Exposing NSDictionary
Research on the underlying implementation of NSDictionary
Expose NSDictionary
Hash tables are just awesome. To this day I find it fascinating that one can fetch an object corresponding to an arbitrary key in a constant time. Although iOS 6.0 introduced an explicit hash table, it is NSDictionary that’s almost exclusively used for associative storage. Hash tables are great. To this day, I still find it very interesting to get the object corresponding to any key in a fixed period of time. Although iOS 6.0 introduced explicit hash tables, NSDictionary is used almost exclusively for associative storage.
NSDictionary doesn’t make any promise of its internal implementation. It would make little sense for a dictionary to store its data in a completely random fashion. However, this assumption doesn’t answer the key question: does NSDictionary make use of a hash table? This is what I’ve decided to investigate. NSDictionary makes no promises about its internal implementation. It doesn’t make sense for a dictionary to store data in a completely random way. However, this assumption doesn’t answer the key question: does NSDictionary use a hash table? That’s what I decided to investigate.
Why not to tackle the full featured NSMutableDictionary? A mutable dictionary is, understandably, much more complex and the amount of disassembly I would have had to go through was terrifying. Regular NSDictionary still provided a nontrivial ARM64 deciphering challenge. Despite being immutable, the class has some very interesting implementation details which should make the following ride enjoyable. Why not just deal with a full-featured NSMutableDictionary? Understandably, a mutable dictionary is much more complex, and the amount of factoring I’d need to do would be horrendous. Plain NSDictionary still presents a significant ARM64 decoding challenge. Although this class is immutable, it has some very interesting implementation details that should make the process below enjoyable.
This blog post has a companion repo which contains discussed pieces of code. While the entire investigation has been based on the iOS 7.1 SDK targeting a 64-bit device, neither iOS 7.0 nor 32-bit devices impact the findings. This blog post has an accompanying repo containing the code snippets discussed. While the entire investigation was based on the iOS 7.1 SDK for 64-bit devices, neither iOS 7.0 nor 32-bit devices affected the findings.
The Class class
Plenty of Foundation classes are class clusters and NSDictionary is no exception. For quite a long time NSDictionary used CFDictionary as its default implementation, however, starting with iOS 6.0 things have changed: Many basic classes are class clusters, and NSDictionary is no exception. For quite some time, NSDictionary used CFDictionary as its default implementation, however, starting with iOS 6.0, things have changed:
(lldb) po [[NSDictionary new] class]
__NSDictionaryI
Similarly to __NSArrayM, __NSDictionaryI rests within the CoreFoundation framework, in spite of being publicly presented as a part of Foundation. Running the library through class-dump generates the following ivar layout: Like __NSArrayM, __NSDictionaryI lives within the CoreFoundation framework, although it is exposed publicly as part of Foundation. Running the library through a class dump produces the following ivar layout:
@interface __NSDictionaryI : NSDictionary
{
NSUIngeter _used:58;
NSUIngeter _szidx:6;
}
It’s surprisingly short. There doesn’t seem to be any pointer to either keys or objects storage. As we will soon see, __NSDictionary literally keeps its storage to itself. It’s surprisingly short. There don’t seem to be any pointers to keys or object storage. As we will see shortly, __NSDictionary literally holds its storage.
The Storage Storage
Instance Creation instance creation
To understand where __NSDictionaryI keeps its contents, let’s take a quick tour through the instance creation process. There is just one class method that’s responsible for spawning new instances of __NSDictionaryI. According to class-dump, the method has the following signature: To understand where the contents of __NSDictionaryI are saved, let’s take a quick look at the instance creation process. There is only one class method responsible for generating new instances of __NSDictionaryI. According to class-dump, this method has the following characteristics:
+ (id)__new:(const id *)arg1:(const id *)arg2:(unsigned long long)arg3:(_Bool)arg4:(_Bool)arg5;
It takes five arguments, of which only the first one is named. Seriously, if you were to use it in a @selector statement it would have a form of @selector(__new:::::). array of objects and number of keys (objects) respectively. Notice, that keys and objects arrays are swapped in comparison to the public facing API which takes a form of:
It takes five parameters, only the first of which is named. Seriously, if you use it in a @selector statement, it will have the form @selector(__new:::::). The first three parameters can be easily deduced by setting a breakpoint on the method and snooping into the contents of the x2, x3, and x4 registers containing the key array, object array, and key count (object) respectively. Note that keys and object arrays are swapped compared to the public facing API which takes the form:
+ (instancetype)dictionaryWithObjects:(const id [])objects forKeys:(const id <NSCopying> [])keys count:(NSUInteger)cnt;
It doesn’t matter whether an argument is defined as const id * or const id [] since arrays decay into pointers when passed as function arguments.
It doesn’t matter whether the parameter is defined as const id * or const id[], as the array will decay to a pointer when passed as a function argument.With three arguments covered we’re left with the two unidentified boolean parameters. I’ve done some assembly digging with the following results: the fourth argument governs whether the keys should be copied, and the last one decides whether the arguments should not be retained. We can now rewrite the method with named parameters:
With three parameters, we are left with two unidentified boolean parameters. I did some digging around the assembly and here’s what I found: the fourth parameter controls whether the key should be copied, and the last parameter determines whether the parameter should not be preserved. We can now override this method with named parameters:
+ (id)__new:(const id *)keys :(const id *)objects :(unsigned long long)count :(_Bool)copyKeys :(_Bool)dontRetain;
Unfortunately, we don’t have explicit access to this private method, so by using the regular means of allocation the last two arguments are always set to YES and NO respectively. It is nevertheless interesting that __NSDictionaryI is capable of a more sophisticated keys and objects control.
Unfortunately, we cannot access this private method explicitly, so by using the regular allocation method, the last two parameters are always set to YES and NO respectively. Nonetheless, it is interesting to note that __NSDictionaryI is capable of providing more complex key and object controls.
####Instance variables indexed by Indexed ivars
Skimming through the disassembly of + __new::::: reveals that both malloc and calloc are nowhere to be found. Instead, the method calls into __CFAllocateObject2 passing the __NSDictionaryI class as first argument and requested storage size as a second. Stepping down into the sea of ARM64 shows that the first thing __CFAllocateObject2 does is call into class_createInstance with the exact same arguments.
