Los diez mejores algoritmos de clasificación clásicos
Diez algoritmos de clasificación clásicos
Los diez mejores algoritmos de clasificación clásicos (demostración de animación)
De: Blog personal de Damonare
Texto original: http://blog.damonare.cn/2016/12/20/十大经典排序算法总结(javascript描述)/
##0. Descripción general del algoritmo
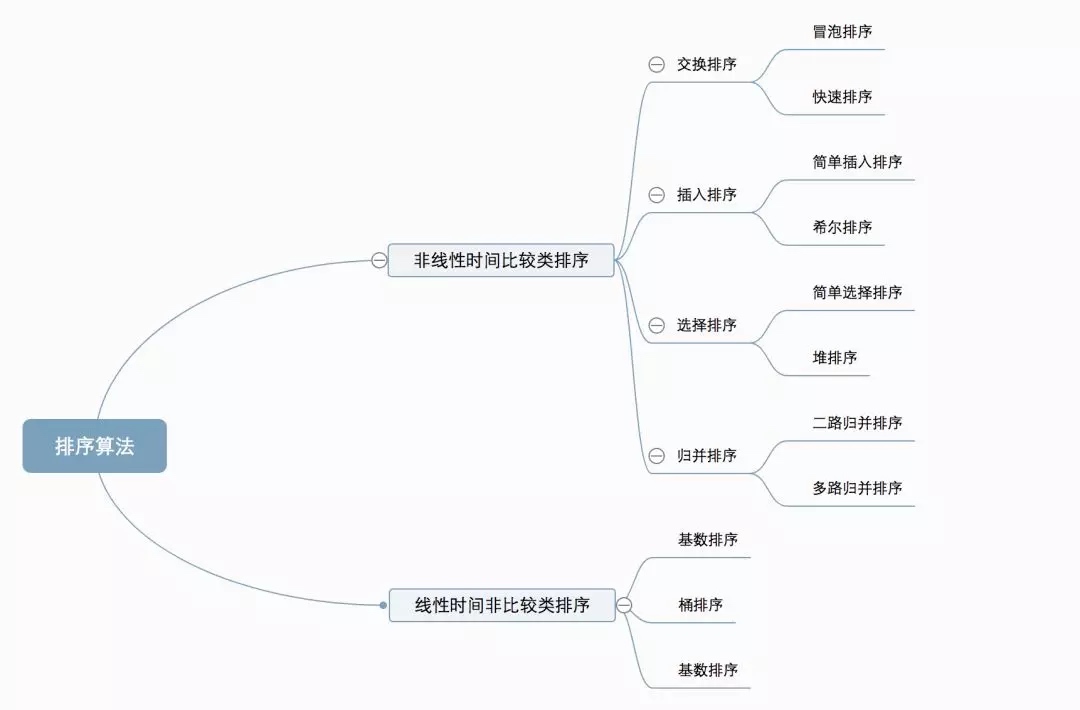
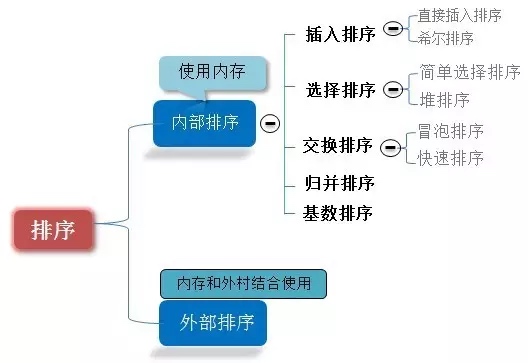
0.1 Clasificación de algoritmos
Diez algoritmos de clasificación comunes se pueden dividir en dos categorías amplias:
Clasificación de comparación de tiempo no lineal: determine el orden relativo entre elementos mediante comparación. Dado que su complejidad temporal no puede exceder O (nlogn), se denomina clasificación de comparación de tiempo no lineal. Clasificación lineal sin comparación de tiempo: no determina el orden relativo entre elementos mediante comparación. Puede superar el límite inferior de tiempo de la clasificación basada en comparación y ejecutarse en tiempo lineal, por lo que se denomina clasificación sin comparación en tiempo lineal.
