Les dix meilleurs algorithmes de tri classiques
Dix algorithmes de tri classiques
#Top dix des algorithmes de tri classiques (démonstration d’animation) Tiré du blog personnel de Damonare
Texte original : http://blog.damonare.cn/2016/12/20/十大经典排序算法总结(javascript描述)/
##0. Présentation de l’algorithme
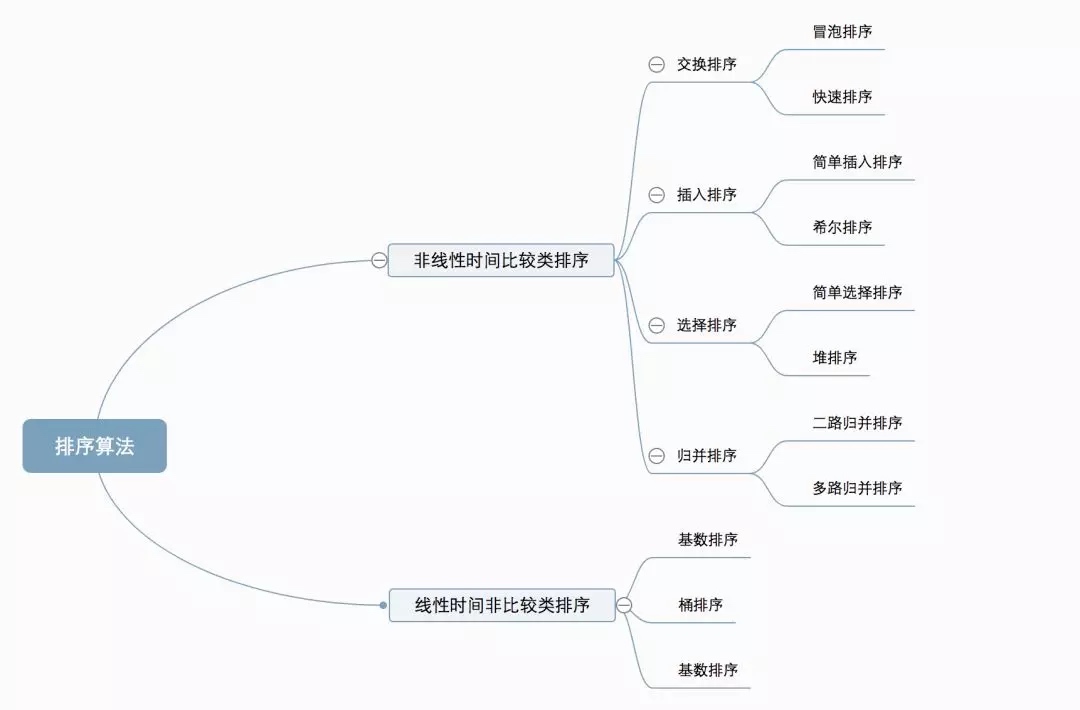
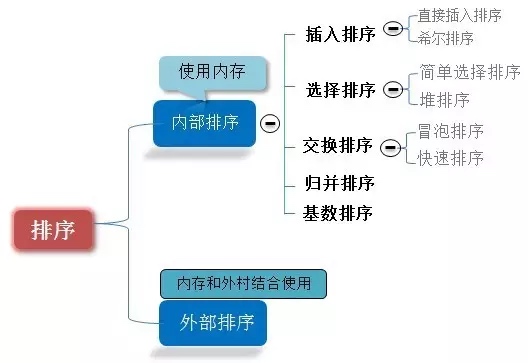
##0.1 Classification des algorithmes
Dix algorithmes de tri courants peuvent être divisés en deux grandes catégories :
Tri par comparaison temporelle non linéaire : déterminez l’ordre relatif entre les éléments par comparaison. Étant donné que sa complexité temporelle ne peut pas dépasser O(nlogn), on parle de tri par comparaison temporelle non linéaire. Tri sans comparaison temporelle linéaire : il ne détermine pas l’ordre relatif entre les éléments par comparaison. Il peut dépasser la limite inférieure de temps du tri basé sur la comparaison et s’exécuter en temps linéaire, c’est pourquoi on l’appelle tri sans comparaison en temps linéaire.
