ARTES #004
ARTES #004
ARTES es una actividad iniciada por
由左耳朵耗子--陈皓: Haga al menos una pregunta sobre el algoritmo leetcode cada semana, lea y comente al menos un artículo técnico en inglés, aprenda al menos una habilidad técnica y comparta un artículo con opiniones y pensamientos. (Es decir, Algoritmo, Revisión, Sugerencia y Compartir se denominan ARTS) y persisten durante al menos un año.
##ARTES 004
Este es el cuarto artículo. Está relativamente mal escrito. Espero que mejore cada vez más en el futuro.
Pregunta sobre el algoritmo del algoritmo
Pregunta 321 del algoritmo leetcode Crear número máximo (número máximo de empalme) Podría ser: difícil
Given two arrays of length m and n with digits 0-9 representing two numbers. Create the maximum number of length k <= m + n from digits of the two. The relative order of the digits from the same array must be preserved. Return an array of the k digits.
Note: You should try to optimize your time and space complexity.
Example 1:
Input:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
Output:
[9, 8, 6, 5, 3]
Example 2:
Input:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
Output:
[6, 7, 6, 0, 4]
Example 3:
Input:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
Output:
[9, 8, 9]
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
示例 1:
输入:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
输出:
[9, 8, 6, 5, 3]
示例 2:
输入:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
输出:
[6, 7, 6, 0, 4]
示例 3:
输入:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
输出:
[9, 8, 9]
Ideas para resolver problemas:
-
1 Determine cuántos números toma cada una de las dos matrices, por ejemplo, k = 5, que se puede dividir en 1, 4; 2, 3; 3, 2; 4, 1; y debe ser menor que el número de nums1 o nums2. Este paso es relativamente simple.
-
2 Combina los subarreglos que cumplen las condiciones en uno Este paso es más complicado. Por ejemplo, números1 = [6, 7, 0]; números2 = [6, 0, 4], k=5; k se puede dividir en 2, 3; 3, 2; Ahora considere los casos 2 y 3, nums1_1 = [6, 7]; números2_1 = [6, 0, 4]; Entonces, ¿cómo se combinan estos dos subconjuntos en un número máximo? A primera vista parece bastante sencillo. Simplemente tome uno de cada una de las dos matrices y elija el que sea más grande. Pero aquí hay un peligro. ¿Qué debo hacer si las tallas son iguales? Por ejemplo, los primeros números de nums1_1 y nums2_1 son ambos 6, ¿cuál debería elegirse? Veamos qué es diferente. Si tomas 6 de nums2_1 por primera vez, después de tomarlo, nums1_1 = [6, 7]; números2_1 = [0, 4]; La segunda vez, nums1_1 toma 6, nums2_1 solo puede tomar 0, 6 es mayor que 0, así que toma 6, después de tomarlo, nums1_1 = [7]; nums2_1 = [0, 4];, el resultado final es [6,6,7,0,4]
Si tomas 6 de nums1_1 por primera vez, después de tomarlo, nums1_1 = [7]; números2_1 = [6,0, 4]; Por segunda vez, nums1_1 toma 7 y nums2_1 toma 6. 7 es mayor que 6, por lo que se toma 7. Después de tomarlo, nums1_1 = []; nums2_1 = [6,0, 4];, el resultado final es [6,7,6,0,4]
Los resultados son diferentes, obviamente el segundo tiene razón. ¿El método de fusión que utilizamos anteriormente es similar al algoritmo utilizado en la ordenación por fusión, pero cuando se fusionan matrices en la ordenación por fusión, las dos matrices están en orden, pero las dos matrices que fusionamos aquí no están ordenadas, por lo que encontraremos este problema? Mi código de prácticas es el siguiente:
/**
* Return an array of size *returnSize.
* Note: The returned array must be malloced, assume caller calls free().
*/
int maxInexd(int* nums,int max,int min){
int maxindex = min;
int count = nums[maxindex];
for (int i = min; i<=max; i++) {
if (nums[i] > count) {
count = nums[i];
maxindex = i;
}
}
return maxindex;
}
int* maxNumber1(int* nums, int numsSize, int numcount){
int *a = (int *)malloc(numcount*sizeof(int));
int index = -1;
for (int i = 0; i < numcount; i++) {
index = maxInexd(nums, numsSize - numcount +i, index+1);
a[i] = nums[index];
}
return a;
}
int* merge(int* num11, int nums1count, int* num22, int nums2count, int k){
//把两个数组合并为一个
int* tempReturnSize = (int *)malloc(k*sizeof(int));
int mm = 0;
int nn = 0;
for (int i = 0; i < k; i++) {
if (mm == nums1count) {
int a = num22[nn];
tempReturnSize[i] = a;
nn++;
continue;
}
if (nn == nums2count) {
int b = num11[mm];
tempReturnSize[i] = b;
mm++;
continue;
}
int aa = num11[mm];
int bb = num22[nn];
if (aa >bb) {
tempReturnSize[i] = aa;
mm++;
}
else if (aa == bb){
int aa1 = aa;
int bb1 = bb;
int ii = 0;
while (mm + ii +1 != nums1count && nn + ii+1 != nums2count && aa1 ==bb1 ) {
ii++;
aa1 = num11[mm + ii];
bb1 = num22[nn + ii];
}
if (aa1 > bb1) {
tempReturnSize[i] = aa;
mm++;
continue;
}
else if(aa1 < bb1){
tempReturnSize[i] = bb;
nn++;
continue;
}
if (mm + ii +1 == nums1count) {//说明没有下一个
tempReturnSize[i] = bb;
nn++;
continue;
}
if (nn + ii +1 == nums2count) {//说明没有下一个
tempReturnSize[i] = bb;
mm++;
continue;
}
}
else{
tempReturnSize[i] = bb;
nn++;
}
}
return tempReturnSize;
}
int* maxNumber(int* nums1, int nums1Size, int* nums2, int nums2Size, int k, int* returnSize) {
*returnSize = k; //在leetcode提交的时候,不知道为什么要加上这个
if (nums1Size ==0) {
return nums2;
}
if (nums2Size ==0) {
return nums1;
}
int* relsut = (int*)malloc(sizeof(int) * k);
memset(relsut, 0, sizeof(int) * k);
int nums1count, nums2count;
for (nums1count = 1; nums1count <= nums1Size; nums1count++) {//nums1count 表示从nums1数组取的数的个数 最少是1 最大是nums1Size
nums2count = k - nums1count;
if (nums2count > nums2Size) {
continue;
}
if(nums2count == 0){//不能不从nums2取值
break;
}
//从nums1中按序取出nums1count个数,且这个几个数按序组装成整数之后是最大的
int *num11 = maxNumber1(nums1, nums1Size,nums1count);