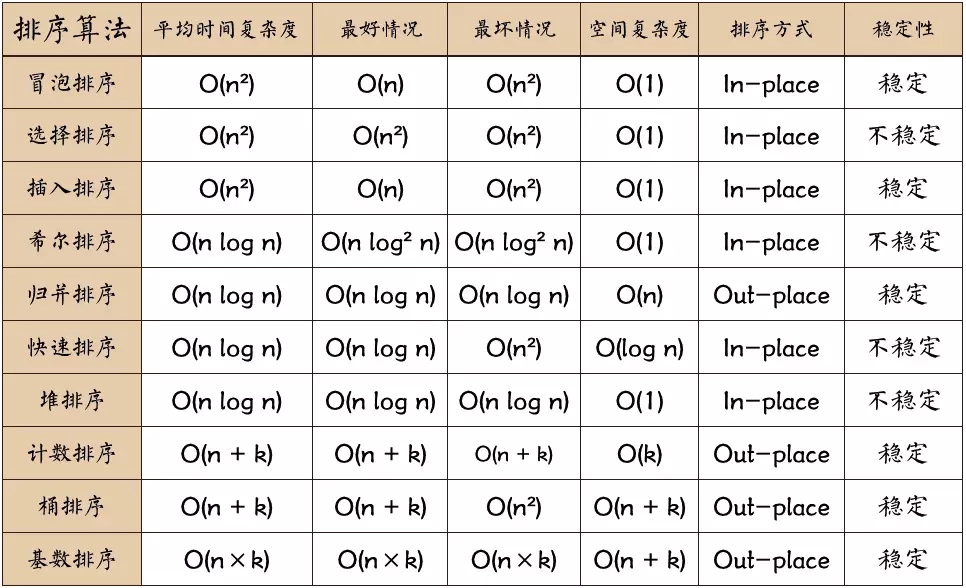
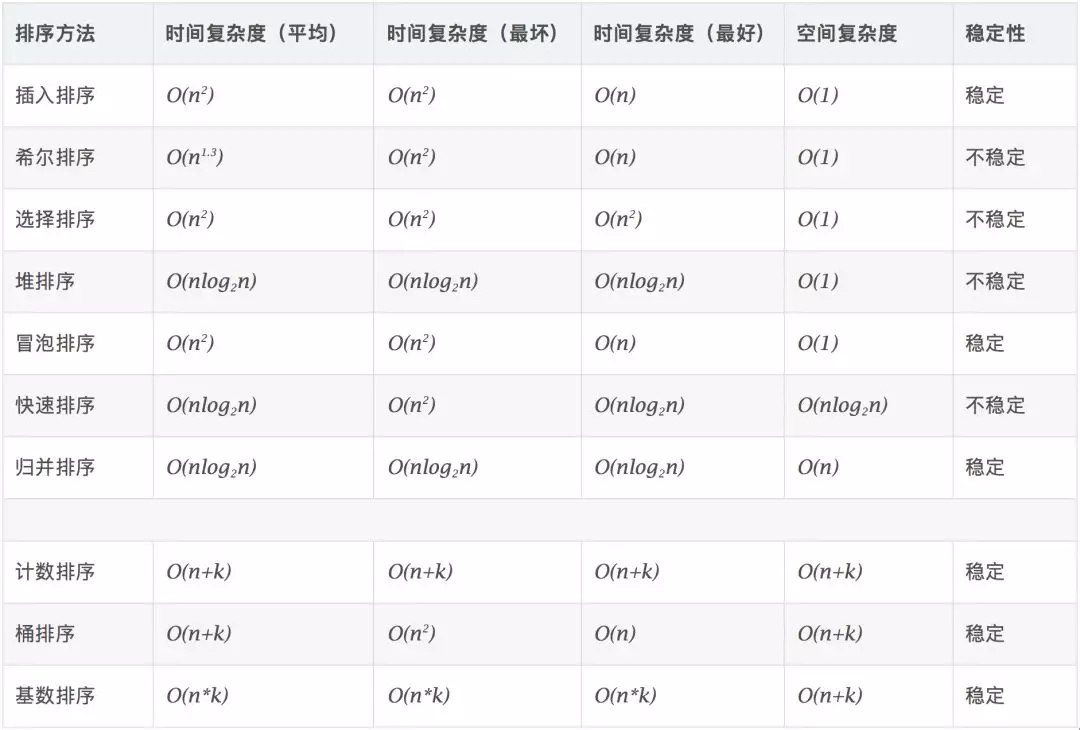
0.2 Complejidad del algoritmo
0.3 Conceptos relacionados
Estable: si a está originalmente delante de b y a = b, a seguirá estando delante de b después de la clasificación. Inestable: si a está originalmente delante de b y a = b, a puede aparecer después de b después de la clasificación. Complejidad del tiempo: el número total de operaciones en datos ordenados. Refleja el patrón del número de operaciones cuando n cambia. Complejidad del espacio: se refiere a la medición del espacio de almacenamiento requerido cuando se ejecuta un algoritmo en una computadora. También es función del tamaño de los datos n.
