braces, square brackets or parenthesis. Stack is not limited to simulating real-world situations (the same goes for queues). One of the best uses of the stack in programming is when parsing code or an expression and you need to do something like verify the correct number of opening braces, square brackets, or brackets.
The Basic Operations of Stacks The basic operations of the stack
They are: push(), pop(), & peek(). push is for pushing a new element on the top of the stack, and pop will return (and remove) the element at the top, while peek will get the element at the top without removing it. They are: push(), pop() and peek(). push is used to push a new element on top of the stack, pop will return (and remove) the top element, and peek will get the top element without removing it.
Stacks Vs Arrays Vs Linked Lists Stacks Vs Arrays Vs Linked Lists
Working with stack is simpler than working with arrays or linked lists, because there is less you can do with a stack. Using a stack is simpler than using an array or linked list because there are fewer things you can do with the stack.
This is an intentionally limited, an intentionally restricted data structure. All we do is push and pop and maybe peek. And if you’re trying to do anything else with this stack, you’re using the wrong data structure. This is an intentionally restricted data structure. All we do is push, pop, or peek. If you want to use this stack for other things, you’re using the wrong data structure.
##Queues Queue
The key difference between a stack and a queue. Stacks are last in first out (LIFO), while queues are first in first out (FIFO). And as with stacks, we should not even be thinking about numeric indexes. Key difference between stack and queue. Stacks are last-in-first-out (LIFO), while queues are first-in-first-out (FIFO). Like the stack, we shouldn’t even think about numeric indexing.
It’s a collection of items where we add items to the end and remove items from the front of the queue.
它是项的集合,我们在末尾添加项,并从队列前面删除项。
 Queue of people people in line
Queue of people people in line
Queue Implementation Queue implementation
As with stacks, a queue can be implemented either using an array or a linked list. Like a stack, a queue can be implemented using an array or a linked list.
Usage of Queues Use queues
Queues are very commonly used in concurrency situations to keep track of what tasks are waiting to be performed and making sure we take them in that order. Queues are very commonly used in concurrency situations to keep track of tasks waiting to be executed and ensure that they are processed in order.
The Basic Operations of Queues The basic operations of the queue
Just like a stack: add(), remove(), & peek(). Just like a stack: add(), remove() and peek().
Priority Queues priority queue
Some languages offer a version of a queue, called a priority queue. This allows you to arrange elements in the queue based on their priority. Some languages provide a version of a queue called a priority queue. This allows you to arrange the elements in the queue according to priority.
It’s a queue, where items with higher priority step ahead of items with lower priority in the queue.
它是一个队列,在队列中优先级较高的项先于优先级较低的项。
How Priority Queues Works How priority queues work
When you add items that have the same priority, they will queue as normal in a first in, first out order. If something comes along with a higher priority, then it will go ahead of them in the queue. When you add items with the same priority, they are queued in normal order. If something with a higher priority comes up, it will go ahead of them in the queue.
Defining The Priority Defining the priority
You can define based on what an element has higher, lower, or equal priority. This done by implementing a comparator or a compare function (as when sorting arrays), where you provide your own logic for comparing the priority between elements. You can define based on an element’s high priority, low priority, or equal priority. This can be achieved by implementing a comparator or a compare function (just like sorting an array) where you can provide your own logic when comparing priorities between elements.
##Deque double-ended queueThe deque, pronounced “DEK”, is used when we want to leverage the power of the queue and the stack, where you can add or remove from start or end. Deque is pronounced as “DEK” and we use deque when we want to take advantage of the capabilities of queues and stacks, where we can add or delete from the beginning or end.
It’s a queue and a stack at the same time.
它同时是一个队列和一个堆栈。
##Associative Arrays Associative array
They give the ability to use meaningful keys to work with elements in our data structures, rather than working with numeric indexes as keys. This gives a meaningful relationship between the key and the value. They allow elements in a data structure to be processed using meaningful keys rather than numerical indices as keys. This provides meaningful relationships between keys and values.
It is a collection of key-value pairs.
它是键-值对的集合。
var user = {
firstName: "Bob",
lastName: "Jones",
age: 26,
email: "bob.jones@example.com"
};
The implementation of associative arrays have different names. In Objective-C and Python, they’re called dictionaries. Implementations of associative arrays have different names. In Objective-C and Python, they are called dictionaries.
The Order of Elements The order of elements
Unlike a basic array, In an associative array the keys do not need to be in any specific order. Because order is not a concern in associative arrays. Unlike basic arrays, the keys in an associative array do not need to be in any specific order. Because order has nothing to do with associative arrays.
Sure, you might find it useful to sort them by key. You might find it useful to sort them by value, or, you might not need to sort it at all. Of course, you might find sorting by key useful. You may find it useful to sort them by value, or you may not need to sort them at all.