//从nums2中按序取出nums2count个数,且这个几个数按序组装成整数之后是最大的
int *num22 = maxNumber1(nums2, nums2Size,nums2count);
//把两个数组合并为一个
int* tempReturnSize =merge( num11, nums1count, num22, nums2count, k);
//比较最大的数值
for (int i = 0; i < k; i++) {
int aa = tempReturnSize[i];
int bb = relsut[i];
if (aa > bb) {
for (int j = 0; j < k; j++){
relsut[j] = tempReturnSize[j];
}
break;
}
else if (bb >aa){
break;
}
}
free(tempReturnSize);
free(num11);
free(num22);
}
return relsut;
}
El tiempo de ejecución en LeetCode es de 20 ms. El siguiente código es un código enviado en LeetCode con un tiempo de ejecución de 8 ms. Se siente similar a mi implementación. No sé donde es más rápido:
void maxNum(int*, int, int, int*);
void merge(int*, int, int*, int, int*);
void max(int*, int*, int);
int* maxNumber(int* nums1, int nums1Size, int* nums2, int nums2Size, int k, int* returnSize)
{
*returnSize = k;
int* result = (int*)malloc(sizeof(int) * k);
memset(result, 0, sizeof(int) * k);
int* merged = (int*)malloc(sizeof(int) * k);
int *max1 = NULL, *max2 = NULL;
for (int i = 0; i <= k; i++) {
int n1 = i, n2 = k - i;
if (n1 > nums1Size || n2 > nums2Size)
continue;
max1 = realloc(max1, sizeof(int) * n1);
maxNum(nums1, nums1Size, n1, max1);
max2 = realloc(max2, sizeof(int) * n2);
maxNum(nums2, nums2Size, n2, max2);
merge(max1, n1, max2, n2, merged);
max(result, merged, k);
}
free(max1), free(max2), free(merged);
return result;
}
void maxNum(int* nums, int n, int k, int* r)
{
for (int i = 0, j = 0; i < n; i++) {
// drop last one
while (j > 0 && k - j < n - i && nums[i] > r[j - 1])
j--;
if (j < k)
r[j++] = nums[i];
}
}
void merge(int* nums1, int n1, int* nums2, int n2, int* r)
{
for (int i = 0, j = 0, k = 0; k < n1 + n2; k++) {
int val1 = i < n1 ? nums1[i] : -1;
int val2 = j < n2 ? nums2[j] : -1;
int t = 1;
while (val1 == val2 && val1 != -1) {
val1 = i + t < n1 ? nums1[i + t] : -1;
val2 = j + t < n2 ? nums2[j + t] : -1;
t++;
}
if (val1 > val2)
r[k] = nums1[i++];
else if (val1 < val2)
r[k] = nums2[j++];
else
// val1 == val2 == -1
r[k] = nums1[i++];
}
}
void max(int* nums1, int* nums2, int n)
{
int i;
for (i = 0; i < n; i++) {
if (nums1[i] < nums2[i])
break;
if (nums1[i] > nums2[i])
return;
}
if (i != n)
// set the new max
for (i = 0; i < n; i++)
nums1[i] = nums2[i];
}
Revisión
Este artículo proviene de: https://medium.com/exploring-code/why-should-you-learn-go-f607681fad65
¿Por qué deberías aprender Go? (¿Por qué deberías aprender Go?)

Imagen de: http://kirael-art.deviantart.com/art/Go-lang-Mascot-458285682
“Go será el lenguaje de servidor del futuro”. — Tobias Lütke, Shopify
En los últimos años, ha surgido un nuevo lenguaje de programación: Go o GoLang. Nada vuelve loco a un desarrollador que un nuevo lenguaje de programación, ¿verdad? Entonces, comencé a aprender Go antes de los 4 o 5 meses y aquí te voy a contar por qué tú también deberías aprender este nuevo idioma.
En los últimos años ha surgido un nuevo lenguaje de programación: Go o GoLang. Nada vuelve locos a los desarrolladores excepto los nuevos lenguajes de programación, ¿verdad? Entonces, comencé a aprender Go hace 4 o 5 meses y aquí te diré por qué tú también deberías aprender este nuevo idioma.
No voy a enseñarte cómo puedes escribir “¡¡Hola mundo!!” en este artículo. Hay muchos otros artículos en línea para eso. I am going the explain current stage of computer hardware-software and why we need new language like Go? Porque si no hay ningún problema, entonces no necesitamos solución, ¿verdad?
En este artículo, no voy a enseñarte cómo escribir “¡¡Hola mundo!!”. Ya existen muchos artículos similares en Internet. “Voy a explicar ahora por qué necesitamos un nuevo lenguaje como Go en la etapa actual de hardware y software”. Porque si no hay problemas, entonces no necesitamos una solución, ¿verdad?
#####Limitaciones de hardware: La ley de Moore está fallando. El primer procesador Pentium 4 con una velocidad de reloj de 3,0 GHz fue presentado en 2004 por Intel. Hoy, mi Mackbook Pro 2016 tiene una velocidad de reloj de 2,9 GHz. Así pues, en casi una década, no se ha ganado demasiado en potencia de procesamiento en bruto. Puede ver la comparación del aumento de la potencia de procesamiento con el tiempo en el siguiente cuadro.
摩尔定律失效了
Intel lanzó el primer procesador Pentium 4 con una velocidad de reloj de 3,0 GHz en 2004. Hoy, mi Mackbook Pro 2016 tiene una velocidad de reloj de 2,9 GHz. Por lo tanto, durante casi diez años, la potencia de procesamiento en bruto no ha mejorado mucho. Puede ver el aumento en la potencia de procesamiento en función del tiempo en el siguiente gráfico.
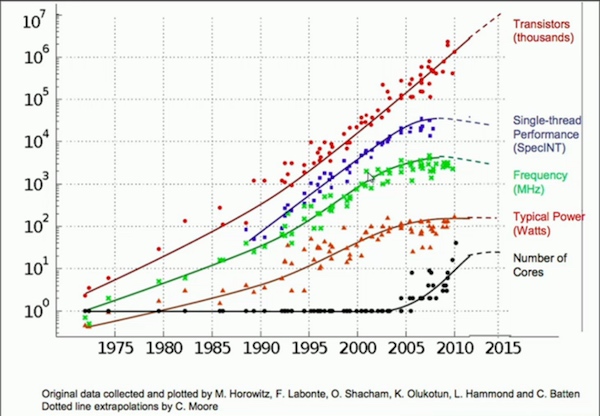
En el gráfico anterior se puede ver que el rendimiento de un solo subproceso y la frecuencia del procesador se mantuvieron estables durante casi una década. Si estás pensando que añadir más transistores es la solución, estás equivocado. Esto se debe a que a menor escala comienzan a surgir algunas propiedades cuánticas (como la creación de túneles) y a que en realidad cuesta más colocar más transistores (¿por qué?) y la cantidad de transistores que se pueden agregar por dólar comienza a disminuir.
Como puede ver en el gráfico anterior, el rendimiento de un solo subproceso y la frecuencia del procesador se han mantenido estables durante casi una década. Si crees que añadir más transistores es la solución, estás equivocado. Esto se debe a que a escalas más pequeñas, algunas propiedades cuánticas comienzan a aparecer (como la creación de túneles) y a que poner más transistores en realidad cuesta más por qué, y la cantidad de transistores que se pueden agregar por dólar comienza a disminuir.