1. Clasificación de burbujas (Clasificación de burbujas)
La clasificación de burbujas es un algoritmo de clasificación simple. Recorre repetidamente la secuencia a ordenar, comparando elementos de dos en dos e intercambiándolos si están en el orden incorrecto. El trabajo de visitar la matriz se repite hasta que no se necesitan más intercambios, lo que significa que la matriz ha sido ordenada. El nombre de este algoritmo proviene del hecho de que los elementos más pequeños “flotarán” lentamente hasta la parte superior de la matriz mediante el intercambio.
1.1 Descripción del algoritmo
-
Compara elementos adyacentes. Si el primero es mayor que el segundo, cámbielos a ambos;
-
Haga el mismo trabajo para cada par de elementos adyacentes, desde el primer par al principio hasta el último par al final, de modo que el último elemento sea el número mayor;
-
Repita los pasos anteriores para todos los elementos excepto el último;
-
Repita los pasos 1 a 3 hasta completar la clasificación.
1.2 Demostración de animación
1.3 Implementación del código
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i < len - 1; i++) {
for (var j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) { // 相邻元素两两对比
var temp = arr[j+1]; // 元素交换
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
2. Orden de selección
La clasificación por selección es un algoritmo de clasificación simple e intuitivo. Cómo funciona: primero busque el elemento más pequeño (grande) en la secuencia sin clasificar, guárdelo al principio de la secuencia ordenada, luego continúe buscando el elemento más pequeño (grande) de los elementos restantes sin clasificar y luego colóquelo al final de la secuencia ordenada. Y así sucesivamente hasta que todos los elementos estén ordenados.
2.1 Descripción del algoritmo
La clasificación por selección directa de n registros puede obtener resultados ordenados mediante n-1 pases de clasificación por selección directa. El algoritmo específico se describe a continuación:
- Estado inicial: el área desordenada es R [1…n] y el área ordenada está vacía;
- Cuando comienza la clasificación i-ésima (i=1,2,3…n-1), el área ordenada actual y el área desordenada son R[1…i-1] y R(i…n) respectivamente. Esta operación de clasificación selecciona el registro R[k] con la palabra clave más pequeña del área desordenada actual y lo intercambia con el primer registro R en el área desordenada, de modo que R[1…i] y R[i+1…n) se conviertan en una nueva área ordenada con el número de registros aumentado en 1 y una nueva área desordenada con el número de registros reducido en 1 respectivamente;
- Al final de n-1 pases, la matriz se ordena.
2.2 Demostración de animación
2.3 Implementación del código
function selectionSort(arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i < len - 1; i++) {
minIndex = i;
for (var j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) { // 寻找最小的数
minIndex = j; // 将最小数的索引保存
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
2.4 Análisis de algoritmos
Uno de los algoritmos de clasificación más estables, porque no importa qué datos se ingresen, la complejidad del tiempo es O (n2), por lo que cuando se usa, cuanto menor sea el tamaño de los datos, mejor. La única ventaja puede ser que no ocupa espacio de memoria adicional. En teoría, la clasificación por selección también puede ser el método de clasificación más común en el que piensa la mayoría de la gente al realizar la clasificación.
- Ordenación por inserción
La descripción del algoritmo de clasificación por inserción (Insertion-Sort) es un algoritmo de clasificación simple e intuitivo. Funciona construyendo una secuencia ordenada. Para datos no clasificados, escanea de atrás hacia adelante en la secuencia ordenada, encuentra la posición correspondiente y la inserta.
3.1 Descripción del algoritmo
En términos generales, la ordenación por inserción se implementa en matrices mediante el uso in situ. El algoritmo específico se describe a continuación:
- A partir del primer elemento, se puede considerar que el elemento ha sido ordenado;
- Saque el siguiente elemento y escanee de atrás hacia adelante en la secuencia de elementos ordenados;
- Si el elemento (ordenado) es más grande que el nuevo elemento, mueva el elemento a la siguiente posición;
- Repita el paso 3 hasta encontrar la posición donde el elemento ordenado es menor o igual que el nuevo elemento;
- Después de insertar el nuevo elemento en esta posición;
- Repita los pasos 2 a 5.
3.2 demostración GIF
3.3 Implementación del código
function insertionSort(arr) {
var len = arr.length;
var preIndex, current;
for (var i = 1; i < len; i++) {
preIndex = i - 1;
current = arr[i];
while (preIndex >= 0 && arr[preIndex] > current) {
arr[preIndex + 1] = arr[preIndex];
preIndex--;
}
arr[preIndex + 1] = current;
}
return arr;
}
3.4 Análisis de algoritmos
En la implementación de la ordenación por inserción, generalmente se usa la ordenación in situ (es decir, la ordenación que solo usa O (1) espacio adicional). Por lo tanto, durante el proceso de escaneo de atrás hacia adelante, los elementos ordenados deben desplazarse hacia atrás repetida y gradualmente para proporcionar espacio de inserción para los elementos más recientes.