Browsing the decomposition of + __new:::: reveals that neither malloc nor calloc exist. Instead, the method calls __CFAllocateObject2, passing the __NSDictionaryI class as the first parameter and the requested storage size as the second parameter. Stepping into the ocean of ARM64 shows that the first thing __CFAllocateObject2 does is call class_createInstance with the exact same parameters.
Fortunately, at this point we have access to the source code of Objective-C runtime which makes further investigation much easier. Fortunately, we now have access to the source code of the Objective-C runtime, which makes further research easier.
The class_createInstance(Class cls, size_t extraBytes) function merely calls into _class_createInstanceFromZonepassing nil as a zone, but this is the final step of object allocation. While the function itself has many additional checks for different various circumstances, its gist can be covered with just three lines:
The class_createInstance(Class cls, size_t extraBytes) function just calls _class_createInstanceFromZone and passes nil as the zone, but this is the last step of object allocation. Although the function itself has many additional checks for different situations, its gist can be described in three lines:
_class_createInstanceFromZone(Class cls, size_t extraBytes, void *zone)
{
...
size_t size = cls->alignedInstanceSize() + extraBytes;
...
id obj = (id)calloc(1, size);
...
return obj;
}
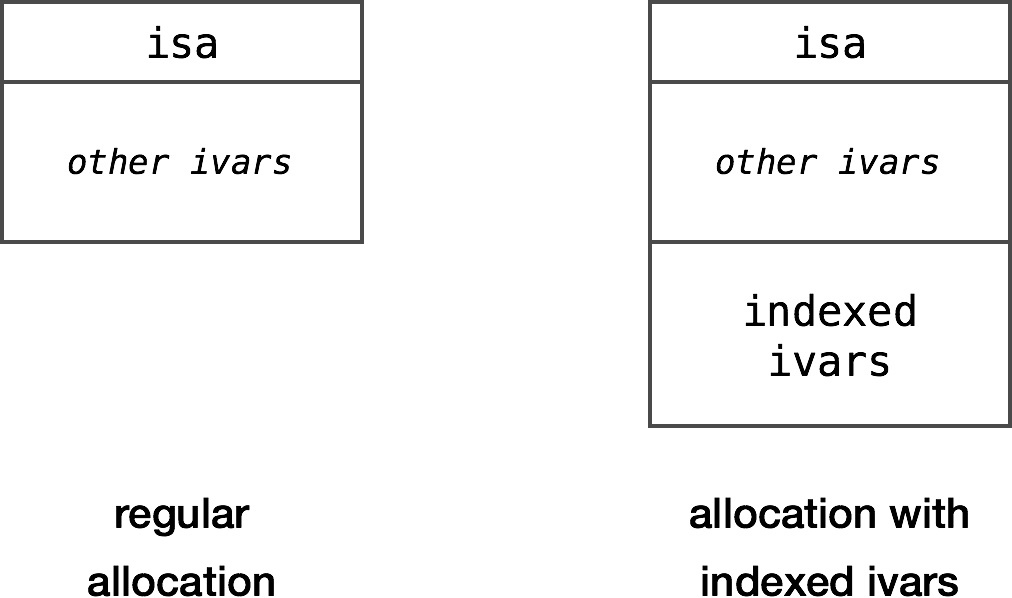
The extraBytes argument couldn’t have been more descriptive. It’s literally the number of extra bytes that inflate the default instance size. As an added bonus, notice that it’s the calloc call that ensures all the ivars are zeroed out when the object gets allocated.
A terabyte argument couldn’t be better. It’s actually the extra bytes that bloat the default instance size. Also, note that the calloc call ensures that all ivars are zeroed out when the object is allocated.
The indexed ivars section is nothing more than an additional space that sits at the end of regular ivars: The index ivars part is nothing more than an extra space at the end of regular ivars:
 Allocating objects
Allocating objects
Allocating space on its own doesn’t sound very thrilling so the runtime publishes an accessor: Allocating space individually doesn’t sound exciting, so the runtime publishes an accessor:
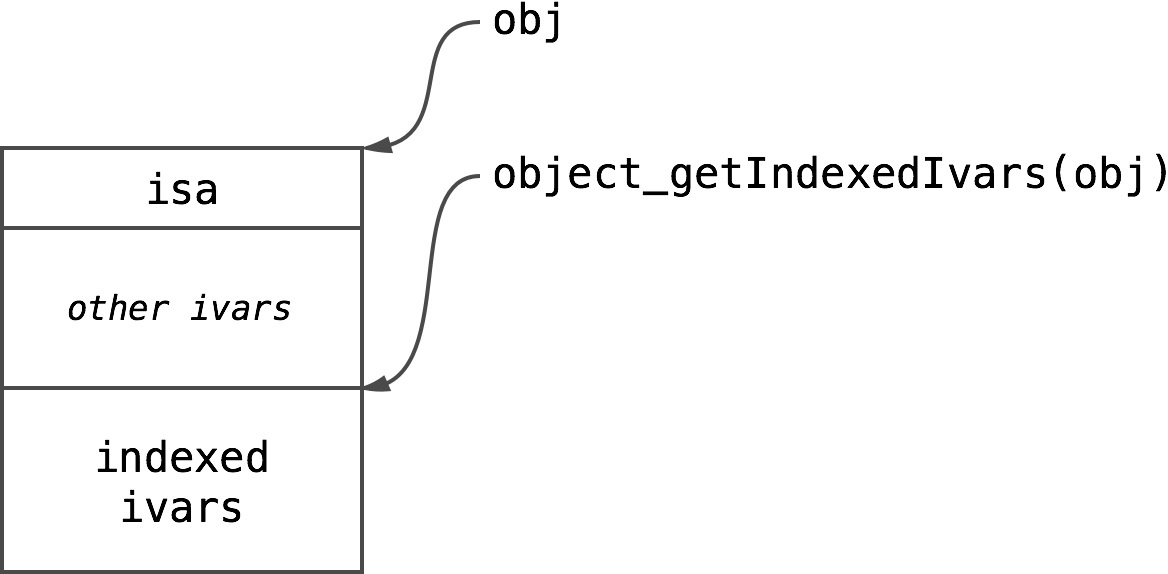
void *object_getIndexedIvars(id obj)
There is no magic whatsoever in this function, it just returns a pointer to the beginning of indexed ivars section: There’s nothing magical in this function, it just returns a pointer to the beginning of the index ivars section:
 Indexed ivars section
Indexed ivars section
There are few cool things about indexed ivars. First of all, each instance can have different amount of extra bytes dedicated to it. This is exactly the feature __NSDictionaryI makes use of.
