Os dez principais algoritmos de classificação clássicos
Dez algoritmos de classificação clássicos
#Dez principais algoritmos de classificação clássicos (demonstração de animação) De: blog pessoal de Damonare
Texto original: http://blog.damonare.cn/2016/12/20/十大经典排序算法总结(javascript描述)/
##0. Visão geral do algoritmo
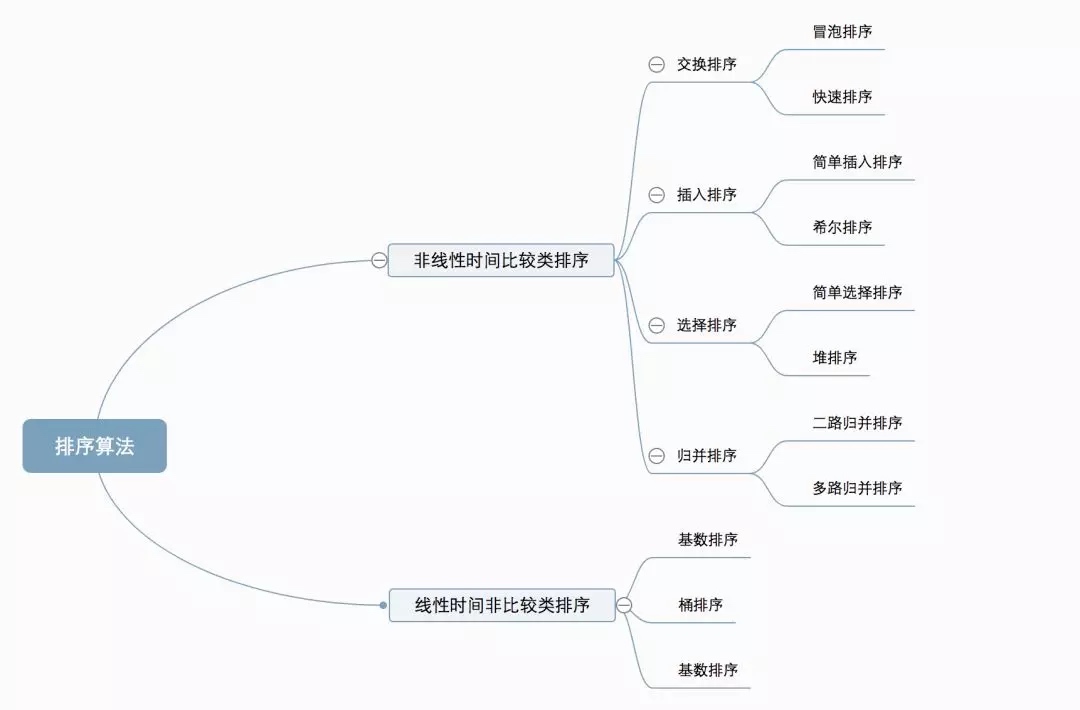
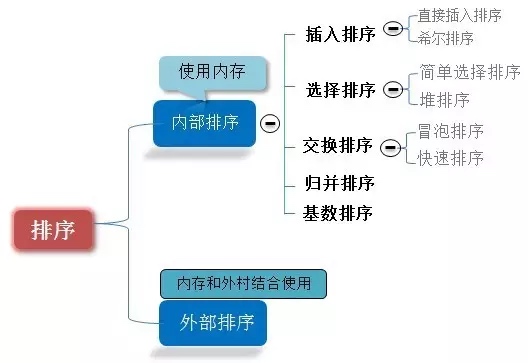
##0.1 Classificação do algoritmo
Dez algoritmos de classificação comuns podem ser divididos em duas grandes categorias:
Classificação não linear de comparação de tempo: Determine a ordem relativa entre os elementos por meio de comparação. Como sua complexidade de tempo não pode exceder O(nlogn), ela é chamada de classificação não linear por comparação de tempo. Classificação sem comparação em tempo linear: não determina a ordem relativa entre os elementos por meio de comparação. Ele pode romper o limite inferior de tempo da classificação baseada em comparação e ser executado em tempo linear, por isso é chamado de classificação sem comparação em tempo linear.