- Clasificación de conchas
Inventado por Shell en 1959, fue el primer algoritmo de clasificación que superó O(n2) y fue una versión mejorada de la clasificación por inserción simple. Se diferencia del ordenamiento por inserción en que compara primero los elementos que están más lejos. La clasificación por colinas también se denomina clasificación por incrementos reductores.
4.1 Descripción del algoritmo
Primero, toda la secuencia de registros que se va a ordenar se divide en varias subsecuencias para la clasificación por inserción directa. El algoritmo específico se describe:
Seleccione una secuencia incremental t1, t2,…,tk, donde ti>tj, tk=1;
Ordene la secuencia k veces según el número de secuencias incrementales k;
En cada paso de clasificación, la columna a ordenar se divide en varias subsecuencias de longitud m de acuerdo con el incremento ti correspondiente, y se realiza una clasificación por inserción directa en cada subtabla. Solo cuando el factor de incremento es 1, toda la secuencia se procesa como una tabla y la longitud de la tabla es la longitud de toda la secuencia.
4.2 demostración GIF
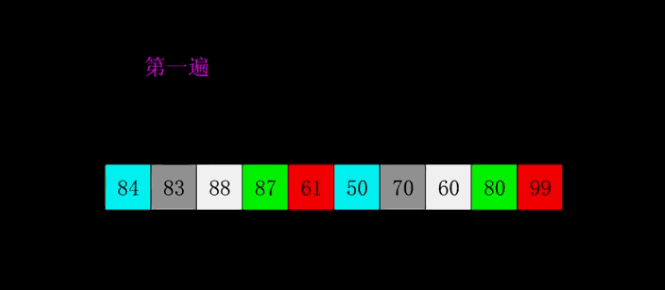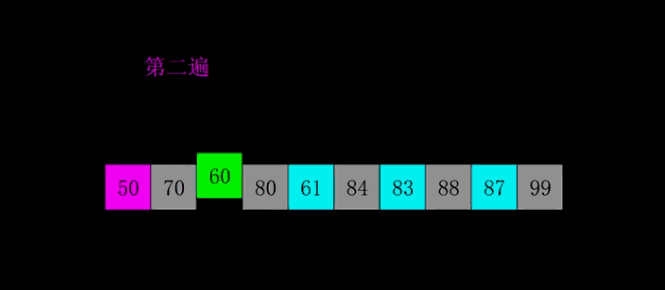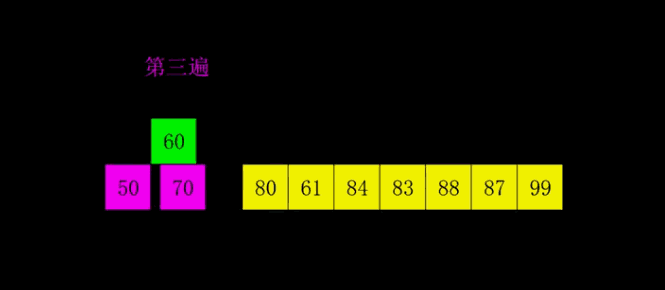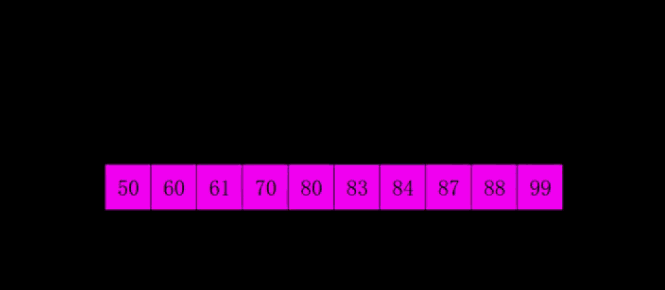
4.3 Implementación del código
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while (gap < len / 3) { // 动态定义间隔序列
gap = gap * 3 + 1;
}
for (gap; gap > 0; gap = Math.floor(gap / 3)) {
for (var i = gap; i < len; i++) {
temp = arr[i];
for (var j = i-gap; j > 0 && arr[j]> temp; j-=gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
}
}
return arr;
}
4.4 Análisis de algoritmos
El núcleo de la clasificación Hill radica en el establecimiento de la secuencia de intervalos. La secuencia de intervalos se puede establecer de antemano o definirse dinámicamente. El algoritmo para definir dinámicamente secuencias de intervalos fue propuesto por Robert Sedgewick, coautor de “Algoritmos (4ª edición)”.