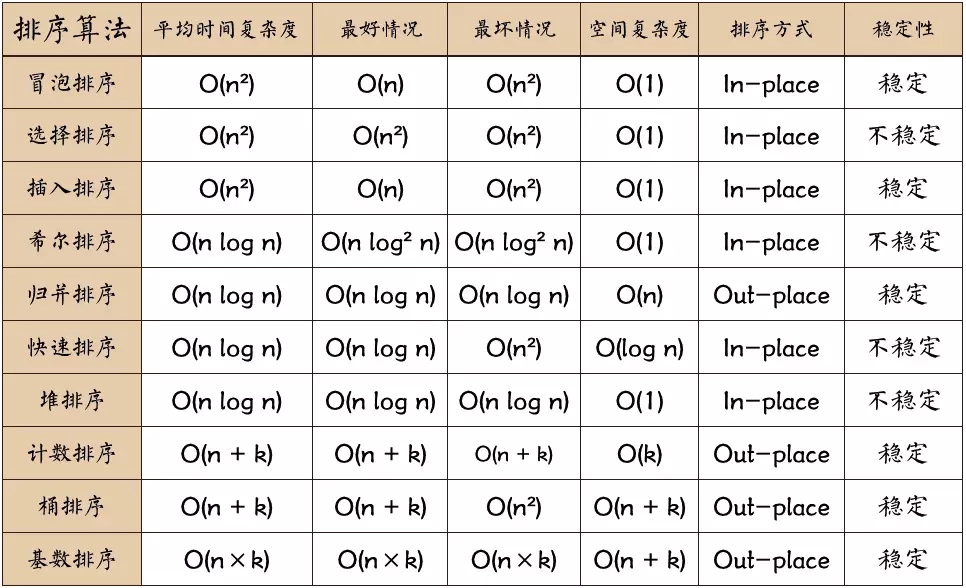
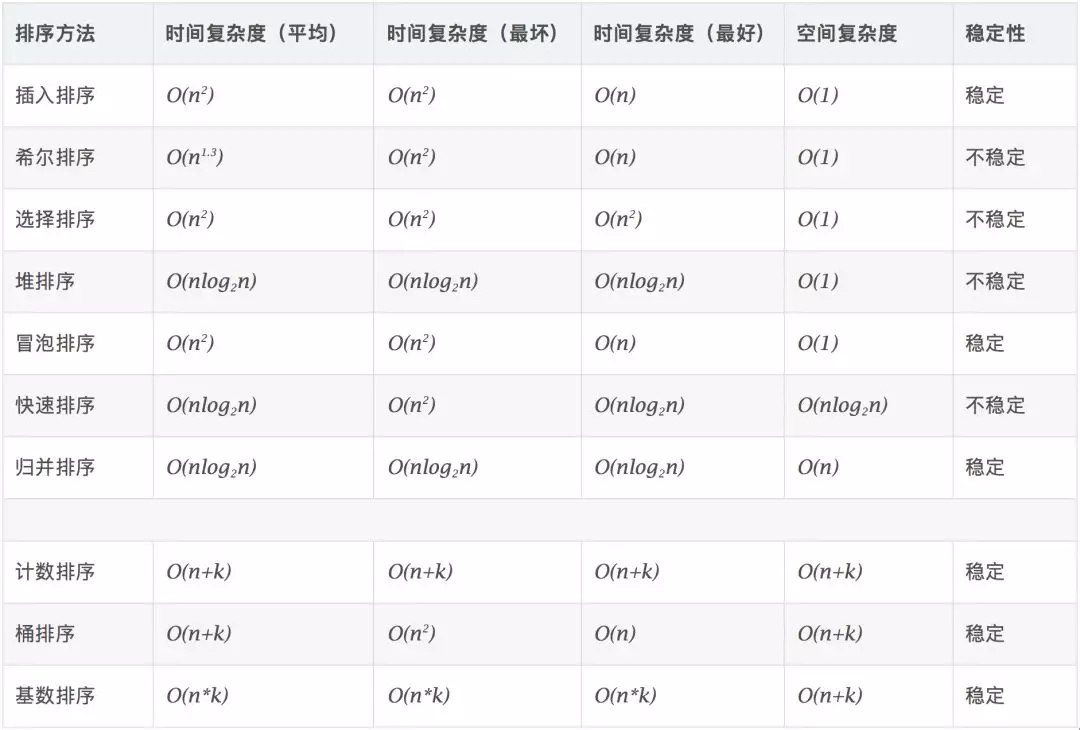
0.2 Complexité de l’algorithme
0.3 Concepts associés
Stable : si a est à l’origine devant b et a = b, a sera toujours devant b après le tri. Instable : si a est à l’origine devant b et a=b, a peut apparaître après b après le tri. Complexité temporelle : le nombre total d’opérations sur les données triées. Reflète le modèle du nombre d’opérations lorsque n change. Complexité spatiale : fait référence à la mesure de l’espace de stockage requis lorsqu’un algorithme est exécuté dans un ordinateur. C’est également fonction de la taille des données n.
1. Tri à bulles (Tri à bulles)
Le tri à bulles est un algorithme de tri simple. Il parcourt à plusieurs reprises la séquence à trier, en comparant les éléments deux à la fois et en les échangeant s’ils sont dans le mauvais ordre. Le travail de visite du tableau est répété jusqu’à ce qu’aucun échange ne soit plus nécessaire, ce qui signifie que le tableau a été trié. Le nom de cet algorithme vient du fait que les éléments plus petits « flotteront » lentement vers le haut du tableau grâce à l’échange.
1.1 Description de l’algorithme
-
Comparez les éléments adjacents. Si le premier est supérieur au second, échangez-les tous les deux ;
-
Faites le même travail pour chaque paire d’éléments adjacents, de la première paire au début à la dernière paire à la fin, de sorte que le dernier élément soit le plus grand nombre ;
-
Répétez les étapes ci-dessus pour tous les éléments sauf le dernier ;
-
Répétez les étapes 1 à 3 jusqu’à ce que le tri soit terminé.