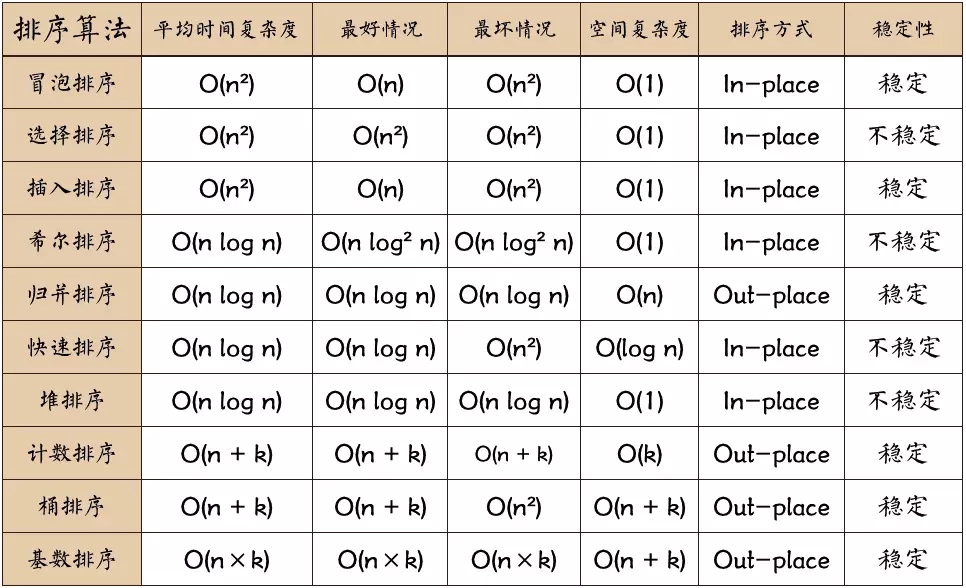
0.2 Complexidade do algoritmo
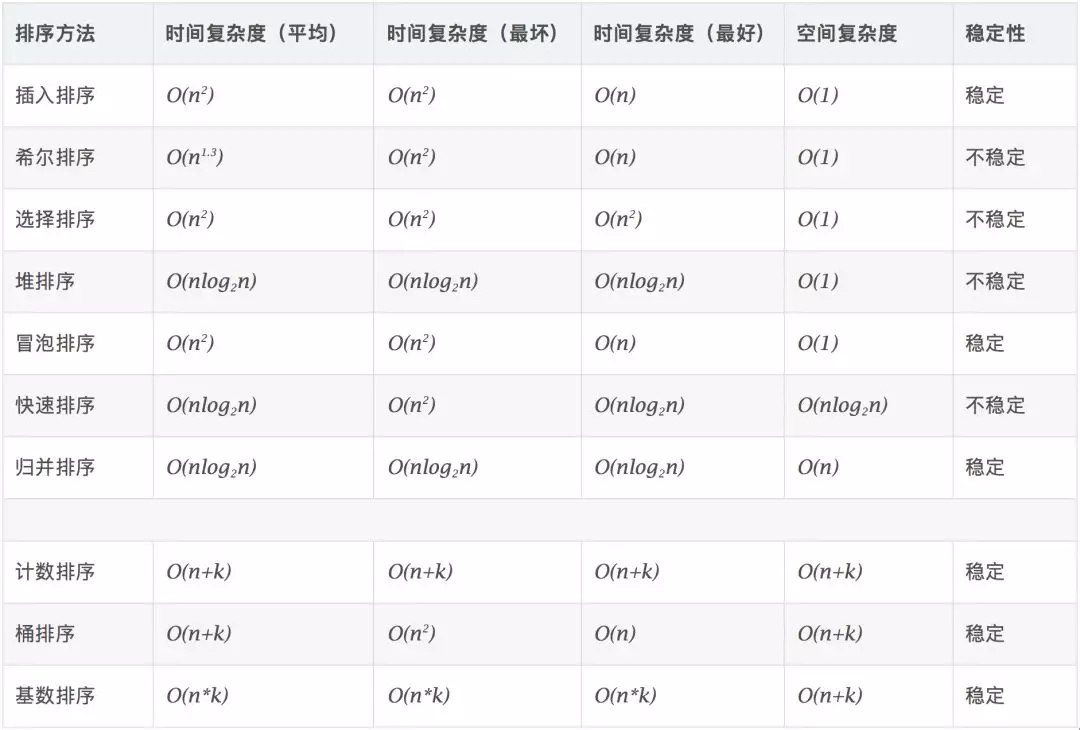
0.3 Conceitos relacionados
Estável: se a estiver originalmente na frente de b e a = b, a ainda estará na frente de b após a classificação. Instável: se a estiver originalmente na frente de b e a = b, a pode aparecer depois de b após a classificação. Complexidade de tempo: o número total de operações em dados classificados. Reflete o padrão do número de operações quando n muda. Complexidade de espaço: refere-se à medição do espaço de armazenamento necessário quando um algoritmo é executado em um computador. Também é uma função do tamanho dos dados n.