There are few cool things about indexing ivars. First, each instance can have a different amount of extra bytes. This is exactly what __NSDictionaryI uses.
Secondly, they provide faster access to the storage. It all comes down to being cache-friendly. Generally speaking, jumping to random memory locations (by dereferencing a pointer) can be expensive. Since the object has just been accessed (somebody has called a method on it), it’s very likely that its indexed ivars have landed in cache. By keeping everything that’s needed very close, the object can provide as good performance as possible. Second, they provide faster storage access. It all comes down to cache friendliness. In general, jumping to a random memory location (by dereferencing a pointer) can be expensive. Since the object has just been accessed (someone called a method on it), its index ivar is most likely already in the cache. By keeping everything needed very close, objects can provide the best possible performance.
Finally, indexed ivars can be used as a crude defensive measure to make object’s internals invisible to the utilities like class-dump. This is a very basic protection since a dedicated attacker can simply look for object_getIndexedIvars calls in the disassembly or randomly probe the instance past its regular ivars section to see what’s going on.
Finally, index ivars can be used as a crude defense measure so that utilities like class dump cannot see the internal structure of an object. This is a very basic protection, as a dedicated attacker could simply look for the object_getIndexedIvars call in the disassembly, or randomly probe the instance via its regular ivars portion to see what’s going on.While powerful, indexed ivars come with two caveats. First of all, class_createInstance can’t be used under ARC, so you’ll have to compile some parts of your class with -fno-objc-arc flag to make it shine. Secondly, the runtime doesn’t keep the indexed ivar size information anywhere. Even though dealloc will clean everything up (as it calls free internally), you should keep the storage size somewhere, assuming you use variable number of extra bytes.
Although index ivar is powerful, there are two points to note. First, class_createInstance doesn’t work under ARC, so you have to compile some parts of the class with the -fno-objc-arc flag to make it shine. Second, the index ivar size information is not saved anywhere at runtime. Even though dealloc cleans everything up (because it calls free internally), you should preserve the storage size, assuming you use a variable amount of extra bytes.
Looking for Key and Fetching Object Looking for keys and retrieving objects
Analyzing Assembly Analysis Assembly
Although at this point we could poke the __NSDictionaryI instances to figure out how they work, the ultimate truth lies within the assembly. Instead of going through the entire wall of ARM64 we will discuss the equivalent Objective-C code instead.
While at this point we can poke around at __NSDictionaryI instances to see how they work, the ultimate truth lies in the assembly. We will discuss the equivalent Objective-C code, rather than the entire ARM64.
The class itself implements very few methods, but I claim the most important is objectForKey: – this is what we’re going to discuss in more detail. Since I made the assembly analysis anyway, you can read it on a separate page. It’s dense, but the thorough pass should convince you the following code is more or less correct.
The class itself implements very few methods, but I think the most important is objectForKey: - this is something we will discuss in more detail. Because I’ve done the compilation analysis, you can read it on a separate page. It’s dense, but the complete pass will lead you to believe that the code below is more or less correct.
The C Code C code
Unfortunately, I don’t have access to the Apple’s code base, so the reverse-engineered code below is not identical to the original implementation. On the other hand, it seems to be working well and I’ve yet to find an edge case that behaves differently in comparison to the genuine method. Unfortunately, I don’t have access to Apple’s code base, so the reverse-engineered code below is not identical to the original implementation. On the other hand, it seems to work just fine, and I haven’t found a corner case where it behaves differently than the real method.
The following code is written from the perspective of __NSDictionaryI class:
The following code is written from the perspective of the __NSDictionaryI class:
- (id)objectForKey:(id)aKey
{
NSUInteger sizeIndex = _szidx;
NSUInteger size = __NSDictionarySizes[sizeIndex];
id *storage = (id *)object_getIndexedIvars(dict);
NSUInteger fetchIndex = [aKey hash] % size;
for (int i = 0; i < size; i++) {
id fetchedKey = storage[2 * fetchIndex];
if (fetchedKey == nil) {
return nil;
}
if (fetchedKey == aKey || [fetchedKey isEqual:aKey]) {
return storage[2 * fetchIndex + 1];
}
fetchIndex++;
if (fetchIndex == size) {
fetchIndex = 0;
}
}
return nil;
}
When you take a closer look at the C code you might notice something strange about key fetching. It’s always taken from even offsets, while the returned object is at the very next index. This is the dead giveaway of __NSDictionaryI’s internal storage: it keeps keys and objects alternately:
When you look closely at the C code, you may notice some oddities with key acquisition. It always takes an even offset and the returned object is at the next index. This is a fatal flaw in __NSDictionaryI’s internal storage: it saves keys and objects alternately:
 Keys and objects are stored alternately
Keys and objects are stored alternately
Update: Joan Lluch provided a very convincing explanation for this layout. The original code could use an array of very simple structs: Update: Joan Lluch gave a very convincing explanation of this layout. The original code can use a very simple array of structures:
struct KeyObjectPair {
id key;
id object;
};
The objectForKey: method is very straightforward and I highly encourage you to walk through it in your head. It’s nonetheless worth pointing out a few things. First of all, the _szidx ivar is used as an index into the __NSDictionarySizes array, thus it most likely stands for “size index”.
The objectForKey: method is very simple and I highly recommend you go through it in your head. Nonetheless, there are a few points worth pointing out. First, the _szidx ivar is used as an index into the __nsdictionarysize array, so it most likely represents the “size index”.
Secondly, the only method called on the passed key is hash. The reminder of dividing key’s hash value by dictionary’s size is used to calculate the offset into the index ivars section.
Second, the only method called on the passed key is the hash. The hash of the reminder key divided by the size of the dictionary is used to calculate the offset into the ivars portion of the index.