Key Duplicates Key duplicates
The same way that you don’t get the same index number appearing twice in a basic array, there can be no duplicate keys, and keys must be unique in an associative array. Likewise, the same index number cannot appear twice in a basic array, there cannot be duplicate keys, and keys must be unique in an associative array.
Keys & Values Data Types key & value data types
You can usually use any data type as either the key or the value. It is common to use a string as a key. You can generally use any data type as a key or value. Usually strings are used as keys.
Most associate arrays, whether they are called dictionaries or maps or hashes, are implemented using hash table data structure. So, we’ll start by hashing and then dive into hash tables. Most associative arrays are implemented using hash table data structures, whether they are dictionaries, maps, or hashes. So, we’ll start with hashes and then dive into hash tables.
##Hashing Hash
Hashing is a valuable concept in programming. It’s used, not just in data structures, but in security, cryptography, graphics, audio. Hashing is a valuable concept in programming. It is used not only for data structures but also for security, encryption, graphics, and audio.
It’s a way to take our data and run it through a function, which will return a small, simplified reference generated from that original data.
这是一种获取数据并通过函数运行数据的方法,函数将返回从原始数据生成的一个小的、简化的引用。
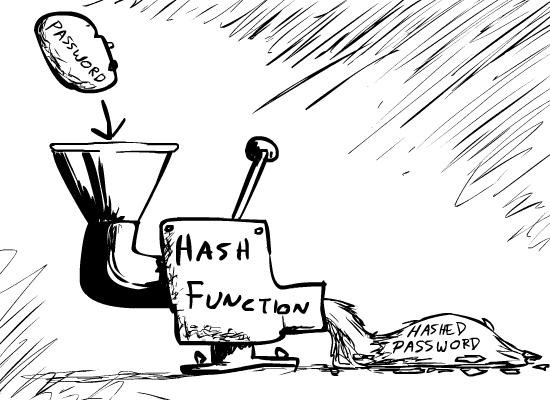 Hashing is commonly used with passwords Hashing is commonly used with passwords
Hashing is commonly used with passwords Hashing is commonly used with passwords
The reference might just be an integer, or letters and numbers, …etc. The reference might be just an integer, or letters and numbers, etc.
Why Using Hashing? Why use hashing?
Because being able to take a complex object, and hash it down to a single integer representation. So, we can use that integer value to get to a certain location in the data structure. Because you can hash a complex object to an integer representation. Therefore, we can use this integer value to reach a certain location in the data structure.
Hashing Is Not Encryption Hashing is not encryption
Hash functions are not reversible; They are one way. So, you cannot convert a hash value result back to the original data. Therefore, you lose information when hashing, that’s okay, that’s intentional. Hash functions are irreversible; they are one-way. Therefore, you cannot convert the hash result back to the original data. Therefore, information is lost during the hashing process, and this is intentional.
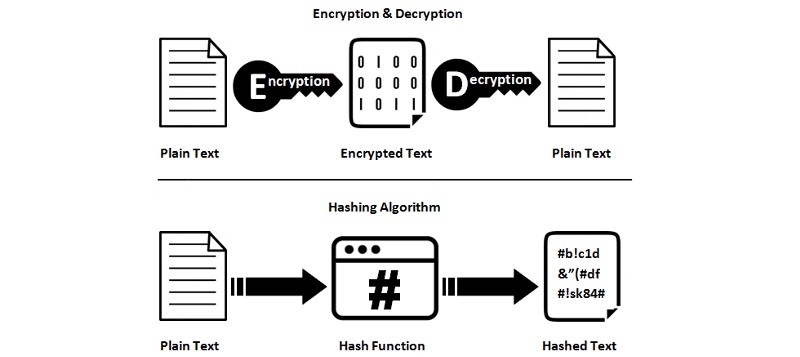 Hashing Vs Encryption — ssl2buy.com Hashing Vs Encryption — ssl2buy.com
Hashing Vs Encryption — ssl2buy.com Hashing Vs Encryption — ssl2buy.com
Hashing Function Implementation Hash function implementation
Say we have a person class defined, and we want a hash function defined on this class. The hash function should return a specific single reference (usually an an integer) for a specific person object. This single integer is generated using the data in a person object (firstname, lastname, birth date, …etc). Suppose we define a person class and we want to define a hash function on this class. The hash function should return a specific reference (usually an integer) for a specific person object. This integer is generated using the data from the person object (firstname, lastname, birthday, etc.).
Hashing Rules Hash rules
-
If we take the exact same object, with this same data, and feed it into the hash function again, I would expect the same hash result.
-
If you have two different objects that you consider equal, they should return the same hash value.
-
While two equal objects should produce the same hash value, two equal hash values does not guarantee they came from equal objects, Why? Because two different objects might, under some circumstances, deliver the same result out of a hash function (See Hashing Collision). Two equal objects should produce the same hash value, but two equal hash values are not guaranteed to come from equal objects, why? Because in some cases two different objects may pass the same result from the hash function (see hash collisions).