1. Classificação por bolha (classificação por bolha)
Bubble sort é um algoritmo de classificação simples. Ele percorre repetidamente a sequência a ser classificada, comparando os elementos dois de cada vez e trocando-os se estiverem na ordem errada. O trabalho de visitar o array é repetido até que não sejam necessárias mais trocas, o que significa que o array foi ordenado. O nome desse algoritmo vem do fato de que elementos menores irão lentamente “flutuar” até o topo do array por meio de troca.
1.1 Descrição do algoritmo
-
Compare os elementos adjacentes. Se o primeiro for maior que o segundo, troque os dois;
-
Faça o mesmo trabalho para cada par de elementos adjacentes, desde o primeiro par no início até o último par no final, de forma que o último elemento seja o maior número;
-
Repita os passos acima para todos os elementos exceto o último;
-
Repita as etapas 1 a 3 até que a classificação seja concluída.
1.2 Demonstração de Animação
1.3 Implementação de código
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i < len - 1; i++) {
for (var j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) { // 相邻元素两两对比
var temp = arr[j+1]; // 元素交换
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
2. Classificação de seleção
A classificação por seleção é um algoritmo de classificação simples e intuitivo. Como funciona: primeiro encontre o menor (grande) elemento na sequência não classificada, armazene-o no início da sequência classificada e, em seguida, continue a encontrar o menor (grande) elemento dos elementos não classificados restantes e, em seguida, coloque-o no final da sequência classificada. E assim por diante até que todos os elementos estejam classificados.
2.1 Descrição do algoritmo
A classificação por seleção direta de n registros pode obter resultados ordenados por meio de n-1 passagens de classificação por seleção direta. O algoritmo específico é descrito a seguir:
- Estado inicial: A área não ordenada é R[1…n] e a área ordenada está vazia;
- Quando a i-ésima classificação (i=1,2,3…n-1) começa, a área ordenada atual e a área não ordenada são R[1…i-1] e R(i…n), respectivamente. Esta operação de classificação seleciona o registro R[k] com a menor palavra-chave da área não ordenada atual e o troca com o primeiro registro R na área não ordenada, de modo que R[1…i] e R[i+1…n) se tornem uma nova área ordenada com o número de registros aumentado em 1 e uma nova área não ordenada com o número de registros reduzido em 1 respectivamente;
- Ao final de n-1 passagens, o array é classificado.
2.2 Demonstração de Animação
2.3 Implementação de código
function selectionSort(arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i < len - 1; i++) {
minIndex = i;
for (var j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) { // 寻找最小的数
minIndex = j; // 将最小数的索引保存
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
2.4 Análise de algoritmo
Um dos algoritmos de classificação mais estáveis, pois não importa quais dados sejam inseridos, a complexidade do tempo é O(n2), portanto, ao usá-lo, quanto menor o tamanho dos dados, melhor. A única vantagem pode ser que não ocupa espaço de memória adicional. Teoricamente falando, a classificação por seleção também pode ser o método de classificação mais comum que a maioria das pessoas pensa ao classificar.
- Classificação de inserção
A descrição do algoritmo de classificação por inserção (Insertion-Sort) é um algoritmo de classificação simples e intuitivo. Funciona construindo uma sequência ordenada. Para dados não classificados, ele verifica de trás para frente na sequência classificada, encontra a posição correspondente e a insere.
3.1 Descrição do algoritmo
De modo geral, a classificação por inserção é implementada em arrays usando in-place. O algoritmo específico é descrito a seguir:
- A partir do primeiro elemento, o elemento pode ser considerado classificado;
- Retire o próximo elemento e digitalize de trás para frente na sequência de elementos classificados;
- Se o elemento (ordenado) for maior que o novo elemento, mova o elemento para a próxima posição;
- Repita o passo 3 até encontrar a posição onde o elemento ordenado é menor ou igual ao novo elemento;
- Após inserir o novo elemento nesta posição;
- Repita as etapas 2 a 5.