If the key at the offset is nil, we simply return nil, the job is done:
If the key is nil at offset, we just return nil and the job is done:
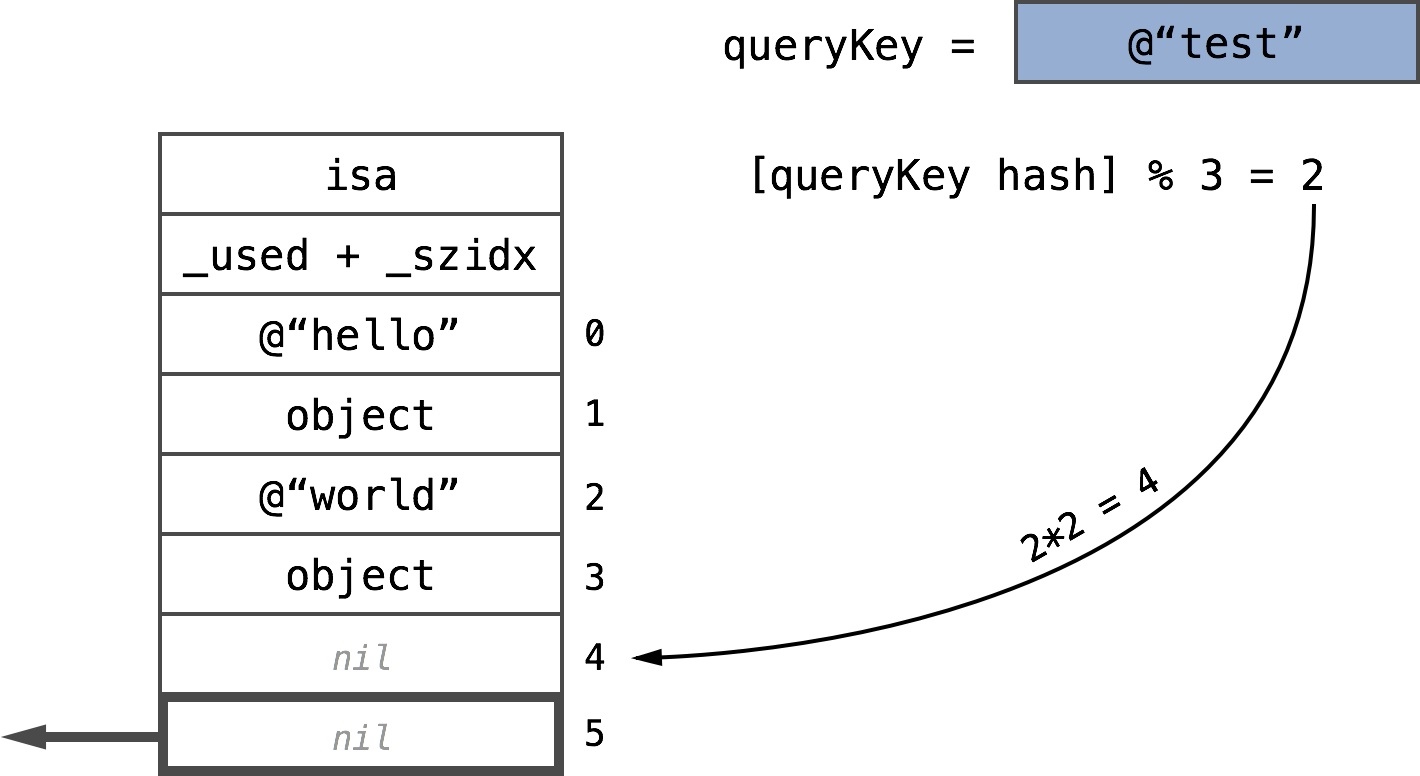 When the key slot is empty, nil is returned
When the key slot is empty, nil is returned
However, if the key at the offset is non nil, then the two cases may occur. If the keys are equal, then we return the adjacent object. If they’re not equal then the hash collision occurred and we have to keep looking further. __NSDictionaryI simply keeps looking until either match or nil is found:
However, both cases are possible if the key at offset is not nil. If the key values are equal, adjacent objects are returned. If they are not equal, a hash collision occurs and we have to keep looking. __nsdictionari just keeps looking until it finds a match or nil:
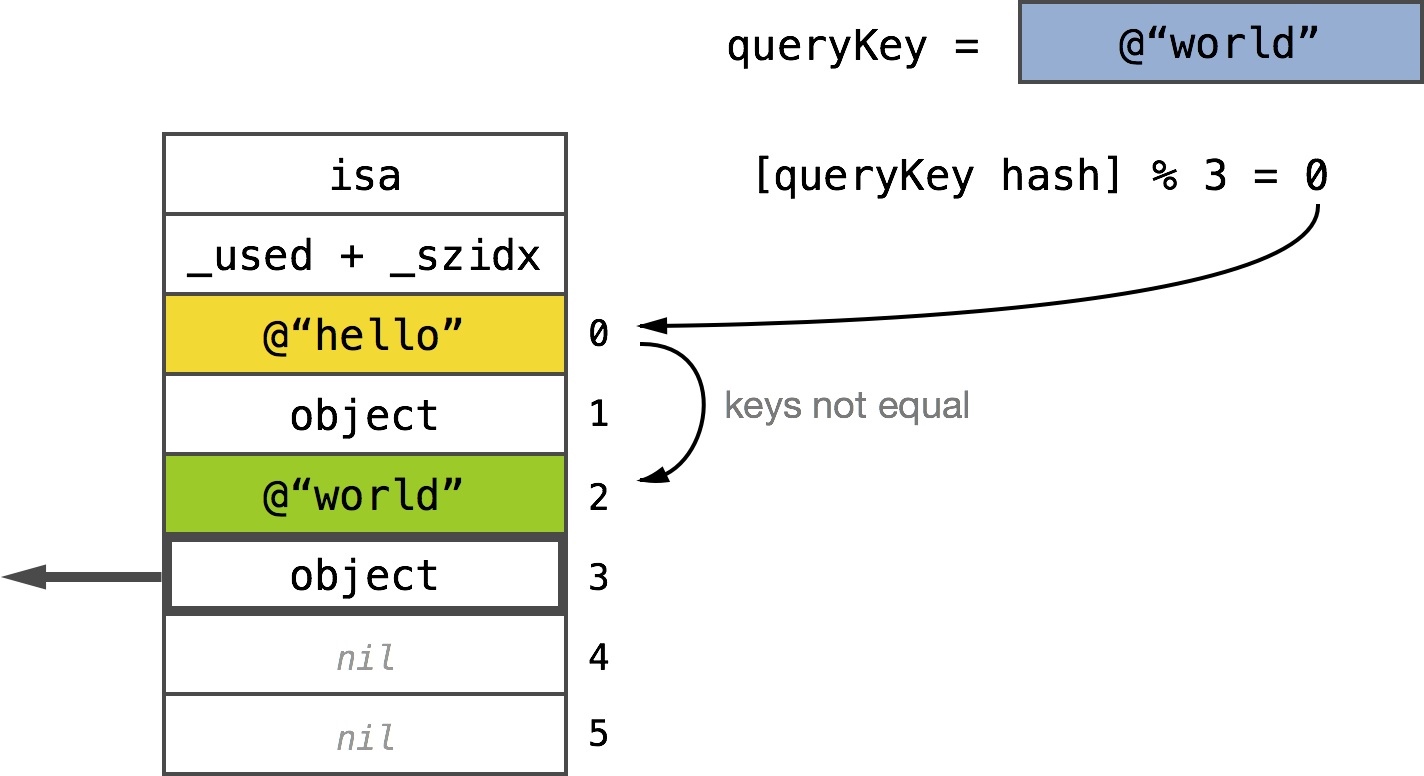 Key found after one collisionThis kind of searching is known as linear probing. Notice how
Key found after one collisionThis kind of searching is known as linear probing. Notice how __NSDictionaryI wraps the fetchIndex around when the storage end is hit. The for loop is there to limit the number of checks – if the storage was full and the loop condition was missing we’d keep looking forever.