1.2 Démonstration d’animation
1.3 Implémentation du code
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i < len - 1; i++) {
for (var j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) { // 相邻元素两两对比
var temp = arr[j+1]; // 元素交换
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
2. Tri par sélection
Le tri par sélection est un algorithme de tri simple et intuitif. Comment ça marche : recherchez d’abord le plus petit (grand) élément de la séquence non triée, stockez-le au début de la séquence triée, puis continuez à rechercher le plus petit (grand) élément parmi les éléments non triés restants, puis placez-le à la fin de la séquence triée. Et ainsi de suite jusqu’à ce que tous les éléments soient triés.
2.1 Description de l’algorithme
Le tri par sélection directe de n enregistrements peut obtenir des résultats ordonnés via n-1 passes de tri par sélection directe. L’algorithme spécifique est décrit comme suit :
- État initial : la zone non ordonnée est R[1…n], et la zone ordonnée est vide ;
- Lorsque le i-ième tri (i=1,2,3…n-1) commence, la zone ordonnée actuelle et la zone non ordonnée sont respectivement R[1…i-1] et R(i…n). Cette opération de tri sélectionne l’enregistrement R[k] avec le plus petit mot-clé de la zone non ordonnée actuelle, et l’échange avec le premier enregistrement R dans la zone non ordonnée, de sorte que R[1…i] et R[i+1…n) deviennent une nouvelle zone ordonnée avec le nombre d’enregistrements augmenté de 1 et une nouvelle zone non ordonnée avec le nombre d’enregistrements réduit de 1 respectivement ;
- A la fin de n-1 passes, le tableau est trié.