Entonces, para la solución del problema anterior, Entonces, la solución al problema anterior es la siguiente,
- Los fabricantes comenzaron a agregar cada vez más núcleos al procesador. Hoy en día tenemos disponibles CPU de cuatro y ocho núcleos.
- Los fabricantes comenzaron a agregar cada vez más núcleos a los procesadores. Hoy en día tenemos disponibles CPU de cuatro y ocho núcleos.
- También introdujimos hyper-threading.
- También presentamos Hyper-Threading.
- Se agregó más caché al procesador para aumentar el rendimiento.
- Se agregó más caché al procesador para mejorar el rendimiento.
Pero las soluciones anteriores también tienen sus propias limitaciones. No podemos agregar más y más caché al procesador para aumentar el rendimiento, ya que el caché tiene límites físicos: cuanto mayor es el caché, más lento se vuelve. Agregar más núcleos al procesador también tiene su costo. Además, eso no puede escalar indefinidamente. Estos procesadores multinúcleo pueden ejecutar múltiples subprocesos simultáneamente y eso aporta simultaneidad al panorama. Lo discutiremos más tarde.
Pero las soluciones anteriores también tienen sus propias limitaciones. No podemos agregar más y más caché al procesador para mejorar el rendimiento porque el caché tiene limitaciones físicas: cuanto mayor es el caché, más lento se vuelve. Añadir más núcleos a un procesador también tiene sus costes. Y esto no se escala infinitamente. Estos procesadores multinúcleo pueden ejecutar varios subprocesos simultáneamente, lo que aporta simultaneidad a las imágenes. Lo discutiremos más tarde.Entonces, si no podemos confiar en las mejoras de hardware, el único camino a seguir es un software más eficiente para aumentar el rendimiento. Pero, lamentablemente, los lenguajes de programación modernos no son muy eficientes. Por tanto, si no podemos confiar en las mejoras del hardware, la única salida es mejorar el rendimiento del software. Pero, lamentablemente, los lenguajes de programación modernos no son muy eficientes.
“Modern processors are a like nitro fueled funny cars, they excel at the quarter mile. Unfortunately modern programming languages are like Monte Carlo, they are full of twists and turns.” — David Ungar
“现代处理器就像硝基燃料有趣的汽车,他们擅长四分之一英里。 不幸的是,现代编程语言就像蒙特卡罗,它们充满了曲折。“ - David Ungar
¡¡Go tiene gorutinas!!
Como comentamos anteriormente, los fabricantes de hardware están agregando cada vez más núcleos a los procesadores para aumentar el rendimiento. Todos los centros de datos funcionan con esos procesadores y deberíamos esperar un aumento en la cantidad de núcleos en los próximos años. Más aún, las aplicaciones actuales utilizan múltiples microservicios para mantener conexiones de bases de datos, colas de mensajes y mantener cachés. Por lo tanto, el software que desarrollamos y los lenguajes de programación deben admitir la concurrencia fácilmente y deben ser escalables con una mayor cantidad de núcleos.
Como se mencionó anteriormente, los fabricantes de hardware están agregando cada vez más núcleos a los procesadores para mejorar el rendimiento. Todos los centros de datos funcionan con estos procesadores y esperamos que el número de núcleos aumente en los próximos años. Es más, las aplicaciones actuales utilizan múltiples microservicios para mantener conexiones de bases de datos, colas de mensajes y cachés. Por lo tanto, el software y los lenguajes de programación que desarrollemos deberían admitir fácilmente la concurrencia y deberían ser escalables a medida que aumenta el número de núcleos.
Pero la mayoría de los lenguajes de programación modernos (como Java, Python, etc.) provienen del entorno de subproceso único de los años 90. La mayoría de esos lenguajes de programación admiten subprocesos múltiples. Pero el verdadero problema viene con la ejecución concurrente, el bloqueo de subprocesos, las condiciones de carrera y los puntos muertos. Esas cosas dificultan la creación de una aplicación multiproceso en esos idiomas.
Sin embargo, la mayoría de los lenguajes de programación modernos como Java, Python, etc. provienen del entorno de subproceso único de los años 90. La mayoría de los lenguajes de programación admiten subprocesos múltiples. Pero los verdaderos problemas son la ejecución concurrente, el bloqueo de subprocesos, las condiciones de carrera y los puntos muertos. Estas cosas dificultan la creación de aplicaciones multiproceso en estos lenguajes.
Por ejemplo, crear un nuevo hilo en Java no es una memoria eficiente. Como cada subproceso consume aproximadamente 1 MB del tamaño del montón de memoria y, eventualmente, si comienza a girar miles de subprocesos, ejercerán una presión tremenda sobre el montón y provocarán el cierre debido a la falta de memoria. Además, si quieres comunicarte entre dos o más hilos, es muy difícil. Por ejemplo, crear un nuevo hilo en Java no es eficiente en cuanto a memoria. Debido a que cada subproceso consume aproximadamente 1 MB del tamaño del montón de memoria y, eventualmente, si comienza a girar miles de subprocesos, ejercerán una gran presión sobre el montón y provocarán cierres debido a memoria insuficiente. Además, si desea comunicarse entre dos o más hilos, es muy difícil.
Por otro lado, Go fue lanzado en 2009 cuando ya estaban disponibles los procesadores multinúcleo. Es por eso que Go se creó teniendo en cuenta la simultaneidad. Go tiene rutinas en lugar de subprocesos. Consumen casi 2 KB de memoria del montón. Por lo tanto, puedes crear millones de gorutinas en cualquier momento.
Go, por otro lado, se lanzó en 2009, cuando ya estaban disponibles los procesadores multinúcleo. Es por eso que Go se creó teniendo en cuenta la simultaneidad. Go tiene rutinas en lugar de subprocesos. Consumen alrededor de 2 KB de memoria del montón. De modo que puedes crear millones de gorutinas en cualquier momento.
 ¿Cómo funcionan las gorutinas? Francia: http://golangtutorials.blogspot.in/2011/06/goroutines.html
¿Cómo funcionan las gorutinas? Francia: http://golangtutorials.blogspot.in/2011/06/goroutines.html
Otros beneficios son:
- Las gorutinas tienen pilas segmentadas que se pueden crecer. Eso significa que utilizarán más memoria sólo cuando sea necesario.
- Las gorutinas tienen pilas segmentadas que se pueden crecer. Esto significa que sólo utilizan más memoria cuando es necesario.
- Las gorutinas tienen un tiempo de inicio más rápido que los subprocesos.
- Las gorutinas tienen un tiempo de inicio más rápido que los subprocesos.
- Las gorutinas vienen con primitivas integradas para comunicarse de forma segura entre sí (canales).
- Las gorutinas vienen con primitivas integradas para comunicarse de forma segura entre ellas (canales).
- Las gorutinas le permiten evitar tener que recurrir al bloqueo mutex al compartir estructuras de datos.
- Las gorutinas le permiten evitar el uso de bloqueos mutex al compartir estructuras de datos.