This search is called linear probing. Notice how __NSDictionaryI wraps the fetchIndex when it reaches the storage side. The for loop is used to limit the number of checks - if the store is full and the loop condition is missing, we will keep looking.
####__NSDictionarySizes & __NSDictionaryCapacities
We already know __NSDictionarySizes is some kind of array that stores different possible sizes of __NSDictionaryI. We can reason that it’s an array of NSUIntegers and indeed, if we ask Hopper to treat the values as 64-bit unsigned integers it suddenly makes a lot of sense:
We already know that __nsdictionarysize is some kind of array that stores __NSDictionaryI of different sizes. We can infer that it is an array of NSUIntegers, and indeed if we ask Hopper to handle these values as 64-bit unsigned integers, it suddenly makes sense:
___NSDictionarySizes:
0x00000000001577a8 dq 0x0000000000000000
0x00000000001577b0 dq 0x0000000000000003
0x00000000001577b8 dq 0x0000000000000007
0x00000000001577c0 dq 0x000000000000000d
0x00000000001577c8 dq 0x0000000000000017
0x00000000001577d0 dq 0x0000000000000029
0x00000000001577d8 dq 0x0000000000000047
0x00000000001577e0 dq 0x000000000000007f
...
In a more familiar decimal form it presents as a beautiful list of 64 primes starting with the following sequence: 0, 3, 7, 13, 23, 41, 71, 127. Notice, that those are not consecutive primes which begs the question: what’s the average ratio of the two neighboring numbers? It’s actually around 1.637 – a very close match to the 1.625 which was the growth factor for NSMutableArray. For details of why primes are used for the storage size this Stack Overflow answer is a good start.
In a more familiar decimal form, it represents a nice list of 64 prime numbers, starting with the following sequence: 0, 3, 7, 13, 23, 41, 71, 127. Note that these are not consecutive prime numbers. This begs the question what is the average ratio of two adjacent numbers? It is actually around 1.637, which is very close to NSMutableArray’s growth factor of 1.625. For more details on why prime numbers are used for storage sizes, this Stack Overflow answer is a good start.
We already know how much storage can __NSDictionaryI have, but how does it know which size index to pick on initialization? The answer lies within the previously mentioned + __new::::: class method. Converting some parts of the assembly back to C renders the following code:
We already know how much storage __NSDictionaryI can have, but how does it know which size index to choose at initialization time? The answer lies in the + __new:::: class method mentioned earlier. Converting some parts of the assembly back to C renders the following code:
int szidx;
for (szidx = 0; szidx < 64; szidx++) {
if (__NSDictionaryCapacities[szidx] >= count) {
break;
}
}
if (szidx == 64) {
goto fail;
}
The method looks linearly through __NSDictionaryCapacities array until count fits into the size. A quick glance in Hopper shows the contents of the array:
This method searches linearly through the __nsdictionarycapacity array until count matches that size. At a quick glance in Hopper, the contents of the array are as follows:
___NSDictionaryCapacities:
0x00000000001579b0 dq 0x0000000000000000
0x00000000001579b8 dq 0x0000000000000003
0x00000000001579c0 dq 0x0000000000000006
0x00000000001579c8 dq 0x000000000000000b
0x00000000001579d0 dq 0x0000000000000013
0x00000000001579d8 dq 0x0000000000000020
0x00000000001579e0 dq 0x0000000000000034
0x00000000001579e8 dq 0x0000000000000055
...
Converting to base-10 provides 0, 3, 6, 11, 19, 32, 52, 85 and so on. Notice that those are smaller numbers than the primes listed before. If you were to fit 32 key-value pairs into __NSDictionaryI it will allocate space for 41 pairs, conservatively saving quite a few empty slots. This helps reducing the number of hash collisions, keeping the fetching time as close to constant as possible. Apart from trivial case of 3 elements, __NSDictionaryI will never have its storage full, on average filling at most 62% of its space.
Converting to base-10 provides 0, 3, 6, 11, 19, 32, 52, 85, and so on. Note that these numbers are smaller than the prime numbers listed previously. If you put 32 key-value pairs into __NSDictionaryI, it will allocate space for 41 key-value pairs, conservatively saving quite a lot of empty slots. This helps reduce the number of hash collisions and keeps the fetch time as close to constant as possible. Except for the simple case of 3 elements, __NSDictionaryI’s storage is never full, filling up to 62% of the space on average.