2.2 Démonstration d’animation
2.3 Implémentation du code
function selectionSort(arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i < len - 1; i++) {
minIndex = i;
for (var j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) { // 寻找最小的数
minIndex = j; // 将最小数的索引保存
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
2.4 Analyse de l’algorithme
L’un des algorithmes de tri les plus stables, car quelles que soient les données saisies, la complexité temporelle est O(n2), donc lors de son utilisation, plus la taille des données est petite, mieux c’est. Le seul avantage est peut-être qu’il n’occupe pas d’espace mémoire supplémentaire. Théoriquement parlant, le tri par sélection peut également être la méthode de tri la plus courante à laquelle la plupart des gens pensent lors du tri.
- Tri par insertion
La description de l’algorithme de tri par insertion (Insertion-Sort) est un algorithme de tri simple et intuitif. Cela fonctionne en construisant une séquence ordonnée. Pour les données non triées, il analyse d’avant en arrière dans la séquence triée, trouve la position correspondante et l’insère.
3.1 Description de l’algorithme
De manière générale, le tri par insertion est implémenté sur les tableaux en utilisant sur place. L’algorithme spécifique est décrit comme suit :
- A partir du premier élément, l’élément peut être considéré comme trié ;
- Retirez l’élément suivant et numérisez d’arrière en avant dans la séquence d’éléments triés ;
- Si l’élément (trié) est plus grand que le nouvel élément, déplacez l’élément à la position suivante ;
- Répétez l’étape 3 jusqu’à ce que vous trouviez la position où l’élément trié est inférieur ou égal au nouvel élément ;
- Après avoir inséré le nouvel élément dans cette position ;
- Répétez les étapes 2 à 5.
3.2 Démonstration GIF
3.3 Mise en œuvre du code
function insertionSort(arr) {
var len = arr.length;
var preIndex, current;
for (var i = 1; i < len; i++) {
preIndex = i - 1;
current = arr[i];
while (preIndex >= 0 && arr[preIndex] > current) {
arr[preIndex + 1] = arr[preIndex];
preIndex--;
}
arr[preIndex + 1] = current;
}
return arr;
}
3.4 Analyse de l’algorithme
Dans l’implémentation du tri par insertion, le tri sur place est généralement utilisé (c’est-à-dire un tri qui utilise uniquement l’espace supplémentaire O(1)). Par conséquent, pendant le processus de numérisation d’arrière en avant, les éléments triés doivent être décalés à plusieurs reprises et progressivement vers l’arrière pour fournir un espace d’insertion pour les éléments les plus récents.
- Tri des coquilles
Inventé par Shell en 1959, il s’agit du premier algorithme de tri à franchir O(n2) et une version améliorée du tri par insertion simple. Il diffère du tri par insertion dans la mesure où il compare en premier les éléments les plus éloignés. Le tri en colline est également appelé tri par incrément réducteur.
4.1 Description de l’algorithme
Tout d’abord, la séquence d’enregistrement entière à trier est divisée en plusieurs sous-séquences pour un tri par insertion directe. L’algorithme spécifique est décrit :
Sélectionnez une séquence incrémentielle t1, t2,…,tk, où ti>tj, tk=1 ;
Trier la séquence k fois en fonction du nombre de séquences incrémentales k ;
A chaque passe de tri, la colonne à trier est divisée en plusieurs sous-séquences de longueur m selon l’incrément ti correspondant, et un tri par insertion directe est effectué sur chaque sous-table. Ce n’est que lorsque le facteur d’incrémentation est de 1 que la séquence entière est traitée comme un tableau et que la longueur du tableau est la longueur de la séquence entière.