- Combinar orden
Merge sort es un algoritmo de clasificación eficaz basado en operaciones de fusión. Este algoritmo es una aplicación muy típica que utiliza el método divide y vencerás (Divide y vencerás). Fusionar las subsecuencias ya ordenadas para obtener una secuencia completamente ordenada; es decir, primero ordene cada subsecuencia y luego ordene los segmentos de la subsecuencia. Si dos listas ordenadas se combinan en una lista ordenada, se denomina combinación bidireccional.
5.1 Descripción del algoritmo
Divida la secuencia de entrada de longitud n en dos subsecuencias de longitud n/2;
Utilice la clasificación por combinación en estas dos subsecuencias;
Fusiona dos subsecuencias ordenadas en una secuencia ordenada final.
5.2 demostración GIF
5.3 Implementación del código
function mergeSort(arr) { // 采用自上而下的递归方法
var len = arr.length;
if (len < 2) {
return arr;
}
var middle = Math.floor(len / 2),
left = arr.slice(0, middle),
right = arr.slice(middle);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
var result = [];
while (left.length>0 && right.length>0) {
if (left[0] <= right[0])="" {<="" span="">
result.push(left.shift());
} else {
result.push(right.shift());
}
}
while (left.length)
result.push(left.shift());
while (right.length)
result.push(right.shift());
return result;
}
5.4 Análisis de algoritmos
La clasificación por combinación es un método de clasificación estable. Al igual que la ordenación por selección, el rendimiento de la ordenación por combinación no se ve afectado por los datos de entrada, pero su rendimiento es mucho mejor que el de la ordenación por selección porque la complejidad del tiempo es siempre O (nlogn). El precio es espacio de memoria adicional.
- Clasificación rápida
La idea básica de la clasificación rápida es separar los registros que se van a clasificar en dos partes independientes mediante una sola clasificación. Si las palabras clave de una parte del registro son más pequeñas que las palabras clave de la otra parte, entonces las dos partes de los registros se pueden ordenar por separado para lograr el orden de toda la secuencia.
6.1 Descripción del algoritmo
La clasificación rápida utiliza el método de divide y vencerás para dividir una lista en dos sublistas. El algoritmo específico se describe a continuación:
Seleccionar un elemento de la secuencia se llama “pivote”;
Reordene la matriz para que todos los elementos más pequeños que el valor base se coloquen delante de la base y todos los elementos más grandes que el valor base se coloquen detrás de la base (el mismo número puede ir a cualquier lado). Una vez que sale esta partición, la base está en el medio de la secuencia. Esto se llama operación de partición;
Ordene recursivamente el subconjunto de elementos menores que el valor base y el subconjunto de elementos mayores que el valor base.
6.2 demostración GIF
6.3 Implementación del código
function quickSort(arr, left, right) {
var len = arr.length,
partitionIndex,
left = typeof left != 'number' ? 0 : left,
right = typeof right != 'number' ? len - 1 : right;
if (left < right) {
partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex-1);
quickSort(arr, partitionIndex+1, right);
}
return arr;
}
function partition(arr, left ,right) { // 分区操作
var pivot = left, // 设定基准值(pivot)
index = pivot + 1;
for (var i = index; i <= right;="" i++)="" {<="" span="">
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index-1;
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
- Ordenación del montón
Heapsort se refiere a un algoritmo de clasificación diseñado utilizando la estructura de datos de un montón. El apilamiento es una estructura que se aproxima a un árbol binario completo y satisface las propiedades del apilamiento: es decir, el valor clave o índice de un nodo secundario siempre es menor (o mayor) que su nodo principal.
7.1 Descripción del algoritmo
Construya la secuencia inicial de palabras clave que se ordenarán (R1, R2 … Rn) en un montón superior grande, que es el área desordenada inicial;
Intercambie el elemento superior R[1] con el último elemento R[n], y luego obtenga una nueva área desordenada (R1, R2,…Rn-1) y una nueva área ordenada (Rn), y satisfaga R[1,2…n-1]<=r[n];< span=“”></=r[n];<>
Dado que el nuevo R [1] superior del montón después del intercambio puede violar las propiedades del montón, es necesario ajustar el área desordenada actual (R1, R2,…Rn-1) en un nuevo montón y luego intercambiar R [1] con el último elemento del área desordenada nuevamente para obtener una nueva área desordenada (R1, R2…Rn-2) y una nueva área ordenada (Rn-1, Rn). Este proceso se repite hasta que el número de elementos en el área ordenada sea n-1, luego se completa todo el proceso de clasificación.