As a trivia, the last nonempty value of __NSDictionaryCapacities is 0x11089481C742 which is 18728548943682 in base-10. You’d have to try really hard not to fit in within the pairs count limit, at least on 64-bit architecture.
As a trivia, the last non-null value of __nsdictionarycapacity is 0x11089481C742, which in base-10 is 18728548943682. At least on 64-bit architectures, you have to try very hard not to comply with the limit on the count.
Non Exported Symbols Non-export flag
If you were to use __NSDictionarySizes in your code by declaring it as an extern array, you’d quickly realize it’s not that easy. The code wouldn’t compile due to a linker error – the __NSDictionarySizes symbol is undefined. Inspecting the CoreFoundation library with nm utility:
If you use __nsdictionarysize in your code by declaring __nsdictionarysize as an extern array, you will quickly realize that this is not easy. The code fails to compile due to a linker error - __nsdictionarysize symbol is undefined. Use the nm tool to check the CoreFoundation library:
nm CoreFoundation | grep ___NSDictionarySizes
…clearly shows the symbols are there (for ARMv7, ARMv7s and ARM64 respectively): …clearly shows the presence of symbols (ARMv7, ARMv7s and ARM64 respectively):
00139c80 s ___NSDictionarySizes
0013ac80 s ___NSDictionarySizes
0000000000156f38 s ___NSDictionarySizes
Unfortunately the nm manual clearly states: Unfortunately, the nm manual clearly states:
If the symbol is local (non-external), the symbol’s type is instead represented by the corresponding lowercase letter.The symbols for
__NSDictionarySizesare simply not exported – they’re intended for internal use of the library. I’ve done some research to figure out if it’s possible to link with non-exported symbols, but apparently it is not (please tell me if it is!). We can’t access them. That is to say, we can’t access them easily. The symbols for__nsdictionarysizeare not exported - they are for the library’s internal use. I did some research and wondered if it was possible to link to non-exported symbols, but apparently it’s not possible (please tell me if it is possible!) and we can’t access them. That is, we cannot access them easily.
####Sneaking in Secretly in
Here’s an interesting observation: in both iOS 7.0 an 7.1 the kCFAbsoluteTimeIntervalSince1904 constant is laid out directly before __NSDictionarySizes:
An interesting observation here: in iOS 7.0 and 7.1, the kCFAbsoluteTimeIntervalSince1904 constant is listed directly before __nsdictionarysize:
_kCFAbsoluteTimeIntervalSince1904:
0x00000000001577a0 dq 0x41e6ceaf20000000
___NSDictionarySizes:
0x00000000001577a8 dq 0x0000000000000000
The best thing about kCFAbsoluteTimeIntervalSince1904 is that it is exported! We’re going to add 8 bytes (size of double) to the address of this constant and reinterpret the result as pointer to NSUInteger:
The best thing about kcfabsolutetimeintervalvalis since 1904 is that it is exported! We will add 8 bytes (double the size) to the address of this constant and reinterpret the result as a pointer to an NSUInteger:
NSUInteger *Explored__NSDictionarySizes = (NSUInteger *)((char *)&kCFAbsoluteTimeIntervalSince1904 + 8);
Then we can access its values by convenient indexing: We can then access its value via a convenient index:
(lldb) p Explored__NSDictionarySizes[0]
(NSUInteger) $0 = 0
(lldb) p Explored__NSDictionarySizes[1]
(NSUInteger) $1 = 3
(lldb) p Explored__NSDictionarySizes[2]
(NSUInteger) $2 = 7
This hack is very fragile and will most likely break in the future, but this is the test project so it’s perfectly fine. This hack is very fragile and will most likely break in the future, but this is a test project so it’s perfect.
__NSDictionaryI Characteristics __NSDictionaryI Characteristics
Now that we’ve discovered the internal structure of __NSDictionaryI we can use this information to figure out why things work they way they work and what unforeseen consequences does the present implementation of __NSDictionaryI introduce.
Now that we have discovered the internal structure of __NSDictionaryI, we can use this information to figure out why things work the way they do, and what unforeseen consequences the current __NSDictionaryI implementation has.
Printout Code Printout code
To make our investigation a little bit easier we will create a helper NSDictionary category method that will print the contents of the instance
To make our research easier, we will create a helper NSDictionary category method that will print the contents of the instance
- (NSString *)explored_description
{
assert([NSStringFromClass([self class]) isEqualToString:@"__NSDictionaryI"]);
BCExploredDictionary *dict = (BCExploredDictionary *)self;
NSUInteger count = dict->_used;
NSUInteger sizeIndex = dict->_szidx;
NSUInteger size = Explored__NSDictionarySizes[sizeIndex];
__unsafe_unretained id *storage = (__unsafe_unretained id *)object_getIndexedIvars(dict);
NSMutableString *description = [NSMutableString stringWithString:@"\n"];
[description appendFormat:@"Count: %lu\n", (unsigned long)count];
[description appendFormat:@"Size index: %lu\n", (unsigned long)sizeIndex];
[description appendFormat:@"Size: %lu\n", (unsigned long)size];
for (int i = 0; i < size; i++) {
[description appendFormat:@"[%d] %@ - %@\n", i, [storage[2*i] description], [storage[2*i + 1] description]];
}
return description;
}
Order of keys/objects on enumeration is the same as order of keys/objects in storage
The order of the keys/objects in the enum is the same as the order of the keys/objects in the storage
Let’s create a simple dictionary containing four values: Let’s create a simple dictionary with four values:
NSDictionary *dict = @{@1 : @"Value 1",
@2 : @"Value 2",
@3 : @"Value 3",
@4 : @"Value 4"};
NSLog(@"%@", [dict explored_description]);
The output of the explored description is: The output of the description explored is:
Count: 4
Size index: 2
Size: 7
[0] (null) - (null)
[1] 3 - Value 3
[2] (null) - (null)
[3] 2 - Value 2
[4] (null) - (null)
[5] 1 - Value 1
[6] 4 - Value 4
With that in mind let’s do a quick enumeration over dictionary: With this in mind, let’s make a quick enumeration dictionary:
[dict enumerateKeysAndObjectsUsingBlock:^(id key, id obj, BOOL *stop) {
NSLog(@"%@ - %@", key, obj);
}];
And the output: and output:
3 - Value 3
2 - Value 2
1 - Value 1
4 - Value 4
Enumeration seems to simply walk through the storage, ignoring the nil keys and calling the block only for non-empty slots. This is also the case for fast enumeration, keyEnumerator, allKeys and allValues methods. It makes perfect sense. The NSDictionary is not ordered, so it doesn’t really matter in what sequence the keys and values are provided. Using the internal layout is the easiest and probably the fastest option.