4.2 Démonstration GIF
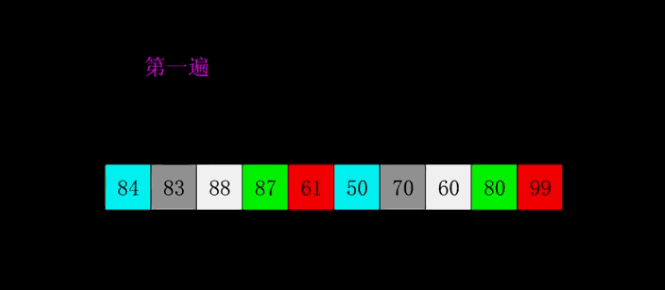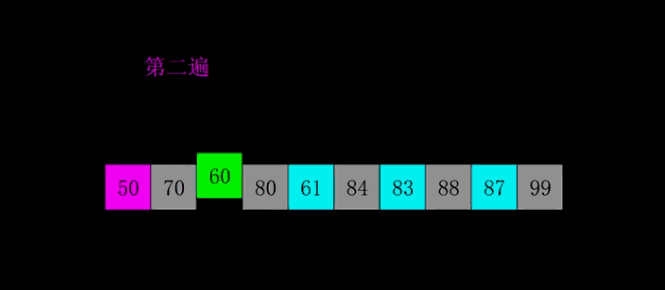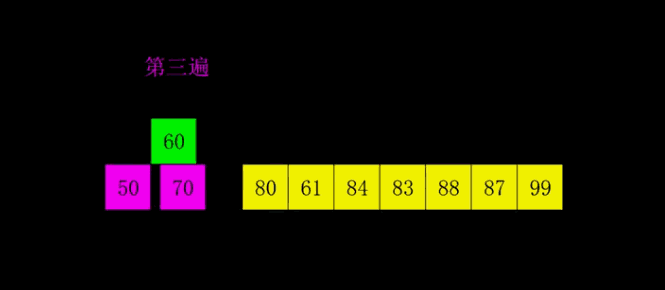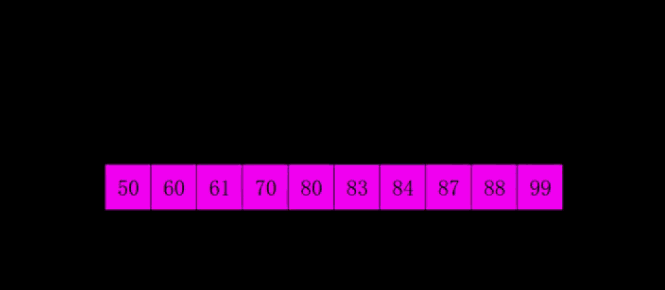
4.3 Mise en œuvre du code
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while (gap < len / 3) { // 动态定义间隔序列
gap = gap * 3 + 1;
}
for (gap; gap > 0; gap = Math.floor(gap / 3)) {
for (var i = gap; i < len; i++) {
temp = arr[i];
for (var j = i-gap; j > 0 && arr[j]> temp; j-=gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
}
}
return arr;
}
4.4 Analyse de l’algorithme
Le cœur du tri Hill réside dans la définition de la séquence d’intervalles. La séquence d’intervalles peut être définie à l’avance ou définie dynamiquement. L’algorithme permettant de définir dynamiquement des séquences d’intervalles a été proposé par Robert Sedgewick, co-auteur de “Algorithms (4th Edition)”.
- Fusionner le tri
Le tri par fusion est un algorithme de tri efficace basé sur des opérations de fusion. Cet algorithme est une application très typique utilisant la méthode diviser pour régner (Divide and Conquer). Fusionnez les sous-séquences déjà ordonnées pour obtenir une séquence complètement ordonnée ; c’est-à-dire qu’il faut d’abord rendre chaque sous-séquence ordonnée, puis ordonner les segments de la sous-séquence. Si deux listes ordonnées sont fusionnées en une seule liste ordonnée, on parle de fusion bidirectionnelle.