- Además, las rutinas y los subprocesos del sistema operativo no tienen mapeo 1:1. Una sola rutina puede ejecutarse en varios subprocesos. Las gorutinas se multiplexan en una pequeña cantidad de subprocesos del sistema operativo.
- Además, no existe un mapeo 1:1 entre gorutinas y subprocesos del sistema operativo. Una sola rutina puede ejecutarse en varios subprocesos. Las gorutinas se multiplexan en una pequeña cantidad de subprocesos del sistema operativo.
You can see Rob Pike’s excellent talk [concurrency is not parallelism](https://blog.golang.org/concurrency-is-not-parallelism) to get more deep understanding on this.
Todos los puntos anteriores hacen que Go sea muy poderoso para manejar la concurrencia como Java, C y C++ mientras mantiene el código de ejecución de concurrencia simple y hermoso como Erlang. Los puntos anteriores hacen que Go sea muy poderoso. Puede ser tan eficiente como Java, C y C++ cuando maneja operaciones concurrentes y tan hermoso como Erlang.
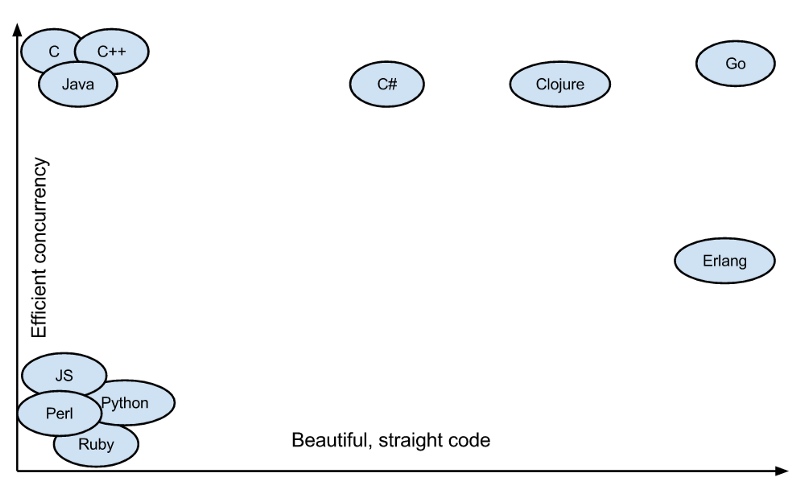 Go se lleva el bien de ambos mundos. Fácil de escribir concurrentemente y eficiente para administrar la concurrencia
Go sobresale en ambos mundos. Concurrencia fácil de escribir y gestión eficiente de la concurrencia
Go se lleva el bien de ambos mundos. Fácil de escribir concurrentemente y eficiente para administrar la concurrencia
Go sobresale en ambos mundos. Concurrencia fácil de escribir y gestión eficiente de la concurrencia
#####Go se ejecuta directamente en el hardware subyacente(Go se ejecuta directamente en el hardware subyacente). Uno de los beneficios más considerables de usar C, C++ sobre otros lenguajes modernos de nivel superior como Java/Python es su rendimiento. Porque C/C++ se compila y no se interpreta. Uno de los mayores beneficios de usar C, C++ es su rendimiento en comparación con otros lenguajes modernos de alto nivel como Java/Python. Porque C/C++ se compila, no se interpreta.Los procesadores entienden los binarios. Generalmente, cuando crea una aplicación utilizando Java u otros lenguajes basados en JVM, cuando compila su proyecto, compila el código legible por humanos en código de bytes que puede ser entendido por JVM u otras máquinas virtuales que se ejecutan sobre el sistema operativo subyacente. Durante la ejecución, VM interpreta esos códigos de bytes y los convierte a archivos binarios que los procesadores puedan entender. El procesador entiende archivos binarios. Por lo general, cuando se crea una aplicación utilizando Java u otros lenguajes basados en JVM, al compilar el proyecto, se compila código legible por humanos en código de bytes que puede ser entendido por la JVM u otra máquina virtual que se ejecuta sobre el sistema operativo subyacente. Cuando se ejecuta, la VM interpreta estos códigos de bytes y los convierte en binarios que el procesador puede entender.
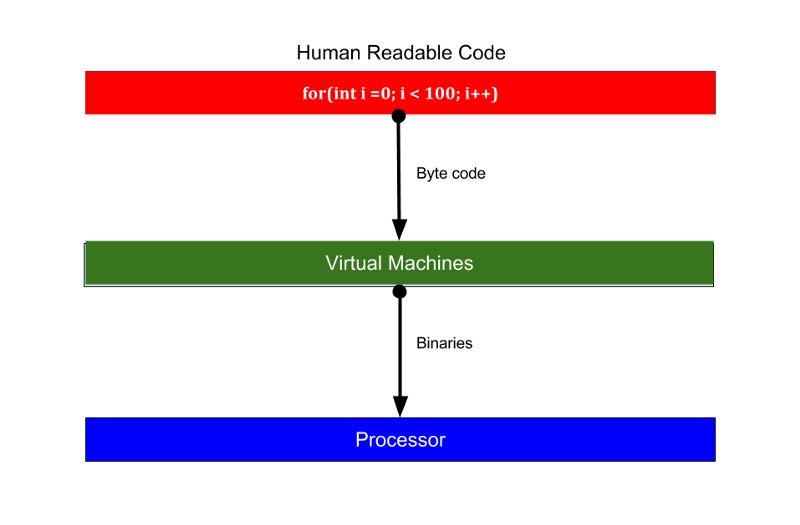 Pasos de ejecución para lenguajes basados en VM
Pasos de ejecución para lenguajes basados en VM
Mientras que, por otro lado, C/C++ no se ejecuta en máquinas virtuales y eso elimina un paso del ciclo de ejecución y aumenta el rendimiento. Compila directamente el código legible por humanos en binarios.
C/C++, por otro lado, no se ejecuta en la VM y elimina este paso del ciclo de ejecución y mejora el rendimiento. Compila código legible por humanos directamente en binarios.
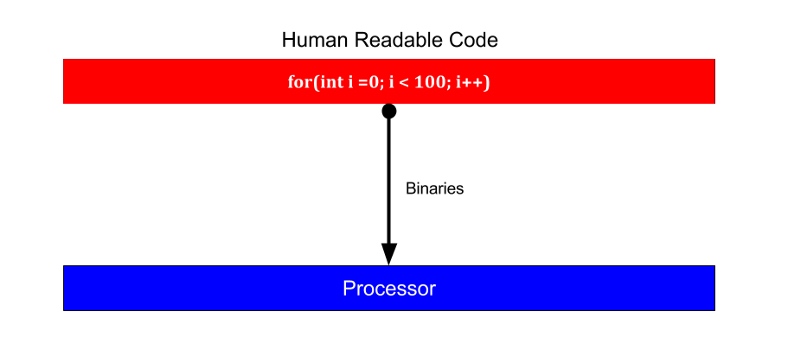
Pero liberar y asignar variables en esos lenguajes es una gran molestia. Si bien la mayoría de los lenguajes de programación manejan la asignación y eliminación de objetos mediante algoritmos de recolector de basura o conteo de referencias. Sin embargo, liberar y asignar variables es una gran molestia en estos lenguajes. Si bien la mayoría de los lenguajes de programación utilizan un recolector de basura o un algoritmo de recuento de referencias para manejar la creación y liberación de objetos.