The enum seems to just iterate over the storage, ignoring nil keys, and only calling blocks for non-null slots. This is also the case for fast enumeration, key enumerators, allKeys and allValues methods. This makes perfect sense. NSDictionary is not ordered, so the order of keys and values doesn’t matter. Using an internal layout is the easiest and fastest option.
If you mess up, __NSDictionaryI may return something for nil key! If you mess up, __nsdictionaryI may return something for nil key!
Let’s consider an example. Imagine we’re building a simple 3D strategy game set in space. The entire universe is split into cube-like sectors that imaginary factions can fight over. A sector can be referenced by its i, j and k indexes. would waste memory storing nil pointers. Instead, we’re going to use a sparse storage in a form of NSDictionary with a custom key class that will make it super easy to query if there is something at a given location.
Let’s consider an example. Let’s say we are building a simple 3D strategy game. The entire universe is split into cube-like areas over which imaginary factions can fight. A sector can be referenced by its i, j and k indices. We shouldn’t use a 3D array to store sector information - the game space is huge and mostly empty, so we’d be wasting memory storing nil pointers. Instead, we’re going to use a sparse storage in the form of an NSDictionary, with a custom key class that will make it super easy to query if there’s something at a given location.
Here’s the interface for key, a BC3DIndex class:
This is the interface of key, a BC3DIndex class:
@interface BC3DIndex : NSObject <NSCopying>
@property (nonatomic, readonly) NSUInteger i, j, k; // you actually can do that
- (instancetype)initWithI:(NSUInteger)i j:(NSUInteger)j k:(NSUInteger)k;
@end
And its equally trivial implementation: And its equally trivial implementation:
@implementation BC3DIndex
- (instancetype)initWithI:(NSUInteger)i j:(NSUInteger)j k:(NSUInteger)k
{
self = [super init];
if (self) {
_i = i;
_j = j;
_k = k;
}
return self;
}
- (BOOL)isEqual:(BC3DIndex *)other
{
return other.i == _i && other.j == _j && other.k == _k;
}
- (NSUInteger)hash
{
return _i ^ _j ^ _k;
}
- (id)copyWithZone:(NSZone *)zone
{
return self; // we're immutable so it's OK
}
@end
```Notice how we’re being a good subclassing citizen: we implemented both `isEqual`: and `hash` methods and made sure that if two 3D-indexes are equal then their hash values are equal as well. The object equality requirements are fulfilled.
Notice how we are being a good subclassing citizen: we implement the isEqual: and hash methods and make sure that if two 3d indices are equal, then their hashes are also equal. The object equality requirement is met.
Here’s a trivia: what will the following code print?
Here's a little question: what will the following code print?
NSDictionary *indexes = @{[[BC3DIndex alloc] initWithI:2 j:8 k:5] : @“A black hole!”, [[BC3DIndex alloc] initWithI:0 j:0 k:0] : @“Asteroids!”, [[BC3DIndex alloc] initWithI:4 j:3 k:4] : @“A planet!”};
NSLog(@“%@”, [indexes objectForKey:nil]);
It should be `(null)` right? Nope:
It should be (null), right? No:
Asteroids!
To investigate this further let’s grab a dictionary’s description:
To investigate this further, let's get a dictionary description:
Count: 3 Size index: 1 Size: 3 [0] <BC3DIndex: 0x17803d340> - A black hole! [1] <BC3DIndex: 0x17803d360> - Asteroids! [2] <BC3DIndex: 0x17803d380> - A planet!
It turns out `__NSDictionaryI` doesn’t check if the `key` passed into `objectForKey:` is `nil` (and I’d argue this is a good design decision). Calling `hash` method on `nil` returns `0`, which causes the class to compare key at index `0` with `nil`. This is important: it is the stored key that executes the `isEqual:` method, not the passed in key.
The result is that __nsdictionari doesn't check if the key passed to objectForKey: is nil (which I think is a good design decision). Calling the hash method on nil will return 0, which will cause the class to compare the key at index 0 to nil. This is important: it is the stored key that executes the isEqual: method, not the passed in key.
The first comparison fails, since `i` index for “A black hole!” is `2` whereas for `nil` it’s zero. The keys are not equal which causes the dictionary to keep looking, hitting another stored key: the one for “Asteroids!”. This key has all three `i`, `j`, and `k` properties equal to `0` which is also what `nil` will return when asked for its properties (by the means of `nil` check inside `objc_msgSend`).
The first comparison failed because I indexed "A black hole!" which is 2 and nil is 0. The two keys are not equal, which causes the dictionary to continue looking and hit another stored key: "Asteroid!" This key has all three i, j, and k attributes that are equal to 0, which is also the value nil returns when requesting its attributes (via the nil check in objc_msgSend).
This is the crux of the problem. The `isEqual:` implementation of `BC3DIndex` may, under some conditions, return `YES` for `nil` comparison. As you can see, this is a very dangerous behavior that can mess things up easily. Always ensure that your object is not equal to `nil`.
This is the crux of the matter. isEqual: Under certain conditions, BC3DIndex implementations may return YES for nil comparisons. As you can see, this is a very dangerous behavior and can easily mess things up. Always make sure the object is not equal to nil.
#### A Helper Key Class Auxiliary key class
For the next two tests we’re going to craft a special key class that will have a configurable hash value and will print stuff to the console when executing `hash` and `isEqual:` method.
In the next two tests, we will create a special key class that will have a configurable hash value and print the content to the console when the hash and isEqual: methods are executed.