5.1 Description de l’algorithme
Divisez la séquence d’entrée de longueur n en deux sous-séquences de longueur n/2 ;
Utilisez le tri par fusion sur ces deux sous-séquences ;
Fusionnez deux sous-séquences triées en une séquence triée finale.
5.2 Démonstration GIF
5.3 Mise en œuvre du code
function mergeSort(arr) { // 采用自上而下的递归方法
var len = arr.length;
if (len < 2) {
return arr;
}
var middle = Math.floor(len / 2),
left = arr.slice(0, middle),
right = arr.slice(middle);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
var result = [];
while (left.length>0 && right.length>0) {
if (left[0] <= right[0])="" {<="" span="">
result.push(left.shift());
} else {
result.push(right.shift());
}
}
while (left.length)
result.push(left.shift());
while (right.length)
result.push(right.shift());
return result;
}
5.4 Analyse de l’algorithme
Le tri par fusion est une méthode de tri stable. Comme le tri par sélection, les performances du tri par fusion ne sont pas affectées par les données d’entrée, mais ses performances sont bien meilleures que celles du tri par sélection car la complexité temporelle est toujours O(nlogn). Le prix est un espace mémoire supplémentaire.
- Tri rapide
L’idée de base du tri rapide est de séparer les enregistrements à trier en deux parties indépendantes grâce à un seul tri. Si les mots-clés d’une partie de l’enregistrement sont plus petits que les mots-clés de l’autre partie, alors les deux parties des enregistrements peuvent être triées séparément pour obtenir l’ordre de la séquence entière.
6.1 Description de l’algorithme
Le tri rapide utilise la méthode diviser pour régner pour diviser une liste en deux sous-listes. L’algorithme spécifique est décrit comme suit :
La sélection d’un élément de la séquence est appelée un « pivot » ;
Réorganisez le tableau de sorte que tous les éléments plus petits que la valeur de base soient placés devant la base et que tous les éléments plus grands que la valeur de base soient placés derrière la base (le même nombre peut aller de chaque côté). Une fois cette partition terminée, la base se trouve au milieu de la séquence. C’est ce qu’on appelle une opération de partition ;
Triez de manière récursive le sous-tableau d’éléments inférieurs à la valeur de base et le sous-tableau d’éléments supérieurs à la valeur de base.
6.2 Démonstration GIF
6.3 Mise en œuvre du code
function quickSort(arr, left, right) {
var len = arr.length,
partitionIndex,
left = typeof left != 'number' ? 0 : left,
right = typeof right != 'number' ? len - 1 : right;
if (left < right) {
partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex-1);
quickSort(arr, partitionIndex+1, right);
}
return arr;
}
function partition(arr, left ,right) { // 分区操作
var pivot = left, // 设定基准值(pivot)
index = pivot + 1;
for (var i = index; i <= right;="" i++)="" {<="" span="">
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index-1;
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
- Tri en tas
Heapsort fait référence à un algorithme de tri conçu en utilisant la structure de données d’un tas. L’empilement est une structure qui se rapproche d’un arbre binaire complet et satisfait aux propriétés de l’empilement : c’est-à-dire que la valeur clé ou l’index d’un nœud enfant est toujours plus petit (ou plus grand) que son nœud parent.