3.2 Demonstração de GIFs
3.3 Implementação do código
function insertionSort(arr) {
var len = arr.length;
var preIndex, current;
for (var i = 1; i < len; i++) {
preIndex = i - 1;
current = arr[i];
while (preIndex >= 0 && arr[preIndex] > current) {
arr[preIndex + 1] = arr[preIndex];
preIndex--;
}
arr[preIndex + 1] = current;
}
return arr;
}
3.4 Análise de algoritmo
Na implementação da classificação por inserção, geralmente é usada a classificação no local (ou seja, classificação que usa apenas espaço extra O(1)). Portanto, durante o processo de digitalização de trás para frente, os elementos classificados precisam ser repetidamente e gradualmente deslocados para trás para fornecer espaço de inserção para os elementos mais recentes.
- Classificação de casca
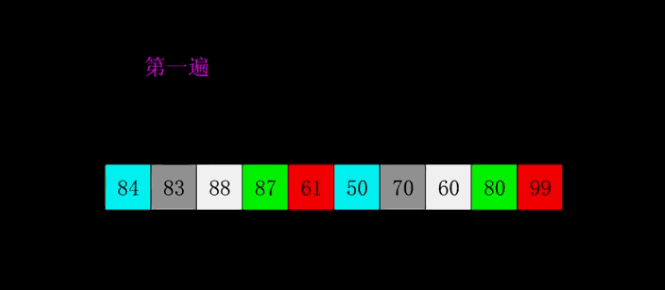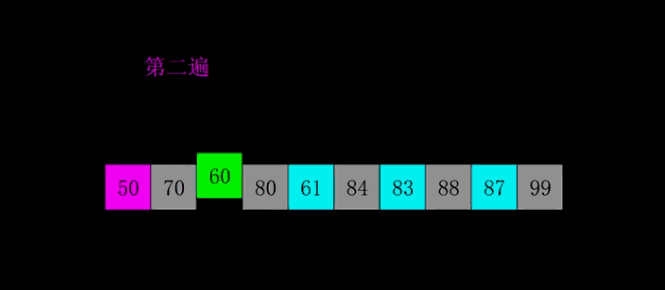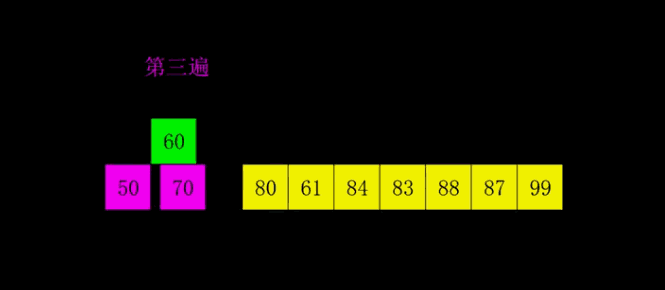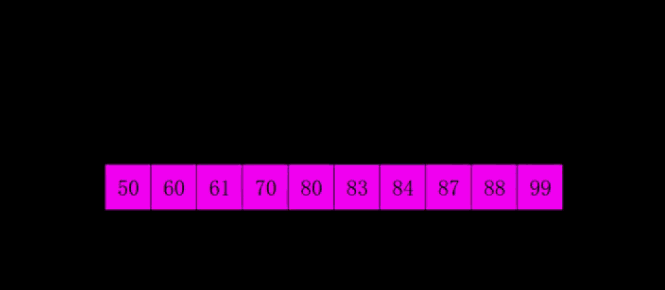
Inventado pela Shell em 1959, foi o primeiro algoritmo de ordenação a romper O(n2) e foi uma versão melhorada da ordenação por inserção simples. Ela difere da classificação por inserção porque compara primeiro os elementos que estão mais distantes. A classificação Hill também é chamada de classificação por incremento redutor.
4.1 Descrição do algoritmo
Primeiro, toda a sequência de registros a ser classificada é dividida em várias subsequências para classificação por inserção direta. O algoritmo específico é descrito:
Selecione uma sequência incremental t1, t2,…,tk, onde ti>tj, tk=1;
Classifique a sequência k vezes de acordo com o número de sequências incrementais k;
Em cada passagem de classificação, a coluna a ser classificada é dividida em várias subsequências de comprimento m de acordo com o incremento ti correspondente, e a classificação por inserção direta é realizada em cada subtabela. Somente quando o fator de incremento é 1, toda a sequência é processada como uma tabela, e o comprimento da tabela é o comprimento de toda a sequência.
4.2 Demonstração de GIFs
4.3 Implementação do código
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while (gap < len / 3) { // 动态定义间隔序列
gap = gap * 3 + 1;
}
for (gap; gap > 0; gap = Math.floor(gap / 3)) {
for (var i = gap; i < len; i++) {
temp = arr[i];
for (var j = i-gap; j > 0 && arr[j]> temp; j-=gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
}
}
return arr;
}
4.4 Análise de algoritmo
O núcleo da classificação de Hill está na configuração da sequência de intervalos. A sequência de intervalo pode ser definida antecipadamente ou definida dinamicamente. O algoritmo para definir dinamicamente sequências de intervalo foi proposto por Robert Sedgewick, co-autor de “Algorithms (4th Edition)”.