Here’s the interface:
This is the interface:
@interface BCNastyKey : NSObject <NSCopying>
@property (nonatomic, readonly) NSUInteger hashValue;
- (instancetype)keyWithHashValue:(NSUInteger)hashValue;
@end
And the implementation:
@implementation BCNastyKey
- (instancetype)keyWithHashValue:(NSUInteger)hashValue { return [[BCNastyKey alloc] initWithHashValue:hashValue]; }
-
(instancetype)initWithHashValue:(NSUInteger)hashValue { self = [super init]; if (self) { _hashValue = hashValue; } return self; }
-
(id)copyWithZone:(NSZone *)zone { return self; }
-
(NSUInteger)hash { NSLog(@“Key %@ is asked for its hash”, [self description]);
return _hashValue; }
-
(BOOL)isEqual:(BCNastyKey *)object { NSLog(@“Key %@ equality test with %@: %@”, [self description], [object description], object == self ? @“YES” : @“NO”);
return object == self; }
-
(NSString *)description { return [NSString stringWithFormat:@“(&:%p #:%lu)”, self, (unsigned long)_hashValue]; }
@end
This key is awful: we’re only equal to self, but we’re returning an arbitrary hash. Notice that this doesn’t break the equality contract.
This key is bad: we only equal self, but we return an arbitrary hash. Note that this does not violate the equality contract.
#### isEqual doesn’t have to be called to match the key
Let’s create a key and a dictionary:
Let's create a key and a dictionary:
BCNastyKey *key = [BCNastyKey keyWithHashValue:3]; NSDictionary *dict = @{key : @“Hello there!”};
The following call:
The following phone numbers:
[dict objectForKey:key];
Prints this to the console:
Print to console:
Key (&:0x17800e240 #:3) is asked for its hash
As you can see, the `isEqual:` method has not been called. This is very cool! Since the vast majority of keys out there are `NSString` literals, they share the same address in the entire application. Even if the key is a very long literal string, the `__NSDictionaryI` won’t run the potentially time consuming `isEqual:` method unless it absolutely has to. And since 64-bit architectures introduced tagged pointers, some instances of `NSNumber`, `NSDate` and, apparently, `NSIndexPath` benefit from this optimization as well.
As you can see, the isEqual: method has not been called yet. This is cool! Since the vast majority of keys are NSString literals, they share the same address throughout the application. Even if the key is a long literal string, __NSDictionaryI will not run the potentially time-consuming isEqual: method unless absolutely necessary. Since 64-bit architectures introduced tagged pointers, some instances of NSNumber, NSDate, and NSIndexPath apparently also benefited from this optimization.
#### Worst case performance is linear Worst case performance is linear
Let’s create a very simple test case:
Let's create a very simple test case:
BCNastyKey *targetKey = [BCNastyKey keyWithHashValue:36];
NSDictionary *b = @{[BCNastyKey keyWithHashValue:1] : @1, [BCNastyKey keyWithHashValue:8] : @2, [BCNastyKey keyWithHashValue:15] : @3, [BCNastyKey keyWithHashValue:22] : @4, [BCNastyKey keyWithHashValue:29] : @5, targetKey : @6 };
A single killer line:
A simple trump card:
NSLog(@“Result: %@”, [[b objectForKey:targetKey] description]);
Reveals the disaster:
Disaster revealed:
Key (&:0x170017640 #:36) is asked for its hash Key (&:0x170017670 #:1) equality test with (&:0x170017640 #:36): NO Key (&:0x170017660 #:8) equality test with (&:0x170017640 #:36): NO Key (&:0x170017680 #:15) equality test with (&:0x170017640 #:36): NO Key (&:0x1700176e0 #:22) equality test with (&:0x170017640 #:36): NO Key (&:0x170017760 #:29) equality test with (&:0x170017640 #:36): NO Result: 6
This is extremely pathological case – every single key in the dictionary has ben equality tested. Even though each hash was different, it still collided with every other key, because the keys’ hashes were congruent modulo 7, which turned out to be the storage size of the dictionary.
This is an extremely pathological case - every key in the dictionary is tested for Ben's equality. Even though each hash is different, it still collides with other keys because the key's hash is modulo 7, which is the storage size of the dictionary.As mentioned before, notice that the last `isEqual:` test is missing. The `__NSDictionaryI` simply compared the pointers and figured out it must be the same key.
As mentioned before, notice that the last isEqual: test is missing. __nsdictionari simply compares the pointers and finds that they must be the same key.
Should you care for this linear time fetching? Absolutely not. I’m not that into probabilistic analysis of hash distribution, but you’d have to be extremely lucky for all your hashes to be modulo congruent to dictionary’s size. Some collisions here and there will always happen, this is the nature of hash tables, but you will probably never run into the linear time issue. That is, unless you mess up your `hash` function.
Should you care about this linear time acquisition? Absolutely not. I'm not a big fan of probabilistic analysis of hash distributions, but you have to be very lucky that all your hashes are modulo the size of the dictionary. There will always be some collisions here and there, that's the nature of hash tables, but you'll probably never run into a linear time problem. Unless you messed up the hash function.
### Final WordsFinal Words
I’m fascinated how simple the `__NSDictionaryI` turned out to be. Needless to say, the class certainly serves its purpose and there’s no need to make things excessively complex. For me, the most beautiful aspect of the implementation is the key-object-key-object layout. This is a brilliant idea.
I was intrigued by how simple this dictionary turned out to be. Needless to say, this class certainly serves its purpose and there is no need to overcomplicate things. To me, the most beautiful aspect of this implementation is the key-object-key-object layout. This is a good idea.
If you were to take one tip from this article then I’d go with watching out for your `hash` and `isEqual:` methods. Granted, one rarely writes custom key classes to be used in a dictionary, but those rules apply to `NSSet` as well.
If you take one tip from this article, then I recommend paying attention to hash and isEqual: methods. Granted, few people write custom key classes for use in dictionaries, but these rules apply to NSSets as well.
I’m aware that at some point in time `NSDictionary` will change and my findings will become obsolete. Internalizing the current implementation details may become a burden in the future, when the memorized assumptions will no longer apply. However, right here and right now it’s just so much fun to see how things work and hopefully you share my excitement.
I know that at some point the NSDictionary will change and my findings will become obsolete. Internalizing current implementation details can become a future burden when the remembered assumptions no longer apply. However, right here and now, it's really fun to see how things work, and I hope you can share my excitement.
Original text: https://ciechanow.ski/exposing-nsdictionary/What to read next
Want more posts about iOS?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #iOS?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home