Hashing Collision Hash collision
It’s when we have different objects with different data, but giving the same hash value result. When we have different objects and different data, but get the same hash value.It could be because the hashing function is simple hash function, but it’s also possible even with more complex hash functions. In most cases that’s okay, we can manage the hash collision. This is probably because the hash function is a simple hash function, but even more complex hash functions are possible. In most cases this is OK and we can manage hash collisions.
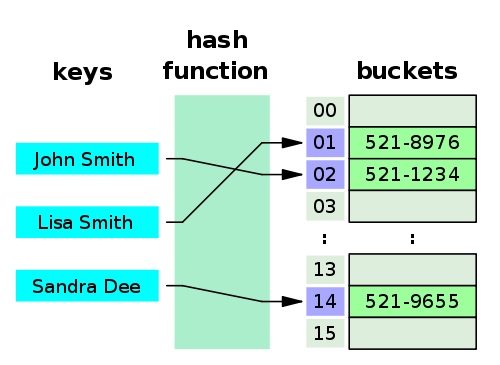
##Hash Tables Hash table
The idea of hashing was fundamental to understand the hash table data structure. The idea of hashing is the basis for understanding the hash table data structure.
It’s a typical data structure to implement an associative arrays; mapping keys to values.
实现关联数组是一种典型的数据结构;将键映射到值。
 Mapping numbers (keys) to boxes Mapping numbers (keys) to boxes
Mapping numbers (keys) to boxes Mapping numbers (keys) to boxes
Hash Tables Vs Arrays Vs Lined List Hash Tables Vs Arrays Vs Lists
The big benefit of hash tables over arrays and over linked lists is they’re very fast, both for looking at whether an item exists or finding a specific item in a hash table, and for inserting and deleting items. The biggest benefit of hash tables compared to arrays and linked lists is that they are very fast, both to see if an item exists, to find a specific item in the hash table, and to insert and delete items.
How Hash Tables Work? How do hash tables work?
 A small phone book as a hash table — Wikipedia A small phone book as a hash table — Wikipedia
A small phone book as a hash table — Wikipedia A small phone book as a hash table — Wikipedia
When a hash table is created, it’s really internally a very array-based data structure, and can usually be created with an initial capacity. The hash table consists of an array of slots, or buckets which contain the values. When a hash table is created, it is actually a very array-based data structure that can usually be created with an initial capacity. A hash table consists of an array of slots or buckets containing values.
When adding a key-value pair, It will take our key and it’ll run it through the hash function, getting a specific hash value out (usually an integer). When adding a key-value pair, it takes our key and runs it through a hash function, resulting in a specific hash value (usually an integer).
If this hash value is large, you might need to simplify it with respect to the current size of the hash table. If this hash is large, you may need to simplify it based on the current size of the hash table.
Then, it will assign the value to an array element with the index equals to the returned hash integer value. It will then assign that value to an array element with an index equal to the returned hashed integer value.
// adding a key-value pair
hash_table.add(key, value)
// what happen behind the scene
index = hash(key)
index = index % array_size
array[index] = value
Accessing a value given a key follows the same idea. It will take that key, run it through the exact same hash function, and it can then go directly to a specific location that contains the value we’re looking for. Accessing the value of a given key follows the same idea. It takes that key, runs it through the exact same hash function, and then it can go directly to a specific location that contains the value we’re looking for.
There’s no linear search, no binary search, no traversing a list. We just go straight to the element we need. No linear searches, no binary searches, no traversing lists. We get directly the element we need.
Managing Collision Management Conflict
We can expect that a hash collision will arise; when we get the same hash value for different keys. But, how to manage it? We can expect hash collisions to happen; when we get the same hash value for different keys. But, how to manage it?
When we add a new key value pair, and collision happens, It’s going to put that value in the same location, even if there’s another existing value in that location. When we add a new key-value pair, and a collision occurs, it will place that value in the same position, even if there is another existing value at that position.
Now, hash table implementations have different ways to automatically deal with this. These range from that each location contains a simple collection, like an array, or a linked list. Now, hash table implementations have different ways of handling this automatically. Each location contains a simple collection, such as an array or linked list.
So, we would still be able to get to any location very fast, but once we get to the location with multiple values, the hash table will traverse that internal list to find what we’re looking for. So we’re still able to get to any location very quickly, but once we get to a location with multiple values, the hash table goes through that internal list to find what we’re looking for.
Each node in the linked list in turn will contain the value associated with a specific key. In addition, It will contain that key, or a reference to that key. Because in case of multiple values inside the same location, we need to know which key this value belongs to. Each node in the linked list in turn contains a value associated with a specific key. Additionally, it will contain the key, or a reference to the key. Because for multiple values within the same position, we need to know which key this value belongs to.