- Mesclar classificação
Merge sort é um algoritmo de classificação eficaz baseado em operações de mesclagem. Este algoritmo é uma aplicação muito típica que usa o método dividir e conquistar (Divide and Conquer). Mesclar as subsequências já ordenadas para obter uma sequência completamente ordenada; isto é, primeiro ordene cada subsequência e depois ordene os segmentos da subsequência. Se duas listas ordenadas são mescladas em uma lista ordenada, isso é chamado de mesclagem bidirecional.
5.1 Descrição do algoritmo
Divida a sequência de entrada de comprimento n em duas subsequências de comprimento n/2;
Use a classificação por mesclagem nessas duas subsequências;
Mesclar duas subsequências classificadas em uma sequência ordenada final.
5.2 Demonstração de GIFs
5.3 Implementação do código
function mergeSort(arr) { // 采用自上而下的递归方法
var len = arr.length;
if (len < 2) {
return arr;
}
var middle = Math.floor(len / 2),
left = arr.slice(0, middle),
right = arr.slice(middle);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
var result = [];
while (left.length>0 && right.length>0) {
if (left[0] <= right[0])="" {<="" span="">
result.push(left.shift());
} else {
result.push(right.shift());
}
}
while (left.length)
result.push(left.shift());
while (right.length)
result.push(right.shift());
return result;
}
5.4 Análise de algoritmo
Merge sort é um método de classificação estável. Assim como a classificação por seleção, o desempenho da classificação por mesclagem não é afetado pelos dados de entrada, mas seu desempenho é muito melhor do que a classificação por seleção porque a complexidade do tempo é sempre O (nlogn). O preço é espaço de memória adicional.
- Classificação rápida
A ideia básica da classificação rápida é separar os registros a serem classificados em duas partes independentes por meio de uma classificação. Se as palavras-chave de uma parte do registro forem menores que as palavras-chave da outra parte, as duas partes dos registros poderão ser classificadas separadamente para obter a ordem de toda a sequência.
6.1 Descrição do algoritmo
A classificação rápida usa o método dividir e conquistar para dividir uma lista em duas sublistas. O algoritmo específico é descrito a seguir:
Escolher um elemento da sequência é chamado de “pivô”;
Reordene a matriz para que todos os elementos menores que o valor base sejam colocados na frente da base e todos os elementos maiores que o valor base sejam colocados atrás da base (o mesmo número pode ir para qualquer um dos lados). Após a saída desta partição, a base estará no meio da sequência. Isso é chamado de operação de partição;
Classifique recursivamente a submatriz de elementos menor que o valor base e a submatriz de elementos maior que o valor base.
6.2 Demonstração de GIFs
6.3 Implementação do código
function quickSort(arr, left, right) {
var len = arr.length,
partitionIndex,
left = typeof left != 'number' ? 0 : left,
right = typeof right != 'number' ? len - 1 : right;
if (left < right) {
partitionIndex = partition(arr, left, right);
quickSort(arr, left, partitionIndex-1);
quickSort(arr, partitionIndex+1, right);
}
return arr;
}
function partition(arr, left ,right) { // 分区操作
var pivot = left, // 设定基准值(pivot)
index = pivot + 1;
for (var i = index; i <= right;="" i++)="" {<="" span="">
if (arr[i] < arr[pivot]) {
swap(arr, i, index);
index++;
}
}
swap(arr, pivot, index - 1);
return index-1;
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
- Classificação de pilha
Heapsort refere-se a um algoritmo de classificação projetado usando a estrutura de dados de um heap. O empilhamento é uma estrutura que se aproxima de uma árvore binária completa e satisfaz as propriedades do empilhamento: ou seja, o valor-chave ou índice de um nó filho é sempre menor (ou maior) que seu nó pai.