Go trae lo mejor de ambos mundos. Al igual que los lenguajes de nivel inferior como C/C++, Go es un lenguaje compilado. Eso significa que el rendimiento está casi más cerca de los lenguajes de nivel inferior. También utiliza la recolección de basura para la asignación y eliminación del objeto. Entonces, ¡¡¡no más declaraciones malloc() y free() !!! ¡¡¡Fresco!!! Go trae lo mejor de ambos mundos. Al igual que los lenguajes de bajo nivel como C/C++, Go es un lenguaje compilado. Esto significa que el rendimiento es casi cercano al de los lenguajes de nivel inferior. También utiliza la recolección de basura para asignar y eliminar objetos. Entonces, ¡no más declaraciones malloc() y free()! ¡Fresco! ! !
#####El código escrito en Go es fácil de mantener (el código escrito en Go es fácil de mantener). Déjame decirte una cosa. Go no tiene una sintaxis de programación loca como la que tienen otros lenguajes. Tiene una sintaxis muy ordenada y limpia. Déjame decirte algo. Go no tiene una sintaxis de programación loca como otros lenguajes. Tiene una sintaxis muy ordenada y clara.
Los diseñadores de Go en Google tenían esto en mente cuando crearon el lenguaje. Como Google tiene una base de código muy grande y miles de desarrolladores estaban trabajando en esa misma base de código, el código debería ser fácil de entender para otros desarrolladores y un segmento de código debería tener un efecto secundario mínimo en otro segmento del código. Eso hará que el código sea fácilmente mantenible y fácil de modificar. Los diseñadores de Go tenían esto en mente cuando crearon el lenguaje en Google. Dado que Google tiene una base de código muy grande con miles de desarrolladores trabajando en la misma base de código, el código debe ser fácil de entender para otros desarrolladores y una sección del código debe tener efectos secundarios mínimos en otra sección del código. Esto hará que el código sea mantenible y fácil de modificar.
Go omite intencionalmente muchas características de los lenguajes OOP modernos. Go omite intencionalmente muchas características de los lenguajes OOP modernos.
*Sin clases. Todo está dividido únicamente en paquetes. Go solo tiene estructuras en lugar de clases.
- Sin clase. Todo está dividido únicamente en paquetes. Go solo tiene estructuras, no clases.
Does not support inheritance. Eso hará que el código sea fácil de modificar. En otros lenguajes como Java/Python, si la clase ABC hereda la clase XYZ y usted realiza algunos cambios en la clase XYZ, eso puede producir algunos efectos secundarios en otras clases que heredan XYZ. Al eliminar la herencia, Go también facilita la comprensión del código (ya que no hay una superclase que mirar mientras se mira un fragmento de código). *不支持继承. Esto hará que el código sea fácil de modificar. En otros lenguajes como Java/Python, si la clase ABC hereda la clase XYZ y realiza algunos cambios en la clase XYZ, esto puede tener algunos efectos secundarios en otras clases que heredan de XYZ. Al eliminar la herencia, Go hace que sea más fácil entender el código (ya que no hay una superclase a la que mirar cuando se mira un fragmento de código).- Sin constructores. *Sin anotaciones. *Sin genéricos.
- Sin excepciones.
Los cambios anteriores hacen que Go sea muy diferente de otros lenguajes y hacen que la programación en Go sea diferente de otros. Puede que no te gusten algunos puntos anteriores. Pero no es que no puedas codificar tu aplicación sin las características anteriores. Todo lo que tienes que hacer es escribir 2 o 3 líneas más. Pero en el lado positivo, hará que su código sea más limpio y le agregará más claridad. Los cambios anteriores hacen que Go sea muy diferente de otros lenguajes, y la programación en Go también es diferente de otros lenguajes. Puede que no te gusten algunos de los puntos anteriores. Sin embargo, no puede codificar su aplicación sin las características anteriores. Todo lo que tienes que hacer es escribir 2-3 líneas más. Pero en el lado positivo, hará que su código sea más limpio y le agregará más claridad.
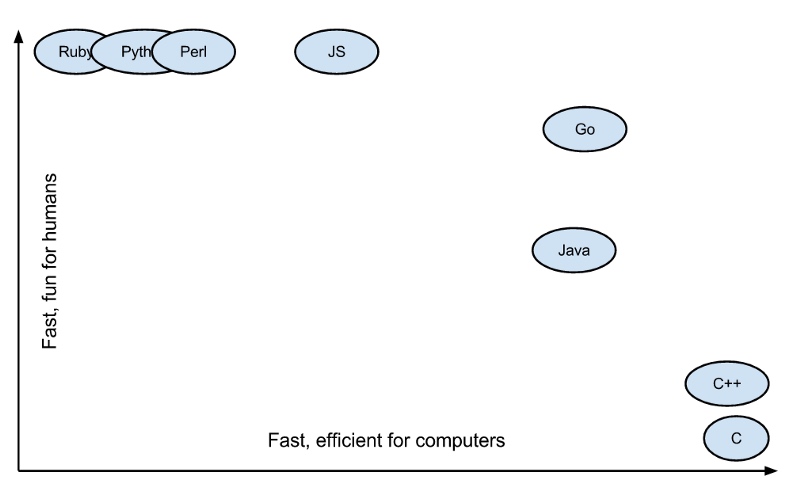 Legibilidad del código versus eficiencia.
Legibilidad del código versus eficiencia.
El gráfico anterior muestra que Go es casi tan eficiente como C/C++, manteniendo la sintaxis del código simple como Ruby, Python y otros lenguajes. ¡¡¡Esa es una situación beneficiosa tanto para los humanos como para los procesadores!!! La imagen de arriba muestra que Go es casi tan eficiente como C/C++ y mantiene la sintaxis del código simple como Ruby, Python y otros lenguajes. ¡Es una situación beneficiosa tanto para los humanos como para los procesadores!
A diferencia de otros lenguajes nuevos como Swift, la sintaxis de Go es muy estable. Se mantuvo igual desde la versión pública inicial 1.0, allá por el año 2012. Eso lo hace compatible con versiones anteriores. A diferencia de otros lenguajes nuevos como Swift, la sintaxis de Go es muy estable. No ha cambiado desde el lanzamiento público inicial de 1.0 en 2012. Esto lo hace compatible con versiones anteriores.##### Go está respaldado por Google. (Go está respaldado por Google).
- Sé que esto no es una ventaja técnica directa. Pero Go está diseñado y respaldado por Google. Google tiene una de las infraestructuras de nube más grandes del mundo y está escalada enormemente. Go está diseñado por Google para resolver sus problemas de soporte de escalabilidad y efectividad. Esos son los mismos problemas que enfrentará al crear sus propios servidores. *Sé que esto no es una ventaja técnica directa. Sin embargo, Go está diseñado y respaldado por Google. Google tiene una de las infraestructuras de nube más grandes del mundo y es enorme. Go fue diseñado por Google para resolver los problemas de soporte de escalabilidad y efectividad. Estas son las mismas preguntas que enfrentará al crear su propio servidor.