7.2 Demostración GIF

7.3 Implementación del código
var len; // 因为声明的多个函数都需要数据长度,所以把len设置成为全局变量
function buildMaxHeap(arr) { // 建立大顶堆
len = arr.length;
for (var i = Math.floor(len/2); i >= 0; i--) {
heapify(arr, i);
}
}
function heapify(arr, i) { // 堆调整
var left = 2 * i + 1,
right = 2 * i + 2,
largest = i;
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest);
}
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function heapSort(arr) {
buildMaxHeap(arr);
for (var i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0);
}
return arr;
}
- Ordenación por conteo
La clasificación por conteo no es un algoritmo de clasificación basado en comparaciones. Su núcleo radica en convertir los valores de los datos de entrada en claves y almacenarlos en un espacio de matriz abierto adicionalmente. Como ordenación de complejidad de tiempo lineal, la ordenación por conteo requiere que los datos de entrada sean números enteros dentro de un cierto rango.
8.1 Descripción del algoritmo
Encuentre los elementos más grandes y más pequeños en la matriz que se va a ordenar;
Cuente el número de apariciones de cada elemento con valor i en la matriz y guárdelo en el i-ésimo elemento de la matriz C;
Acumular todos los recuentos (a partir del primer elemento en C, cada elemento se suma al anterior);