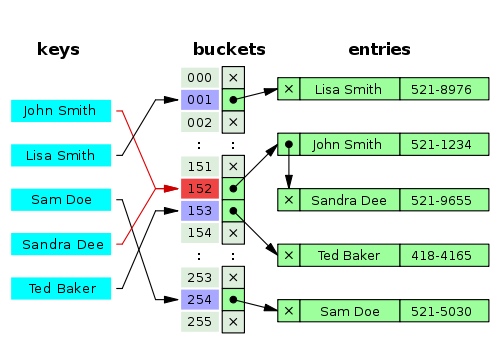 Hash collision resolved by separate chaining — wikipedia Hash collision resolved by separate chaining — Wikipedia
Hash collision resolved by separate chaining — wikipedia Hash collision resolved by separate chaining — Wikipedia
This is what is called the “Separate Chaining Technique” in hash tables. Now, there are other techniques for managing collisions inside hash tables, including open addressing, Cuckoo hashing, hop-scotch, and Robin Hood hashing. This is the “independent linking technique” in hash tables. Today, there are other techniques for managing collisions within hash tables, including open addressing, cuckoo hashing, hopscotch, and Robin Hood hashing.
Writing Hash Functions Writing Hash Functions
When you want to store key-value pairs using hash table data structure, It’s probably most of objects already have hash function. The default behavior is usually returns an integer; calculated from the memory address of that object. When you want to use a hash table data structure to store key-value pairs, probably most objects already have a hash function. The default behavior is usually to return an integer; calculated from the object’s memory address.If you ever override the equality behavior in your class, you must override the hash behavior. Because hash codes are so tied to equality, And, if you have two objects that you consider equal, they should return the same hash value. If you ever override equality behavior in a class, you must override hashing behavior. Because hash codes are very closely related to equality, and if there are two objects that you consider equal, they should return the same hash value.
Again, if you change what it means for your objects to be equal, you should also change what it means to hash these objects. Likewise, if you change the meaning of object equality, you should also change the meaning of hashing those objects.
String objects already overridden their own equality and hashing behavior. So if you have two separate string objects, they will still count as equal, and return the same hash, if they have the same value, even if they’re actually separate string objects allocated in different parts of memory. String objects have overridden equality and hashing behavior of their own. So if you have two separate string objects, they will still be equal and return the same hash if they have the same value, even though they are actually separate string objects allocated in different parts of memory.
##Sets set
When all what you need is a big container you can put a bunch of items into it, where you don’t care about the sequence. When you just need a big container, you can put a bunch of stuff in it and you don’t have to think about order.
There is no specific sequence as with a linked list, or a stack, or a queue. There is no key-value pairs as with a hash table. There is no specific sequence, such as a linked list, stack, or queue. There are no key-value pairs, just like a hash table.
It’s an unordered collection of items, with no repeated values.
它是一个无序的项目集合,没有重复的值。
By unordered, I mean there is no index like an array. Unordered means there is no index like in an array.
 A grocery bag of food A bag of food
A grocery bag of food A bag of food
Set Implementation Set implementation
Sets are actually use the same idea of hash tables data structure most of the time. But, instead of key-value pairs (hashing a key and store it’s value), when you’re using a set, the key is also considered as the value (or the value is assigned to a dummy or a default value). Collections actually use the same idea of a hash table data structure in most cases. However, unlike key-value pairs (where the key is hashed and its value is stored), when working with collections the keys are also considered values (or the values are assigned to dummy or default values).
So, to get any specific value, or any specific object in the set, you need to have the object itself. And the only reason to do this is to check for it’s existence. This is often referred to as “checking membership”. So, to get any specific value in the collection, or any specific object, you need the object itself. The only reason to do this is to test whether it exists. This is often called “checking membership.”
Sets can be implemented using a self-balancing binary search tree for sorted sets, or a hash table for unsorted sets. Sorted sets can be implemented using self-balancing binary search trees, or unsorted sets can be implemented using hash tables.
The Advantage of Sets The advantages of sets
Unlike an array, or values in an associative array, or a linked list, sets do not allow duplicates. You cannot add the same object, the same value twice to the same set. Unlike values in arrays, associative arrays, or linked lists, sets do not allow duplicates. The same object and the same value cannot be added to the same collection twice.
Sets are designed for very fast lookup, to very quickly be able to see if we already have a value contained in a collection. Collections are designed for fast lookups, so that you can very quickly see if a value is already contained in the collection.
You can also iterate through all the elements in a set, you just may not have any guaranteed order. You can also iterate over all elements in a collection, and you may not have any guaranteed ordering.
##Trees tree The idea of a tree data structure is that we have a collection of nodes, and the nodes have connections, they have links between each other. The concept of a tree data structure is that we have a set of nodes, and these nodes have connections, and there are links between them.
This sounds similar to linked lists. But in a linked list, we always go from one node to a single specific next node. While in a tree, each node might link to one, or two, or more nodes. This sounds similar to a linked list. But in a linked list, we always go from one node to a specific next node. In a tree, each node may be linked to one, two, or more nodes.