- Más aún, algunas grandes empresas como Adobe, BBC, IBM, Intel e incluso Medium también utilizan Go. (Fuente: https://github.com/golang/go/wiki/GoUsers)
- Lo que es más importante es que Go también lo utilizan algunas grandes empresas, como Adobe, BBC, IBM, Intel e incluso Medium. (Fuente: https://github.com/golang/go/wiki/GoUsers)
Conclusión:
- Aunque Go es muy diferente de otros lenguajes orientados a objetos, sigue siendo la misma bestia. Go le proporciona un alto rendimiento como C/C++, manejo de concurrencia súper eficiente como Java y programación divertida como Python/Perl.
- Aunque Go es muy diferente de otros lenguajes orientados a objetos, sigue siendo la misma bestia. Go le ofrece un alto rendimiento como C/C++, procesamiento concurrente ultraeficiente como Java y el placer de codificar como Python/Perl.
- Si no tiene planes de aprender Go, aún diré que el límite de hardware nos presiona a nosotros, los desarrolladores de software, para escribir código súper eficiente. El desarrollador debe comprender el hardware y optimizar su programa en consecuencia. El software optimizado puede ejecutarse en hardware más barato y más lento (como dispositivos IoT) y, en general, tener un mejor impacto en la experiencia del usuario final.
- Si no tiene planes de aprender Go, aún así diría que las limitaciones del hardware nos presionan como desarrolladores de software para escribir código súper eficiente. Los desarrolladores deben comprender el hardware y optimizar sus programas en consecuencia. El software optimizado puede ejecutarse en hardware más barato y más lento (como dispositivos IoT) y, en general, tener un mejor impacto en la experiencia del usuario final.
Consejo
Cómo recopilar registros de fallos a través de la aplicación en línea
-
Utilice NSSetUncaughtExceptionHandler, una función lista para usar proporcionada en el SDK de iOS. NSSetUncaughtExceptionHandler se utiliza para el manejo de excepciones. El uso es el siguiente:
//异常回调方法 void UncaughtExceptionHandler(NSException *exception) { NSArray *arr = [exception callStackSymbols]; NSString *reason = [exception reason]; NSString *name = [exception name]; NSLog(@"%@\n%@\n%@",arr, reason, name); } - (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions { // Override point for customization after application launch. NSSetUncaughtExceptionHandler(&UncaughtExceptionHandler);//注册异常回调方法 NSArray *arr = @[@(0), @(1)]; NSLog(@"%@", arr[2]); //模拟越界异常 return YES; }Una cosa a la que debe prestar atención al usarlo es que cuando coexisten varios servicios de recopilación de registros de fallos, por ejemplo, el SDK de terceros utilizado en el proyecto puede tener su propio servicio de recopilación de fallos integrado. Cuando hay varios servicios de recopilación de Crash, se producirá competencia, lo que provocará que algunos servicios de Crash no funcionen correctamente. Si varias partes registran controladores de excepciones a través de NSSetUncaughtExceptionHandler al mismo tiempo, el enfoque pacífico es: el registrante posterior utilizará NSGetUncaughtExceptionHandler para sacar y hacer una copia de seguridad del controlador previamente registrado por otros, y después de que se procese su propio controlador, registrará conscientemente los controladores de otras personas y los transmitirá de manera ordenada. La consecuencia de no pasar la anulación forzada es que el registro de fallos escrito por el servicio de recopilación de registros registrado anteriormente perderá el seguimiento de la última excepción y otra información porque no puede obtener la excepción NSException. (P.D. El Crash Reporter que viene con el sistema iOS no se ve afectado) Durante la fase de desarrollo y prueba, puede utilizar el marco [anzuelo] (https://github.com/facebook/fishhook) para conectar el método NSSetUncaughtExceptionHandler, de modo que pueda ver claramente dónde se interrumpe el proceso de entrega del controlador y localizar rápidamente a los contaminadores ambientales. No se recomienda utilizar el depurador para agregar puntos de interrupción simbólicos para verificar porque algunos marcos de recopilación de fallas no funcionan en estado de depuración.
Ejemplo de código de detección:
static NSUncaughtExceptionHandler *g_vaildUncaughtExceptionHandler; static void (*ori_NSSetUncaughtExceptionHandler)( NSUncaughtExceptionHandler * ); void my_NSSetUncaughtExceptionHandler( NSUncaughtExceptionHandler * handler) { g_vaildUncaughtExceptionHandler = NSGetUncaughtExceptionHandler(); if (g_vaildUncaughtExceptionHandler != NULL) { NSLog(@"UncaughtExceptionHandler=%p",g_vaildUncaughtExceptionHandler); } ori_NSSetUncaughtExceptionHandler(handler); NSLog(@"%@",[NSThread callStackSymbols]); g_vaildUncaughtExceptionHandler = NSGetUncaughtExceptionHandler(); NSLog(@"UncaughtExceptionHandler=%p",g_vaildUncaughtExceptionHandler); }El párrafo anterior está extraído de - Hablando sobre iOS Crash Collection Framework: http://www.cocoachina.com/ios/20150701/12301.html
-
Al usar la señal, NSSetUncaughtExceptionHandler no puede manejar todas las excepciones. Para fallas causadas por EXC_BAD_ACCESS, NSSetUncaughtExceptionHandler no tiene poder. En este caso, es necesario utilizar una señal para manejarlo. ¿Qué es la señal?
En informática, las señales son un método restringido de comunicación entre procesos en Unix, sistemas similares a Unix y otros sistemas operativos compatibles con POSIX. Es un mecanismo de notificación asincrónico que se utiliza para recordar al proceso que ha ocurrido un evento. Cuando se envía una señal a un proceso, el sistema operativo interrumpe el flujo normal de control del proceso. En este momento, se interrumpirán todas las operaciones no atómicas. Si el proceso define un controlador de señales, se ejecutará; de lo contrario, se ejecutará el controlador predeterminado.
El método de uso es el mismo que el anterior, que también se logra registrando devoluciones de llamada. 1 Registrarse
void InstallUncaughtExceptionHandler(void){ //设置信号类型的异常处理 signal(SIGABRT, HandleSignal); signal(SIGILL, HandleSignal); signal(SIGSEGV, HandleSignal); signal(SIGFPE, HandleSignal); signal(SIGBUS, HandleSignal); signal(SIGPIPE, HandleSignal); } void HandleSignal(int signal){ int32_t exceptionCount= OSAtomicIncrement32(&exceptionCount); if (exceptionCount>exceptionMaximum) { return; } NSMutableDictionary *userInfo=[NSMutableDictionary dictionaryWithObject:[NSNumber numberWithInt:signal] forKey:UncaughtExceptionHandlerSignalKey]; NSArray *callBack=[UncaughtExceptionHandler backtrace]; [userInfo setObject:callBack forKey:UncaughtExceptionHandlerAddressesKey]; UncaughtExceptionHandler *uncaughtExceptionHandler=[[UncaughtExceptionHandler alloc] init]; NSException *signalException=[NSException exceptionWithName:UncaughtExceptionHandlerSignalExceptionName reason:[NSString stringWithFormat:@"Signal %d was raised.",signal] userInfo:userInfo]; [uncaughtExceptionHandler performSelectorOnMainThread:@selector(handleException:) withObject:signalException waitUntilDone:YES]; }Para más detalles, consulte el código: https://github.com/dandan2009/Signal
La colección iOS Crash es un gran tema. Este artículo es una introducción preliminar. Si desea profundizar, debe comprender el sistema operativo y otros conocimientos. Estudiémoslo en profundidad más adelante.