Complete la matriz de destino a la inversa: coloque cada elemento i en el elemento C(i)ésimo de la nueva matriz y reste 1 de C(i) por cada elemento colocado.
8.2 demostración GIF
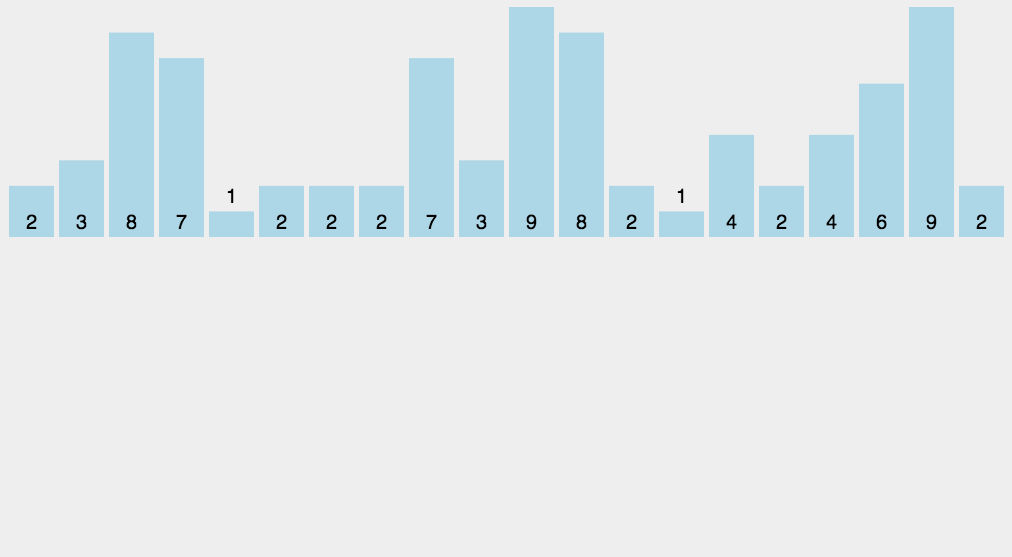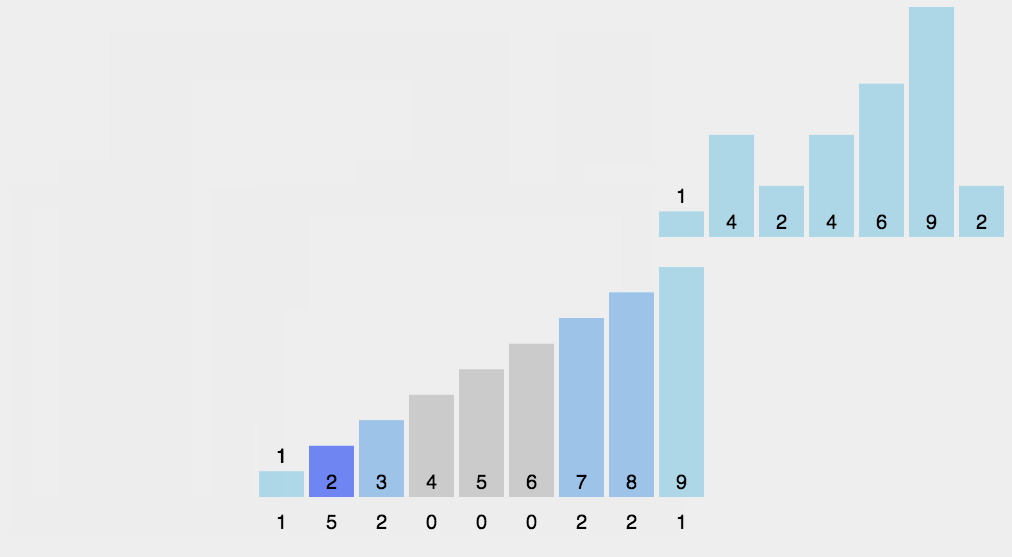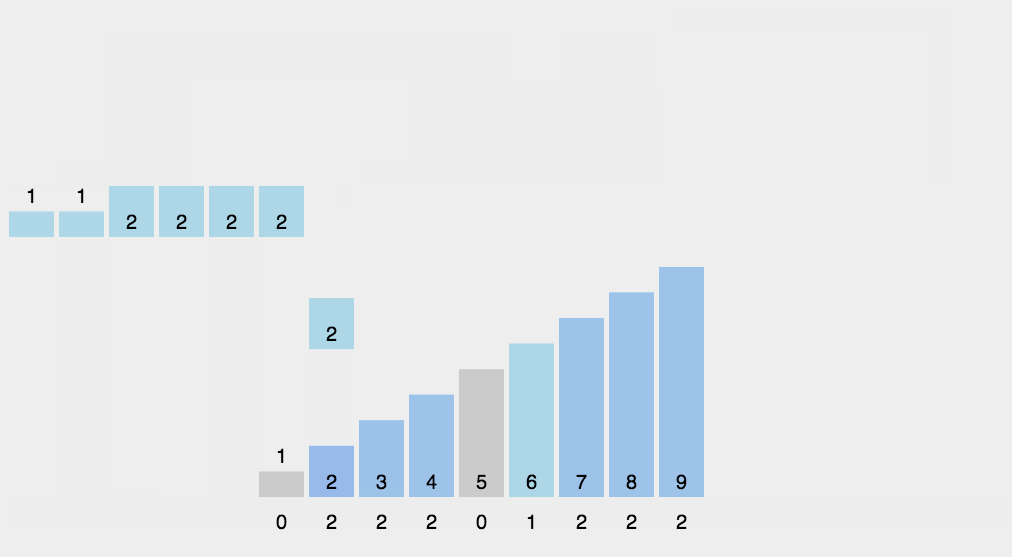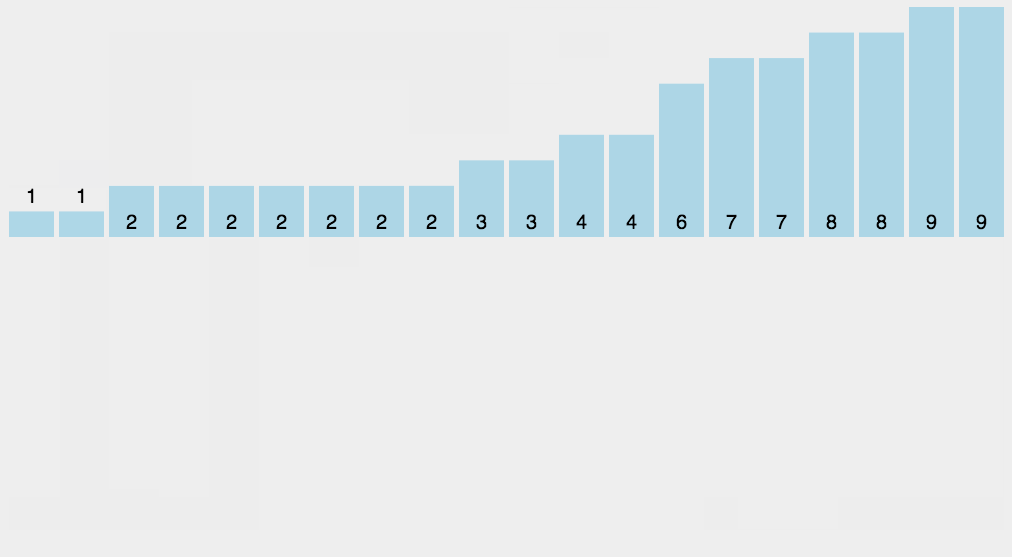
8.3 Implementación del código
function countingSort(arr, maxValue) {
var bucket = new Array(maxValue + 1),
sortedIndex = 0;
arrLen = arr.length,
bucketLen = maxValue + 1;
for (var i = 0; i < arrLen; i++) {
if (!bucket[arr[i]]) {
bucket[arr[i]] = 0;
}
bucket[arr[i]]++;
}
for (var j = 0; j < bucketLen; j++) {
while(bucket[j] > 0) {
arr[sortedIndex++] = j;
bucket[j]--;
}
}
return arr;
}
8.4 Análisis de algoritmos
La clasificación por conteo es un algoritmo de clasificación estable. Cuando los elementos de entrada son n enteros entre 0 y k, la complejidad temporal es O (n+k) y la complejidad espacial también es O (n+k). Su velocidad de clasificación es más rápida que cualquier algoritmo de clasificación por comparación. La clasificación por conteo es un algoritmo de clasificación muy eficaz cuando k no es muy grande y las secuencias están relativamente concentradas.