It’s a collection of nodes, where each node might link to one, or two, or more nodes.
它是节点的集合,每个节点可能链接到一个、两个或多个节点。
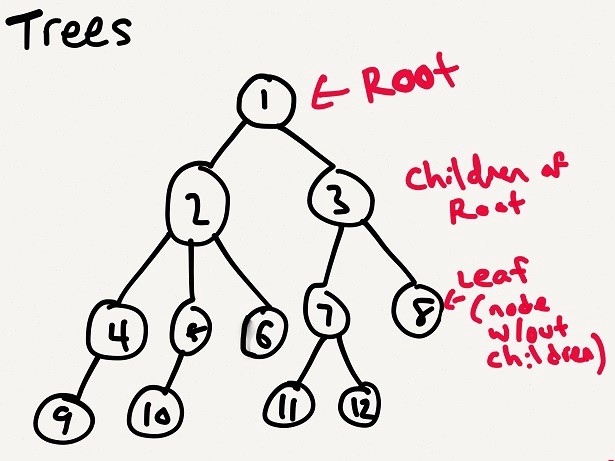 A Tree - richardkho.com
A Tree - richardkho.com
Tree Terminologies Tree terminology
There are some terminologies that come with the tree. You can find more about them here. They are essential to understand and work with trees. There are a few terms that come with this tree. You can find more information about them here. They are essential to understanding and studying trees.
Binary Trees Binary Tree
A binary tree is just a tree with maximum of two child nodes for any parent node. Binary trees are often used for implementing a wonderfully searchable structure called a “Binary Search Tree” or “BST”. A binary tree is a tree with at most two child nodes for any parent node. Binary trees are often used to implement a fancy searchable structure called a “binary search tree” or “BST”.
##Binary Search Trees (BST) Binary Search Tree (BST)
It’s a specific type of binary tree, where the left child node is less than its parent, and a right child node is greater than its parent.
它是一种特定类型的二叉树,其中左子节点小于其父节点,而右子节点大于其父节点。
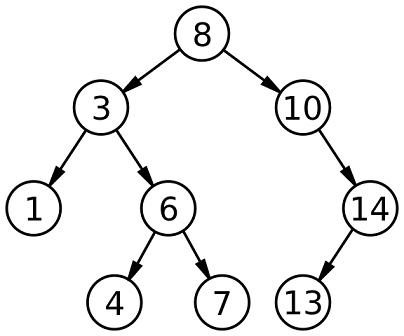 A Binary Search Tree (BST) — Wikipedia A Binary Search Tree (BST) - Wikipedia
A Binary Search Tree (BST) — Wikipedia A Binary Search Tree (BST) - Wikipedia
How Binary Search Trees Work? How do binary search trees work?
The rule is that the left child node must be less than its parents, and a right child node must be greater than its parents, and that rule follows all the way down in the tree. The rule is that the left child node must be smaller than its parent node, and the right child node must be larger than its parent node, and this rule continues down the tree.And as we insert new nodes with values, the rule will always be followed to make sure that the tree stays sorted. When we insert a new node with a value, rules will always be followed to ensure that the tree remains sorted.
So, It is a data structure that naturally stays sorted and it’s sometimes called “A Sorted Tree” or “An Ordered Tree”. Therefore, it is a data structure that naturally maintains ordering, and is sometimes called a “sorted tree” or “ordered tree”.
Storing Nodes As Key-Value Pairs Storing nodes as key-value pairs
A binary search trees are often used to store key value pairs, meaning, the nodes consists of a key, and an associated value. And it’s the key that would be used to sort the nodes accordingly in a binary search tree. Binary search trees are typically used to store key-value pairs, that is, nodes consist of a key and an associated value. This is the key to ordering nodes in a binary search tree.
Duplicates
You can’t have duplicate keys, just as you don’t have duplicate keys in a hash table or even an array. There can’t be duplicate keys, just like there can’t be duplicate keys in a hash table or even an array.
Adding & Accessing Nodes Adding and accessing nodes
Adding & Accessing nodes follows the same rule mentioned above. If the current node is less than, then go right, if greater than, go left. Adding and accessing nodes follows the same rules as above. If the current node is smaller, go to the right, if greater, go to the left.
Retrieve Nodes In Order Retrieve nodes in order
The other benefit is binary search trees are staying sorted. So, If we retrieve the items from a left to the right, bottom to top, we will get them all out in order. Another benefit is that binary search trees maintain ordering. So, if we retrieve the items from left to right and bottom to top, we will get them in order.
Unbalanced Tree Unbalanced tree
It’s when the tree has more levels of nodes on the right hand side than on the left (or vice-versa). When there are more nodes on the right side of the tree than on the left (and vice versa).
Although it’s unusual for this kind of thing to happen, but, we can’t always guarantee that the way data is added will allow us to build a tree with a perfectly symmetrical structure all the way down. Although this rarely happens, we can’t always guarantee that we add data in a way that allows us to build a tree with a completely symmetric structure.