7.1 Descrição do algoritmo
Construa a sequência inicial de palavras-chave a serem classificadas (R1, R2…Rn) em um grande heap superior, que é a área inicial não ordenada;
Troque o elemento superior R[1] pelo último elemento R[n] e, em seguida, obtenha uma nova área não ordenada (R1, R2,…Rn-1) e uma nova área ordenada (Rn) e satisfaça R[1,2…n-1]<=r[n];< span=“”></=r[n];<>
Como o novo R[1] superior do heap após a troca pode violar as propriedades do heap, é necessário ajustar a área desordenada atual (R1, R2,…Rn-1) em um novo heap e, em seguida, trocar R[1] pelo último elemento da área desordenada novamente para obter uma nova área desordenada (R1, R2…Rn-2) e uma nova área ordenada (Rn-1, Rn). Este processo é repetido até que o número de elementos na área ordenada seja n-1, então todo o processo de classificação é concluído.
7.2 Demonstração de GIFs

7.3 Implementação do código
var len; // 因为声明的多个函数都需要数据长度,所以把len设置成为全局变量
function buildMaxHeap(arr) { // 建立大顶堆
len = arr.length;
for (var i = Math.floor(len/2); i >= 0; i--) {
heapify(arr, i);
}
}
function heapify(arr, i) { // 堆调整
var left = 2 * i + 1,
right = 2 * i + 2,
largest = i;
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest);
}
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function heapSort(arr) {
buildMaxHeap(arr);
for (var i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0);
}
return arr;
}
- Classificação por contagem
A classificação por contagem não é um algoritmo de classificação baseado em comparação. Seu núcleo está na conversão de valores de dados de entrada em chaves e no armazenamento deles em um espaço de array aberto adicionalmente. Como uma classificação linear por complexidade de tempo, a classificação por contagem exige que os dados de entrada sejam inteiros dentro de um determinado intervalo.
8.1 Descrição do algoritmo
Encontre os maiores e menores elementos da matriz a ser classificada;
Contar o número de ocorrências de cada elemento com valor i no array e armazená-lo no i-ésimo item do array C;