7.1 Description de l’algorithme
Construire la séquence initiale de mots-clés à trier (R1, R2…Rn) dans un grand tas supérieur, qui est la zone non ordonnée initiale ;
Échangez l’élément supérieur R[1] avec le dernier élément R[n], puis obtenez une nouvelle zone non ordonnée (R1, R2,…Rn-1) et une nouvelle zone ordonnée (Rn), et satisfaisez R[1,2…n-1]<=r[n];< span=“”></=r[n];<>
Étant donné que le nouveau sommet R[1] du tas après l’échange peut violer les propriétés du tas, il est nécessaire d’ajuster la zone désordonnée actuelle (R1, R2,…Rn-1) dans un nouveau tas, puis d’échanger à nouveau R[1] avec le dernier élément de la zone désordonnée pour obtenir une nouvelle zone désordonnée (R1, R2…Rn-2) et une nouvelle zone ordonnée (Rn-1, Rn). Ce processus est répété jusqu’à ce que le nombre d’éléments dans la zone ordonnée soit n-1, puis l’ensemble du processus de tri est terminé.
7.2 Démonstration GIF

7.3 Mise en œuvre du code
var len; // 因为声明的多个函数都需要数据长度,所以把len设置成为全局变量
function buildMaxHeap(arr) { // 建立大顶堆
len = arr.length;
for (var i = Math.floor(len/2); i >= 0; i--) {
heapify(arr, i);
}
}
function heapify(arr, i) { // 堆调整
var left = 2 * i + 1,
right = 2 * i + 2,
largest = i;
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest);
}
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function heapSort(arr) {
buildMaxHeap(arr);
for (var i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0);
}
return arr;
}
- Tri par comptage
Le tri par comptage n’est pas un algorithme de tri basé sur une comparaison. Son cœur réside dans la conversion des valeurs des données d’entrée en clés et dans leur stockage dans un espace de tableau supplémentaire ouvert. En tant que tri à complexité temporelle linéaire, le tri par comptage nécessite que les données d’entrée soient des nombres entiers compris dans une certaine plage.
8.1 Description de l’algorithme
Rechercher les éléments les plus grands et les plus petits du tableau à trier ;
Comptez le nombre d’occurrences de chaque élément de valeur i dans le tableau et stockez-le dans le i-ème élément du tableau C ;
Accumuler tous les comptes (à partir du premier élément en C, chaque élément est ajouté à l’élément précédent) ;
Remplissez le tableau cible à l’envers : placez chaque élément i dans le C(i)ème élément du nouveau tableau et soustrayez 1 de C(i) pour chaque élément placé.
8.2 Démonstration GIF
8.3 Mise en œuvre du code
function countingSort(arr, maxValue) {
var bucket = new Array(maxValue + 1),
sortedIndex = 0;
arrLen = arr.length,
bucketLen = maxValue + 1;
for (var i = 0; i < arrLen; i++) {
if (!bucket[arr[i]]) {
bucket[arr[i]] = 0;
}
bucket[arr[i]]++;
}
for (var j = 0; j < bucketLen; j++) {
while(bucket[j] > 0) {
arr[sortedIndex++] = j;
bucket[j]--;
}
}
return arr;
}
8.4 Analyse de l’algorithme
Le tri par comptage est un algorithme de tri stable. Lorsque les éléments d’entrée sont n entiers compris entre 0 et k, la complexité temporelle est O(n+k) et la complexité spatiale est également O(n+k). Sa vitesse de tri est plus rapide que n’importe quel algorithme de tri par comparaison. Le tri par comptage est un algorithme de tri très efficace lorsque k n’est pas très grand et que les séquences sont relativement concentrées.
- Tri par seau
Le tri par compartiments est une version améliorée du tri par comptage. Il utilise la relation de mappage des fonctions. La clé de l’efficacité réside dans la détermination de cette fonction de cartographie. Le principe de fonctionnement du tri par buckets : supposer que les données d’entrée obéissent à une distribution uniforme, diviser les données en un nombre limité de buckets, puis trier chaque bucket séparément (il est possible d’utiliser d’autres algorithmes de tri ou de continuer à utiliser le tri par buckets de manière récursive).