In this case we say that our tree is unbalanced; There are more levels on one side than on the other. And we would have to perform more checks to find or insert or delete any values on the right hand side than we would on the left (or vice-versa). In this case, we say the tree is unbalanced; one side has more energy levels than the other. We need to perform more checks to find, insert, or delete any value to the right than to the left (or vice versa).
Binary Search Tree Implementations Implementation of binary search tree
What we have been talking about is the abstract idea of a binary search tree data structure. But, there are several implementations of this binary search tree idea that are self-balancing binary search trees. What we have been discussing is the abstract idea of a binary search tree data structure. However, there are several implementations of this binary search tree idea that are self-balancing binary search trees.
The important idea with balancing a binary search tree is that the number of levels are roughly equal to each other. We don’t have three levels on the left and twenty on the right. The important idea in balancing a binary search tree is that the number of levels is approximately equal. There are no three floors on the left and no twenty floors on the right.
Examples of self-balancing trees could be: Red-Black, AVL or Adelson-Velskii and Landis’, Splay, Scapegoat trees, and more. Examples of self-balancing trees can be: red-black trees, AVL or Adelson-Velskii and Landis’, Splay trees, scapegoat trees, etc.
Binary Search Tree Vs Hash Table Binary Search Tree Vs Hash Table
Both are fast for insertion, fast for deletion, fast for accessing any element even at large sizes. But, because binary search trees stay sorted, they allow us to get all the items out of the tree in order, where the hash table doesn’t guarantee a specific order. Both methods provide fast insertion, fast deletion, and fast access to any element, even large ones. However, since binary search trees maintain ordering, they allow us to take all items out of the tree in order, whereas hash tables cannot guarantee a specific order.
##Heaps heap Heaps are usually implemented using the idea of a binary tree, not a binary search tree but still, a binary tree. They’re a way of implementing other abstract data types like the priority queue. The heap is usually implemented using the idea of a binary tree, not a binary search tree, but a binary tree. They are a way to implement other abstract data types such as priority queues.
It’s a specific type of binary tree, where we add nodes from top to bottom, left to right, and child nodes must be less (or greater) than or equal their parents.
这是一种特定类型的二叉树,我们从上到下、从左到右添加节点,子节点必须小于(或大于)或等于它们的父节点。
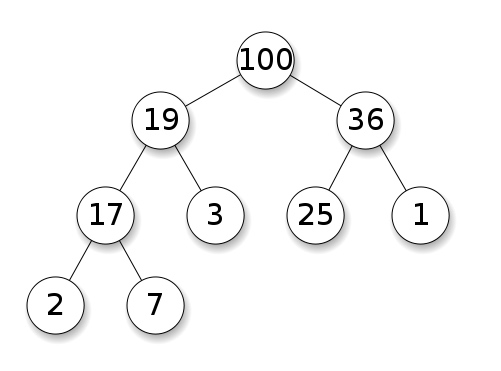 Max Heap - Wikipedia The largest heap - Wikipedia
Max Heap - Wikipedia The largest heap - Wikipedia
Therefore, we completely fill out any level before moving on to the next. So we don’t have to worry about the tree becoming unbalanced like a binary search tree can. So we will completely fill any level before moving on to the next level. So we don’t have to worry about the tree becoming unbalanced like a binary search tree.
Min Vs Max Heap
A min heap states that any child node must be greater than (or equal) its parent node, while a max heap states that any child node must be less than (or equal) its parent node. However, we don’t care if a node is less than or greater than it’s sibling. Min-heap states that any child node must be greater than (or equal to) its parent node, while max-heap states that any child node must be less than (or equal to) its parent node. However, we don’t care if a node is smaller or larger than its siblings.
How Heaps Work? How does the heap work?
So, In case of Min Heap: So, for a min-heap:1. We keep adding elements from top to bottom, left to right 2. Then, compare with the parent node; Is it less than its parent? Then, compare with the parent node; Is it less than its parent? 3. If so, then swap the node with it’s parent, 4. Keep doing steps from 2 through 3 until the node is greater than it’s parent (or it becomes the root node). as shown. Keep executing steps from 2 to 3 until the node is larger than its parent (or it becomes the root node).
This little swapping of nodes is how a heap keeps itself organized. This small node swapping is how the heap keeps itself organized.
Heap Is Not A Fully Sorted The heap is not completely sorted
Unlike a binary search tree, which does stay sorted, and where we can easily traverse the tree and retrieve everything out in order. Unlike binary search trees, which maintain ordering, we can easily traverse the tree and retrieve everything in order.
Because if you notice, that at any particular level past the root, the values do not have to be in any specific order, just as long as they’re all greater (or less) than their parent. Because if you notice, at any particular level after the root, the values don’t have to appear in any particular order, as long as they are all greater (or less) than their parent.