Acumule todas as contagens (a partir do primeiro elemento em C, cada item é adicionado ao item anterior);
Preencha a matriz de destino ao contrário: coloque cada elemento i no C(i)-ésimo item da nova matriz e subtraia 1 de C(i) para cada elemento colocado.
8.2 Demonstração de GIFs
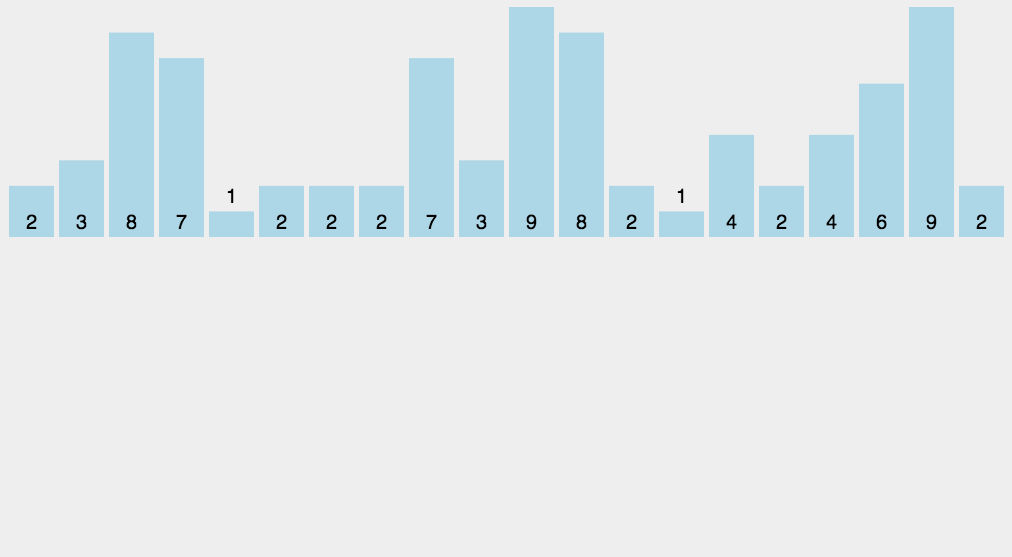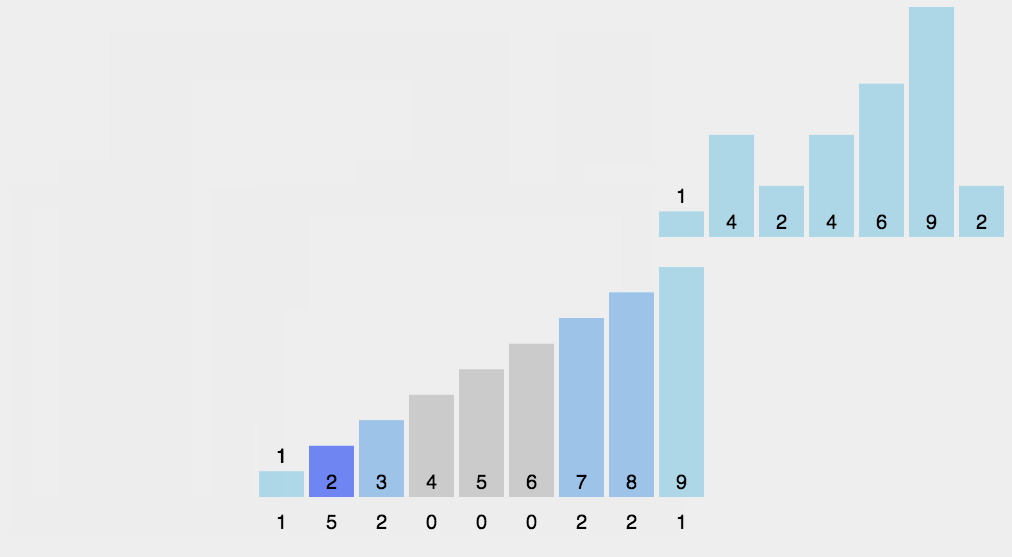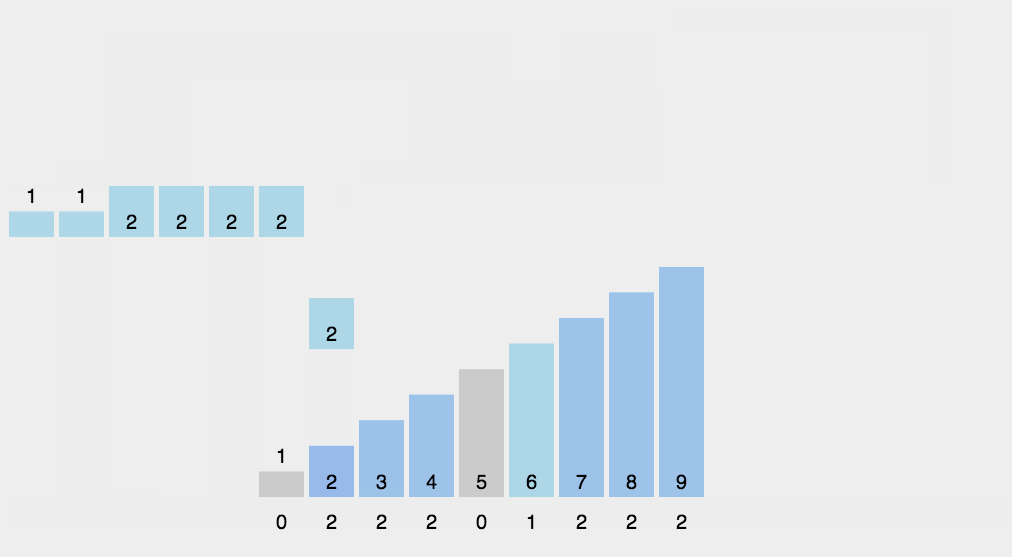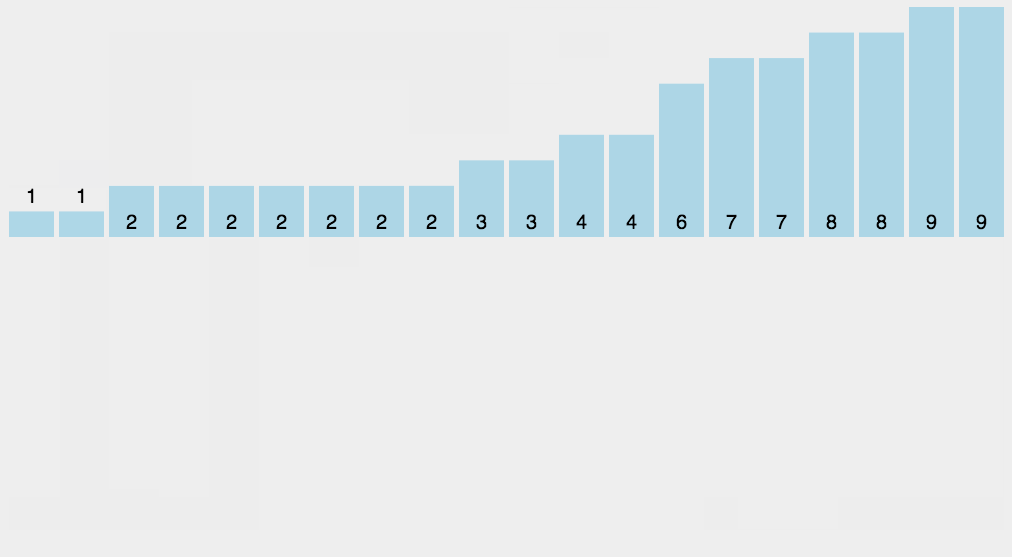
8.3 Implementação do código
function countingSort(arr, maxValue) {
var bucket = new Array(maxValue + 1),
sortedIndex = 0;
arrLen = arr.length,
bucketLen = maxValue + 1;
for (var i = 0; i < arrLen; i++) {
if (!bucket[arr[i]]) {
bucket[arr[i]] = 0;
}
bucket[arr[i]]++;
}
for (var j = 0; j < bucketLen; j++) {
while(bucket[j] > 0) {
arr[sortedIndex++] = j;
bucket[j]--;
}
}
return arr;
}
8.4 Análise de Algoritmo
A classificação por contagem é um algoritmo de classificação estável. Quando os elementos de entrada são n inteiros entre 0 e k, a complexidade do tempo é O(n+k) e a complexidade do espaço também é O(n+k). Sua velocidade de classificação é mais rápida do que qualquer algoritmo de classificação por comparação. A classificação por contagem é um algoritmo de classificação muito eficaz quando k não é muito grande e as sequências são relativamente concentradas.
- Classificação de balde
A classificação por balde é uma versão atualizada da classificação por contagem. Faz uso do relacionamento de mapeamento de funções. A chave para a eficiência reside na determinação desta função de mapeamento. O princípio de funcionamento da classificação por bucket: suponha que os dados de entrada obedeçam a uma distribuição uniforme, divida os dados em um número limitado de buckets e, em seguida, classifique cada bucket separadamente (é possível usar outros algoritmos de classificação ou continuar a usar a classificação por bucket de maneira recursiva).
9.1 Descrição do algoritmo
Defina uma matriz quantitativa como um balde vazio;
Percorra os dados de entrada e coloque-os nos intervalos correspondentes, um por um;
