Structure des données 2 – Comparaison rapide
Structures de données — Une comparaison rapide (partie 2)
Structures de données — Une comparaison rapide (Partie 2) Structures de données 2-Comparaison rapide
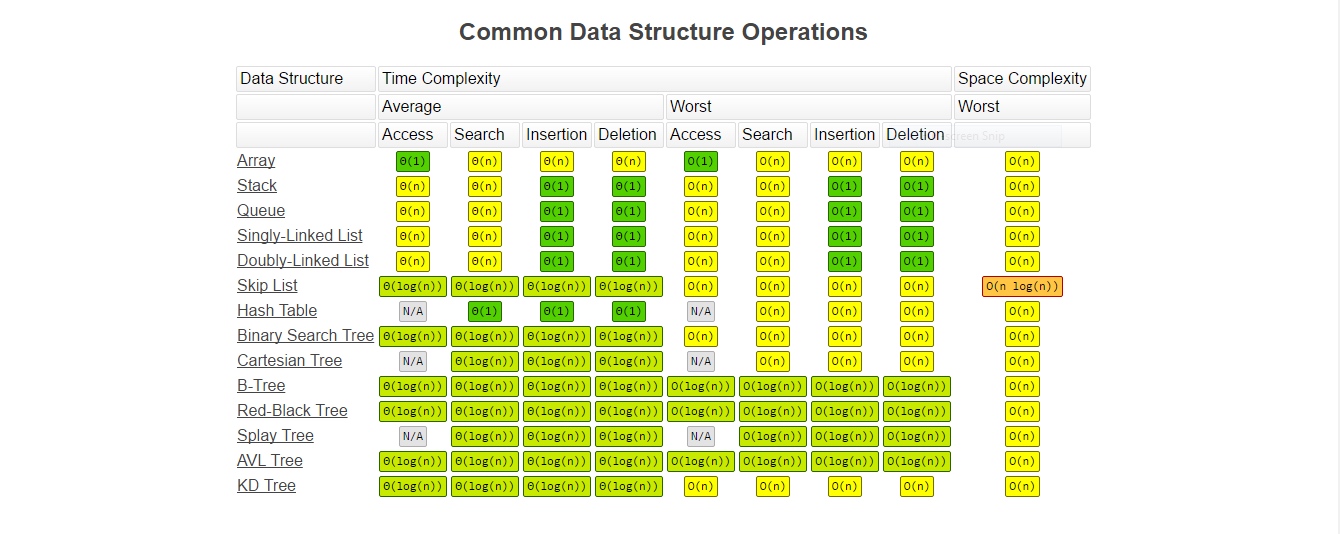
Comparaison entre différentes structures de données — bigochheatsheet.com Comparaison entre différentes structures de données - bigochheatsheet.com
Chaque structure de données a sa propre manière ou son algorithme différent pour trier, insérer, rechercher,… etc. Cela est dû à la nature de la structure des données. Il existe des algorithmes utilisés avec une structure de données spécifique, alors que d’autres ne peuvent pas être utilisés. Chaque structure de données possède ses propres méthodes ou algorithmes pour trier, insérer, rechercher, etc. Cela est dû à la nature de la structure de données. Certains algorithmes ont des structures de données spécifiques que d’autres algorithmes ne peuvent pas utiliser.
Plus l’algorithme est efficace & adapté, plus vous aurez une structure de données optimisée. Plus l’algorithme est efficace et approprié, plus les structures de données seront optimisées.
Il y a de fortes chances que vous vous appuyiez sur les algorithmes intégrés utilisés avec les structures de données de votre langage. Ces algorithmes sont très bien optimisés et testés au combat. Très probablement, vous vous fierez à des algorithmes intégrés qui fonctionnent avec les structures de données de votre langage. Ces algorithmes sont bien optimisés et testés.
tableaux tableau
avantages Avantages
-
Facile à créer, facile à utiliser Facile à créer, facile à utiliser
-
Indexation directe : O(1) Indexation directe : O(1)
-
Accès séquentiel : O(N) Accès séquentiel : O(N)
contre Inconvénients
-
Tri : O(NLogN) Tri : O(NLogN)
-
Recherche : O(N) et O(LogN) si trié Recherche : O(N) et O(LogN) si trié
-
Insertion et suppression : O(N) en raison du déplacement d’éléments.
liste chaînée liste chaînée
avantages Avantages
-
Insertion et suppression : O(1). Insérer et supprimer : O(1)
-
Accès séquentiel : O(N) Accès séquentiel : O(N)
Les opérations d’insertion et de suppression font référence à l’opération elle-même, car vous devrez peut-être accéder séquentiellement à tous les nœuds jusqu’au nœud que vous recherchez.
L’insertion et la suppression sont beaucoup plus faciles avec une liste doublement chaînée.
contre Inconvénients
-
Pas d’accès direct ; Uniquement accès séquentiel. Pas d’accès direct ; Uniquement accès séquentiel.