Referencia: Hablando del marco de la colección iOS Crash: http://www.cocoachina.com/ios/20150701/12301.html Análisis de fallos de iOS: https://www.jianshu.com/p/1b804426d212、http://www.qidiandasheng.com/2016/04/10/crash-xuebeng/ Análisis del registro de fallas de la aplicación iOS: http://www.cocoachina.com/industry/20130725/6677.html Captura de excepción de iOS: http://www.iosxxx.com/blog/2015-08-29-iosyi-chang-bu-huo.html Utilice la señal para permitir que la aplicación falle tranquilamente: https://www.cnblogs.com/daxiaxiaohao/p/4466097.html https://github.com/walkdianzi/DSSignalHandlerDemo
Compartir
Comparta algunos métodos de aprendizaje de inglés para estudiantes que no aprobaron CET-4, tienen una base deficiente en inglés y desean mejorar su inglés: (La mayor parte del siguiente contenido es un extracto; haga clic en el enlace correspondiente para obtener más detalles)
-
APLICACIÓN para aprender inglés: De hecho, vaya a la App Store y busque las palabras clave inglés y lectura en inglés. Hay muchas aplicaciones, algunas son de pago y otras son gratuitas. Puedes elegir según tus necesidades.
-
Sitio web para aprender inglés https://www.rong-chang.com/ http://www.bbc.co.uk/learningenglish/ https://dictionary.cambridge.org/ http://www.dictionary.com/ Artículos científicos en inglés: https://medium.com/
-
Práctica de pronunciación: Curso de símbolos fonéticos de Himalaya Lai Shixiong4. Ratón en la oreja izquierda: sugerencia de Chen Hao (consulte el curso https://time.geekbang.org/column/intro/48 Chen Hao para obtener más detalles):
- Cíñete a las palabras clave en inglés de Google en lugar de buscar en chino en Google. 2 Solo en inglés en GitHub. Escriba comentarios de código en inglés, escriba información de confirmación de código, escriba problemas y solicitudes de extracción en inglés y escriba Wiki en inglés. 3 Comprométete a ver 5 minutos de vídeos en YouTube todos los días. Hay subtítulos de máquinas relacionados en YouTube. Si no funciona, simplemente activa los subtítulos.
- Insista en utilizar un diccionario de inglés en lugar de uno de chino. Por ejemplo: Diccionario de inglés Cambridge (https://dictionary.cambridge.org/) o Dictionary.com (http://www.dictionary.com/). Puede instalar una extensión de Chrome llamada Diccionario de Google (https://chrome.google.com/webstore/detail/google-dictionary-by-goog/mgijmajocgfcbeboacabfgobmjgjcoja).
- Insistir en utilizar materiales didácticos en inglés en lugar de chinos. Por ejemplo: Learning English de la BBC (http://www.bbc.co.uk/learningenglish/), o consulte algunos sitios web de ESL, como ESL: Inglés como segundo idioma (https://www.rong-chang.com/), que tiene algunos cursos. 6 Gasta dinero para tomar algunos cursos de inglés en línea y practicar con extranjeros usando videos.
-
¿Cómo aprendí inglés de tinyfool? (Cómo mejorar la comprensión auditiva, la expresión oral, la lectura y la escritura sin aprobar CET-4) (https://mp.weixin.qq.com/s?__biz=MjM5MjUwNzIyMA==&mid=207623278&idx=1&sn=051a2ecae8f0392631eb0967eefc607a#rd)摘录: Leer la documentación no requiere que tu inglés sea tan bueno como el mío. Basta con buscarlo en un diccionario. La documentación técnica contiene sólo unos pocos cientos de palabras. No es necesario que lo memorices en absoluto. Simplemente búscalo cada vez que no entiendas algo. Básicamente puedes dominarlo después de verlo durante una semana. Este método se ha dicho innumerables veces, y aquellos que se nieguen a probarlo seguirán siendo técnicamente analfabetos en inglés por el resto de sus vidas.
No he pasado CET-4… De todos modos, cuando miro el documento, si encuentro una palabra que no conozco, simplemente uso Google Translate… Reviso la API 3 o 5 veces y ni siquiera puedes recordarla… Solo hay unas pocas palabras técnicas…
-
Aprende mucho. Tienes que ver dramas estadounidenses que no entiendes, tienes que escuchar podcasts que no entiendes, tienes que leer libros que no entiendes, tienes que tener conversaciones con extranjeros que no puedes entender y tienes que escribir artículos en inglés que no sabes escribir bien.
-
Paso a paso. Aunque es difícil aprender, definitivamente progresarás desde lo más superficial a lo más profundo al principio, de modo que siempre tengas una sensación de logro.
-
Persiga la máxima cantidad de material. El propósito del paso a paso es nunca sentirse frustrado, por lo que puede pasar mucho tiempo viendo series de televisión estadounidenses (al menos miles de horas), escuchando podcasts (cientos de horas), diciendo tonterías a extranjeros y escribiendo artículos.
-
Mejorar gradualmente y evolucionar lentamente desde el aprendizaje del idioma en sí hasta el aprendizaje de la cultura y la comunicación con el mundo. Cuanto más profundo sea este proceso, más motivado estará para aprender.
-
No seas impaciente y no avances precipitadamente. Cada día te convertirá en un peón y no lograrás nada rápidamente. Me tomó medio año empezar a ver series de televisión estadounidenses, pero todavía las veo. Me tomó un mes escuchar el Podcast de Avance. Fueron necesarios unos meses para hablar y unos meses para escribir. Suena como una pérdida de tiempo, pero después de unos años, cuando quiero mejorar mis habilidades, siento que el tiempo que le dediqué no es mucho, muy poco, y vale mucho la pena.
-
Mantente feliz para que puedas persistir en el aprendizaje permanente. ¿Mi nivel de inglés es alto? Es mucho más alto que antes. ¿Es lo suficientemente alto? No lo suficientemente alto. Pero de lo que puedo estar orgulloso es de que ahora mi aprendizaje del inglés es un aprendizaje permanente. No importa si eres más alto que yo. La mayoría de la gente no aprende tan rápido como yo y, a diferencia de mí, que sigo aprendiendo, algún día te superaré. (Por supuesto, lo más importante es siempre perseguirse cada día para superar el ayer).