One of the benefits of this is a heap does not have to do as much reorganization of itself as may be necessary with a binary search tree. One benefit of this is that the heap doesn’t have to reorganize itself as much as it does with a binary search tree.
The one thing we can be sure about, is that the parent node will always be less or greater than it’s child nodes, and hence the minimum or the maximum value will be always at the top. One thing we can be sure of is that a parent node is always smaller or larger than its children, so the minimum or maximum value is always at the top.
And, therefore, heaps are most useful for the idea of a priority queue. Therefore, the heap is most useful for the concept of priority queues.
##Graphs Graphs
The limitations of a tree are no longer exist here. A node can link to multiple other nodes, no specific sequence, no root node. The limitations of trees no longer exist. A node can be linked to multiple other nodes in no particular order and without a root node.
It’s a collection of nodes, where a node can link to multiple other nodes, no specific sequence, no root node. It is a collection of nodes where one node can be linked to multiple other nodes, in no particular sequence, and without a root node.
 A graph of a social network
Social network diagram
A graph of a social network
Social network diagram
Graph Theory In Mathematics Graph Theory in Mathematics
Because graphs in computer science are so closely linked to graph theory in mathematics. It is common to hear mathematical terms used. So, In graph theory, we call the nodes “vertices”, and the links between them are referred to as “edges”. Because graphics in computer science and graphics theory in mathematics are closely linked. It is very common to use mathematical terms. Therefore, in graph theory, we call nodes “vertices” and the links between them “edges”.
Graphs Usage Graph usage
We could use a graph to model a social network with each node a person. Or, modeling the distances between cities. We could model a ethernet network in an office, or in an entire building, or a city. We can use a graph to model a social network with nodes for each person. Alternatively, model the distance between cities. We can model an Ethernet network in an office, an entire building, or a city.
Direct & Undirect Graphs Direct and indirect graphs
We can also say whether those edges should have a direction to them or not. We can also say whether these edges should have a direction.
In some situations, it makes sense that any edge, any connection between two vertices, is only one-way; So, node A is connected to node B, while the reverse is not true; node B is NOT connect to node A. In some cases, any edge, any connection between two vertices, is one-way; therefore, node A is connected to node B, but not vice versa; node B is not connected to node A.
In other situations, you might want to be able to follow that edge, that link, in either direction; So, node A is connected to node B, and also node B is connected to node A. In other cases, you might want to follow this edge, this link, in any direction; node A connects to node B, and node B connects to node A.
Weighted Graphs Weighted graph
You can also give every edge a weight; associating a number, with each of the edges. You can also give each edge a weight; associate a number with each edge.
You could do this to represent, say, the distances between cities, if you were trying to calculate the shortest route between multiple locations. Or, you could use a weight to indicate which edges take priority over other edges. You could represent, say, the distance between cities if you wanted to calculate the shortest route between multiple locations. Alternatively, you can use weights to indicate which edges are preferred over others.
##Abstract Data Types (ADTs) abstract data types (adt)
Before diving into the abstract data types, what they are, and the difference between them and other concepts. Let’s define what’s meant by a data type. Before we delve into abstract data types, let’s understand what they are and how they differ from other concepts. Let’s define what data types mean.
Data Type Data type
A variable’s data type determines the values it may contain, plus the operations that may be performed on it.
Data Types consists of: Primitive, Complex or Composite, and Abstract Data Types. Data types include: basic data types, complex data types or composite data types, and abstract data types.
An Abstract Data Type (ADT) Abstract Data Type (ADT)It’s a data type, just like integers and booleans primitive data types. An ADT consists not only of operations, but also of values of the underlying data and of constraints on the operations.
It is a data type, just like the integer and Boolean primitive data types. ADT contains not only operations, but also the values of the underlying data and constraints on operations.
A constrains for a stack would be that each pop always returns the most recently pushed item that has not been popped yet. The constraint of the stack is that each pop always returns the most recently pushed item that has not yet been popped.
The actual implementation for an ADT is abstracted away, and we don’t have to care about. So, how a stack is actually implemented is not that important. A stack could be and often is implemented behind the scenes using a dynamic array, but it could be implemented with a linked list instead. It really doesn’t matter. The actual implementation of ADT is abstract and we don’t need to care. So, it doesn’t matter how the stack is implemented. Stacks can and usually are implemented using dynamic arrays under the hood, but they can also be implemented using linked lists. It really doesn’t matter.
Lists, stacks, queues, and more are all abstract data types. Lists, stacks, queues, etc. are all abstract data types.
An Abstract Data Type & Data Structure Abstract data type and data structure
ADT is not an alternative to a data structure, they are different concepts. ADT is not a replacement for data structures, they are different concepts.
When we say the stack data structure, we refer to how stacks are implemented and arranged in the memory. But, when we say the stack ADT, we refer to the stack data type which has set of defined operations, the operations constrains, and the possible values. When we talk about stack data structure, we are referring to how the stack is implemented and arranged in memory. However, when we say stack ADT, we mean a stack data type that has a defined set of operations, operation constraints, and possible values.