-
Recherche : O(N) Recherche : O(N)
-
Tri : O(NLogN) Tri : O(NLogN)
Piles et files d’attente Piles et files d’attente
Les piles et les files d’attente ont des objectifs très spécifiques. Les piles sont selon la structure de données du dernier entré, premier sorti (LIFO), tandis que les files d’attente sont selon la structure du premier entré, premier sorti (FIFO). Les piles et les files d’attente répondent à des objectifs très spécifiques. La pile est une structure de données dernier entré, premier sorti (LIFO), tandis que la file d’attente est une structure de données premier entré, premier sorti (FIFO).
avantages Avantages
- Pousser/Ajouter : O(1)
- Pop/Supprimer : O(1)
- Coup d’œil : O(1)
Inconvénients
Si vous essayez de faire autre chose avec des piles ou des files d’attente, par exemple si vous demandez comment puis-je extraire un élément du milieu ? Ensuite, vous devriez envisager une structure de données différente. Si vous voulez faire autre chose avec une pile ou une file d’attente, comme si vous voulez savoir comment extraire un élément du milieu ? Ensuite, vous devriez examiner les différentes structures de données.
Tables de hachage. Table de hachage
avantages Avantages
-
Insertion et suppression : O(1) + Hachage et indexation (amortis). Insertion et suppression : O(1) + Hachage et indexation (amorti).
-
Accès direct : O(1) + Hachage & Indexation. Accès direct : O(1) + Hachage et indexation.
Cela demande un peu de traitement pour le hachage et l’indexation. Mais l’avantage c’est que c’est la même quantité de traitement à chaque fois, même si la table de hachage devient très grande. Le hachage et l’indexation nécessitent un certain traitement. Mais l’avantage est que le nombre traité à chaque fois est le même, même si la table de hachage devient très grande.
Lorsque la table de hachage est pleine, sa taille augmente. Et, lorsque le nombre de buckets remplis est bien inférieur à la taille de la table de hachage, sa taille diminue alors. Les deux opérations prennent une complexité de O(N). C’est pourquoi l’insertion et la suppression prennent O(1) amorti. Lorsque la table de hachage se remplit, sa taille augmente. Lorsque le nombre de buckets remplis est bien inférieur à la taille de la table de hachage, sa taille est réduite. La complexité des deux opérations est O(N). C’est pourquoi l’insertion et la suppression nécessitent un amortissement O(1).
contre Inconvénients
-
Certaines surcharges nécessitent un peu plus d’espace mémoire que les tableaux. Certaines surcharges nécessitent un peu plus d’espace en mémoire que les tableaux.
-
La récupération des éléments ne garantit pas un ordre spécifique. La récupération des éléments ne garantit pas un ordre spécifique.
-
Rechercher une valeur (sans connaître sa clé). Rechercher une valeur (sans savoir que c’est la clé).
ensembles ensembles
pros. Avantages
-
Vérification de l’adhésion ; existence de valeur. Vérification de l’adhésion ; existence de valeur.
-
Évite les doublons éviter la duplication
La complexité de vérifier si une valeur contenue dans l’ensemble dépend de la structure de données sous-jacente utilisée pour implémenter l’ensemble.
En C++, il utilise un arbre de recherche binaire (probablement un arbre rouge noir ; un type d’arbre de recherche binaire auto-équilibré). Ainsi, la complexité serait O(LogN) et O(N) si l’arbre est déséquilibré. La complexité est O(LogN) si l’arbre est déséquilibré, la complexité est O(N)
En Java, la classe HashSet implémente l’interface Set en utilisant la structure de données de la table de hachage. La complexité serait donc la même que celle des tables de hachage (voir ci-dessus). En Java, la classe HashSet implémente l’interface Set à l’aide d’une structure de données de table de hachage. La complexité sera donc la même qu’une table de hachage (voir ci-dessus).
Inconvénients
Les ensembles sont volontairement limités. Vous ne pouvez pas faire grand-chose avec eux. Donc, ils sont terribles dans presque tout le reste. Les collections sont volontairement limitées. Vous ne pouvez rien y faire. Donc, ils sont terribles dans presque tous les autres domaines.### Arbres de recherche binaires (BST)
Avantages
- Insertion et suppression
- Vitesse d’accès
- Maintient l’ordre trié ; la récupération des éléments est en ordre.
La complexité de l’insertion, de la suppression et de l’accès serait O(LogN) et O(N) si l’arborescence est déséquilibrée.
Inconvénients
- Quelques frais généraux dus à leur création et leur gestion.
Tas
Les tas sont un type d’arbre binaire idéal pour les files d’attente prioritaires. Les tas sont un type d’arbre binaire idéal pour les files d’attente prioritaires.
Avantages
- Trouver Min/Trouver Max : O(1)
- Insertion : O(LogN)
- Supprimer Min/Supprimer Max : O (LogN)
Inconvénients
- Recherche et suppression : O(N)
En recherchant et en supprimant, nous devrons scanner tous les éléments car ils ne garantissent pas un ordre précis, contrairement à BST.
La suppression nécessite de parcourir toute l’arborescence pour accéder d’abord à l’élément, puis de le supprimer, où l’opération de suppression elle-même nécessite O(LogN).
Texte original : https://medium.com/omarelgabrys-blog/data-structures-a-quick-comparison-6689d725b3b0
What to read next
Want more posts about Algorithms?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Algorithms?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home