-
-
Preguntas y respuestas de Zhihu: Pero al final, descubrí que el método más eficaz es en realidad el más estúpido: leer más, escuchar más, tomar más notas, escribir más, resumir, practicar una y otra vez…
De hecho, no hay tantas formas de aprender inglés.
Si lo piensas detenidamente, muchas veces los métodos de aprendizaje llamados “más eficientes” suelen ser los menos eficientes. Porque sólo te dan satisfacción a corto plazo.
La clave para el progreso a largo plazo es si puedes persistir. Persistencia significa hacer lo mismo una y otra vez.
Y poco a poco me di cuenta
Nunca aprenderé inglés
Porque siempre hay palabras y usos que no conozco,
Pero estoy dispuesto a seguir aprendiendo hasta el último día.
Porque el aprendizaje permanente es la mejor manera de vivir para una persona.
======== https://www.zhihu.com/question/19853667/answer/134793017 Mi método es muy simple y estúpido, y debería funcionar para estudiantes que realmente aman y quieren aprender bien el inglés.
Cada vez que veo a alguien memorizando palabras seriamente, siento que esa persona no debe poder aprender bien inglés. Cuantas más palabras memorice y cuanto más seriamente las memorice, más lejos estará de la meta de convertirse en un maestro de inglés.
Recuerdo que cuando estaba en la universidad, siempre escuchaba a algunos compañeros recitar “abandonar, abandonar, a, b, a, n, d, o”, en voz alta en el pasillo.
n, a, b, a, n, d, o, n" una y otra vez. Cuanto más lo recito, más apasionado me vuelvo. Empiezo a recitarlo desde la primera página del libro de vocabulario. Puedo recitar varias páginas en una noche. Me apasiona mucho aprender. No es una pérdida de esfuerzo. Probablemente olvidaré todo al día siguiente después de volver a dormir por la noche.
Si un estudiante de primaria o de secundaria memoriza palabras como esta para aprender inglés, creo que no tiene nada de malo. Si un estudiante universitario que quiere tomar el examen CET-6 memoriza palabras como esta para prepararse para el examen, tengo muchas ganas de acercarme, quitarle los libros y darle un bocado. ¿Es esto realmente aprender inglés? Más tarde vi que las personas que memorizaban palabras tenían extremidades relativamente desarrolladas, así que abandoné la idea.
Pero quiero decirte que si sigues este método de aprendizaje para aprender inglés, entonces deberías aprender chino así. A partir de la primera página de la lista de vocabulario, debes memorizar así:
“Uno, uno, horizontal, horizontal, horizontal”.
“Dos, dos, horizontal, horizontal, horizontal”.
“Tres, tres, horizontal, horizontal, horizontal, horizontal, horizontal”.
“Cuatro, cuatro, vertical, pliegue horizontal, zurdo, diestro, horizontal, vertical, pliegue horizontal, zurdo, diestro, horizontal, vertical, pliegue horizontal, zurdo, diestro, horizontal”.
. . . . . .
Si memorizas los “fideos biang biang” de Shaanxi, creo que morirás.
¡Veamos cómo escribir la palabra biang! Realmente no es así como se aprende inglés. Nunca he visto a nadie aprender chino de esta manera, pero mucha gente aprende inglés de esta manera. Aunque el inglés y el chino son diferentes, los principios son los mismos.
Entonces, ¿cómo deberíamos aprenderlo?
De hecho, puedes imaginar cómo se aprende chino y cómo se puede aprender inglés con él.
Cuando éramos jóvenes, aprendimos a escribir caracteres chinos, escribir caracteres nuevos y reconocer palabras. Esto se puede comparar con memorizar palabras, pero son cosas que haces cuando estás en la escuela primaria. Puedes hacer esto cuando aprendes un idioma por primera vez, porque tu base es muy pobre en esta etapa y no sabes las palabras más comunes, por lo que necesitas escribir nuevas palabras y memorizarlas, pero ya estás en la escuela secundaria, estás aprendiendo chino y comienzas a escribir nuevas palabras de la lista de vocabulario de los libros de texto de la escuela primaria. ¿Cuál es el concepto de escribir nuevas palabras? Estás en la universidad y tienes que realizar el examen CET-6. Pasas la mayor parte de tu tiempo estudiando inglés memorizando palabras. No creo que puedas aprender inglés bien.
¿Cómo aprendemos chino en la escuela secundaria?
Leer, leer y volver a leer, en inglés es leer, leer y leer, escribir, escribir y volver a escribir, en inglés es escribir, escribir y escribir.
Algunas personas definitivamente me refutarán y dirán, ¿cómo puedo leer si no conozco las palabras?
Puede encontrar algunos artículos que le resulten adecuados para leer y leer mucho. Durante el proceso de lectura, seguramente encontrarás muchas palabras que no conoces. También encontrará palabras desconocidas o que no comprende durante la lectura en chino. Esto es normal. ¿Qué deberías hacer? Simplemente búscalo en el diccionario y luego continúa leyendo. A medida que aumenta su volumen de lectura, encontrará que los artículos de este nivel requieren que busque cada vez menos palabras y luego cambiará a un artículo de alto nivel para leer. Sigue haciendo esto. Cuando su volumen de lectura en inglés alcance un cierto nivel, su vocabulario aumentará naturalmente.
¿Entiendes lo que quiero decir? No memorices palabras, será demasiado aburrido recordarlas. Lee mucho, lee como loco. Cuando tu lectura alcance un cierto nivel, excepto escuchar y hablar, tu inglés pasará.
Tengo miedo de que mi inglés se deteriore si algún día me olvido de leer en inglés, por eso mi teléfono siempre está en modo inglés. A veces la gente quiere usar mi teléfono pero no pueden.
Aprender inglés es tan simple y tan estúpido. https://www.zhihu.com/question/26677313/answer/230847636?group_id=892423340218806272
=======
Muchos de los contenidos anteriores son extractos. Para más detalles, haga clic en el enlace correspondiente: Para resumir el método anterior, no le tengas miedo al inglés, pero apréndelo con esfuerzo. El significado de aprender aquí es atreverse a leer artículos en inglés y no darse por vencido. Cuando encuentres palabras que no conoces, debes buscar activamente el diccionario en lugar de rendirte. No debería ser doloroso. Una vez que sientas que aprender inglés es doloroso, debes dejar de aprender. Realmente, el efecto debe ser muy pobre en este momento.
De hecho, mi puntuación en inglés durante el examen de ingreso a la universidad pasó de una puntuación baja de 30 a más de 100. ¿Cómo mejoré en ese momento? En realidad estaba leyendo. Cuando leía, buscaba palabras en el diccionario y luego las memorizaba. Memorizar palabras leyendo artículos es mucho mejor que memorizar palabras solo. Si la base no es buena, puede comenzar primero con artículos simples y luego aumentar gradualmente la dificultad. En el caso de artículos técnicos, puedes leer la mayoría de ellos con la ayuda de Google Translate. Depende de si puedes persistir. Mientras puedas persistir durante medio año y leer tres artículos en inglés a la semana, creo que tu habilidad en inglés 读 también mejorará.
=======
What to read next
Want more posts about ARTS?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #iOS?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home