We don’t care about the underlying implementation, same as when using integers, we are abstracted away from how integers are represented in the memory, we are only interested in the operations (add, subtract, …), and the possible values (…, −2, −1, 0, 1, 2, …). We don’t care about the underlying implementation, as when working with integers, we break away from the representation of integers in memory, we are only interested in the operations (addition, subtraction, …), and the possible values (…−2−1,0,1,2,…).
Data structures can implement one or more particular abstract data types (ADT), which specify the operations that can be performed on a data structure. A data structure can implement one or more specific abstract data types (ADTs), which specify the operations that can be performed on the data structure.
An Abstract Data Type Is NOT An Abstract Class An Abstract Data Type Is NOT An Abstract Class
Both have nothing to do with each other. An abstract class defines only the operations, sometimes with comments that describe the constraints, leaving the actual implementation to the inheriting classes. Neither has anything to do with the other. Abstract classes only define operations, sometimes with annotations describing constraints, leaving the actual implementation to inheriting classes.
Although ADTs are often implemented as Interfaces (abstract classes) as in Java. For example, The List interface in Java defines the operations of the List ADT, while the inheriting classes define the actual implementation (data structure). While adts are usually implemented as interfaces (abstract classes), like in Java. For example, the List interface in Java defines the operations of the List ADT, while inherited classes define the actual implementation (data structure).
But, this is not always the case. For example, Java has a stack class, It is a regular concrete class, but a stack is also an abstract data type, meaning, it represents the idea of having a last in, first out data structure. So, stack is a real concrete class and it’s also an abstract data type. But this is not always the case. For example, Java has a stack class, which is a regular concrete class, but the stack is also an abstract data type, that is, it represents a last-in-first-out data structure. Stack is a concrete class and an abstract data type.
An Abstract Data Types Is A Theoretical Concept An abstract data type is a theoretical concept
An abstract data type (ADT) is a theoretical concept that’s irrelevant to programming keywords. Abstract data type (ADT) is a theoretical concept that has nothing to do with programming keywords.
So, If we have a stack, we have a last in, first out data structure, that we can push and pop and peek. That’s what we expect a stack to be able to do. Whether a stack is implemented as a concrete class or whatever, It still have the idea of a last in, first out data structure. So, if we have a stack, we have a LIFO data structure that we can push, pop and peek at. This is what we expect the stack to do. Regardless of whether the stack is implemented as a concrete class, or something else, it still has the concept of a last-in-first-out data structure.
##Conclusion Conclusion
Deciding on The Data Structure Determining the data structure
There are some key questions you need to ask before deciding on the data structure Before deciding on a data structure, you need to ask some key questions
- How much data do you have? How much data do you have?
- How often does it change? How often does it change?
- Do you need to sort it, do you need to search it? Faster to Access, Insert, or Delete? Faster to Access, Insert, or Delete?
If any place where you only have trivial amounts of data, it isn’t going to matter very much. Unless of course, those amounts of data change so frequently, or you have large amounts of data. If there’s only a small amount of data anywhere, it doesn’t matter. Unless, of course, these data volumes change very frequently, or you have a lot of data.### Immutable Data Structures Immutable data structures Now, a general principle that immutable or fixed size data structures tend to be faster and smaller in memory than mutable ones. Now, a general principle is that immutable or fixed-size data structures tend to be faster and smaller in memory than mutable structures.
Why should we restrict the features of arrays? The reason is, that the more constraints you have (like fixed size, specific data type, …), the faster and smaller your data structure is able to be. Why limit the characteristics of arrays? The reason is that the more constraints (such as fixed size, specific data type…), the faster and smaller the data structure will be.
The pitfalls of having a data structure with many features (non-restricted) is the compiler cannot allocate the ideal amount of space, therefore, it must introduce overhead to support the flexibility of the data structure (like different data types, …). The drawback of data structures with many features (unrestricted) is that the compiler cannot allocate an ideal amount of space, and therefore, it must introduce overhead to support the flexibility of the data structure (like different data types, …).
Improve Your Code Performance Improve code performance
If you’re looking at existing code to see what to improve on, then see whatever holds the most data. There is no better way to really get the most out of these data structures than when you see some of the performance improvements you can get, just from simply changing from one structure to another. If you’re looking at existing code to see where you need improvement, look at where the most data is being saved. When you see that you can get some performance improvements by simply changing from one structure to another, there’s no better way to really get the most out of these data structures.
Differences In Languages Differences in languages
The algorithms used with each data structure differs from one language to another, and the actual implementation of the data structure differs from one language to another. So, It’s worth to look closely at your language documentation. The algorithms used by each data structure vary from language to language, and the actual implementation of the data structure varies from language to language. Therefore, it is necessary to carefully review your language documentation.
What to read next
Want more posts about Algorithms?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Algorithms?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home