9.1 Description de l’algorithme
Définissez un tableau quantitatif comme un seau vide ;
Parcourez les données d’entrée et placez les données dans les compartiments correspondants une par une ;
Triez chaque seau qui n’est pas vide ;
Concaténez les données triées à partir de compartiments qui ne sont pas vides.9.2 Démonstration d’images
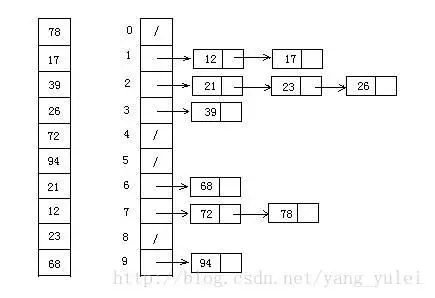
9.3 Mise en œuvre du code
function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i < arr.length; i++) {
if (arr[i] < minValue) {
minValue = arr[i]; // 输入数据的最小值
} else if (arr[i] > maxValue) {
maxValue = arr[i]; // 输入数据的最大值
}
}
// 桶的初始化
var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
// 利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++) {
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++) {
insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序
for (var j = 0; j < buckets[i].length; j++) {
arr.push(buckets[i][j]);
}
}
return arr;
}
9.4 Analyse de l’algorithme
Le tri par seau utilise le temps linéaire O(n) dans le meilleur des cas. La complexité temporelle du tri des compartiments dépend de la complexité temporelle du tri des données entre les compartiments, car la complexité temporelle des autres parties est O(n). Évidemment, plus les compartiments sont petits, moins il y a de données entre chaque compartiment et moins le tri prend du temps. Mais la consommation d’espace correspondante va augmenter.
- Tri par base
Le tri Radix consiste à trier d’abord par ordre faible, puis à collecter ; puis trier par ordre élevé, puis collecter ; et ainsi de suite, jusqu’à l’ordre le plus élevé. Parfois, certains attributs ont un ordre de priorité, triés d’abord par faible priorité, puis par haute priorité. L’ordre final est que ceux qui ont une priorité plus élevée viennent en premier, et ceux qui ont la même priorité élevée et une priorité inférieure viennent en premier.
10.1 Description de l’algorithme
Obtenez le nombre maximum dans le tableau et obtenez le nombre de chiffres ;
arr est le tableau d’origine, et chaque bit est extrait du bit le plus bas pour former le tableau de bases ;
Effectuer un tri par comptage sur base (en utilisant la fonctionnalité de tri par comptage adapté aux petits nombres de plage) ;
10.2 Démonstration GIF

10.3 Mise en œuvre du code
// LSD Radix Sort
var counter = [];
function radixSort(arr, maxDigit) {
var mod = 10;
var dev = 1;
for (var i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {
for(var j = 0; j < arr.length; j++) {
var bucket = parseInt((arr[j] % mod) / dev);
if(counter[bucket]==null) {
counter[bucket] = [];
}
counter[bucket].push(arr[j]);
}
var pos = 0;
for(var j = 0; j < counter.length; j++) {
var value = null;
if(counter[j]!=null) {
while ((value = counter[j].shift()) != null) {
arr[pos++] = value;
}
}
}
}
return arr;
}
10.4 Analyse de l’algorithme
Le tri Radix est basé sur un tri séparé et une collecte séparée, il est donc stable. Cependant, les performances du tri par base sont légèrement pires que celles du tri par seau. Chaque allocation de mots-clés par compartiment nécessite une complexité temporelle O(n), et l’obtention d’une nouvelle séquence de mots-clés après l’allocation nécessite une complexité temporelle O(n). Si les données à trier peuvent être divisées en d mots-clés, la complexité temporelle du tri par base sera O(d*2n). Bien sûr, d est beaucoup plus petit que n, donc c’est fondamentalement linéaire.
La complexité spatiale du tri par base est O(n+k), où k est le nombre de compartiments. Généralement n >> k, donc l’espace supplémentaire nécessite environ n.
What to read next
Want more posts about Translation?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Translation?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home