- Clasificación de cubos
La clasificación por cubos es una versión mejorada de la clasificación por conteo. Hace uso de la relación de mapeo de funciones. La clave de la eficiencia reside en la determinación de esta función cartográfica. El principio de funcionamiento de la clasificación de depósitos: suponga que los datos de entrada obedecen a una distribución uniforme, divida los datos en un número limitado de depósitos y luego clasifique cada depósito por separado (es posible utilizar otros algoritmos de clasificación o continuar usando la clasificación de depósitos de forma recursiva).
9.1 Descripción del algoritmo
Establezca una matriz cuantitativa como un cubo vacío;
Recorra los datos de entrada y colóquelos en los depósitos correspondientes uno por uno;
Clasifique cada balde que no esté vacío;
Concatene datos ordenados de depósitos que no estén vacíos.9.2 Demostración de imágenes
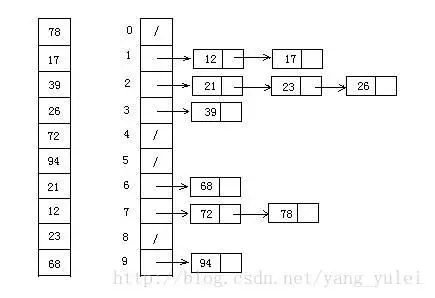
9.3 Implementación del código
function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i < arr.length; i++) {
if (arr[i] < minValue) {
minValue = arr[i]; // 输入数据的最小值
} else if (arr[i] > maxValue) {
maxValue = arr[i]; // 输入数据的最大值
}
}
// 桶的初始化
var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
// 利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++) {
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++) {
insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序
for (var j = 0; j < buckets[i].length; j++) {
arr.push(buckets[i][j]);
}
}
return arr;
}
9.4 Análisis de algoritmos
La clasificación de depósitos utiliza el tiempo lineal O (n) en el mejor de los casos. La complejidad temporal de la clasificación de depósitos depende de la complejidad temporal de la clasificación de datos entre depósitos, porque la complejidad temporal de otras partes es O (n). Obviamente, cuanto más pequeños se dividen los depósitos, menos datos habrá entre cada depósito y menos tiempo llevará ordenarlos. Pero el correspondiente consumo de espacio aumentará.
- Clasificación por base
La clasificación por base consiste en ordenar primero por orden inferior y luego recopilar; luego ordenar por orden superior y luego recopilar; y así sucesivamente, hasta el orden más alto. A veces, algunos atributos tienen un orden de prioridad, ordenados primero por prioridad baja y luego por prioridad alta. El orden final es que aquellos con mayor prioridad van primero, y aquellos con la misma prioridad alta y menor prioridad van primero.
10.1 Descripción del algoritmo
Obtenga el número máximo en la matriz y obtenga el número de dígitos;
arr es la matriz original y cada bit se toma del bit más bajo para formar la matriz de base;
Realice la clasificación por conteo en base (utilizando la función de clasificación por conteo adecuada para números de rango pequeño);
10.2 Demostración GIF

10.3 Implementación del código
// LSD Radix Sort
var counter = [];
function radixSort(arr, maxDigit) {
var mod = 10;
var dev = 1;
for (var i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {
for(var j = 0; j < arr.length; j++) {
var bucket = parseInt((arr[j] % mod) / dev);
if(counter[bucket]==null) {
counter[bucket] = [];
}
counter[bucket].push(arr[j]);
}
var pos = 0;
for(var j = 0; j < counter.length; j++) {
var value = null;
if(counter[j]!=null) {
while ((value = counter[j].shift()) != null) {
arr[pos++] = value;
}
}
}
}
return arr;
}
10.4 Análisis de algoritmos
La clasificación por Radix se basa en la clasificación y recolección por separado, por lo que es estable. Sin embargo, el rendimiento de la clasificación por base es ligeramente peor que el de la clasificación por cubeta. Cada asignación de depósito de palabras clave requiere una complejidad de tiempo O (n), y obtener una nueva secuencia de palabras clave después de la asignación requiere una complejidad de tiempo O (n). Si los datos a ordenar se pueden dividir en d palabras clave, la complejidad temporal de la clasificación por base será O (d * 2n). Por supuesto, d es mucho menor que n, por lo que es básicamente lineal.
La complejidad espacial de la clasificación de bases es O (n+k), donde k es el número de depósitos. Generalmente n >> k, por lo que el espacio adicional necesita aproximadamente n.
What to read next
Want more posts about Translation?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Translation?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home