Classifique cada balde que não está vazio;
Concatene dados classificados de buckets que não estão vazios.9.2 Demonstração de imagem
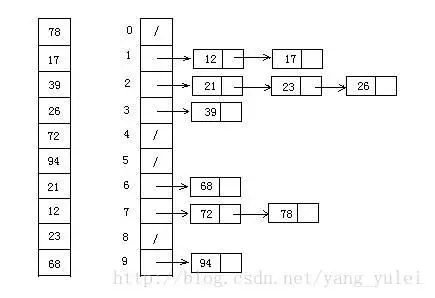
9.3 Implementação do código
function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i < arr.length; i++) {
if (arr[i] < minValue) {
minValue = arr[i]; // 输入数据的最小值
} else if (arr[i] > maxValue) {
maxValue = arr[i]; // 输入数据的最大值
}
}
// 桶的初始化
var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
// 利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++) {
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++) {
insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序
for (var j = 0; j < buckets[i].length; j++) {
arr.push(buckets[i][j]);
}
}
return arr;
}
9.4 Análise de algoritmo
A classificação de bucket usa tempo linear O(n) no melhor caso. A complexidade de tempo da classificação de intervalos depende da complexidade de tempo de classificação de dados entre intervalos, porque a complexidade de tempo de outras partes é O(n). Obviamente, quanto menores os intervalos forem divididos, menos dados haverá entre cada intervalo e menos tempo será necessário para classificar. Mas o consumo de espaço correspondente aumentará.
- Classificação Radix
A classificação Radix consiste em classificar primeiro por ordem inferior e depois coletar; em seguida, classifique por ordem superior e, em seguida, colete; e assim por diante, até a ordem mais alta. Às vezes, alguns atributos têm uma ordem de prioridade, classificados primeiro por baixa prioridade e depois por alta prioridade. A ordem final é que aqueles com maior prioridade venham primeiro, e aqueles com a mesma prioridade alta e menor prioridade venham primeiro.
10.1 Descrição do algoritmo
Obtenha o número máximo na matriz e obtenha o número de dígitos;
arr é a matriz original e cada bit é retirado do bit mais baixo para formar a matriz base;
Execute a classificação de contagem na base (usando o recurso de classificação de contagem adequado para números de intervalo pequeno);
10.2 Demonstração de GIFs

10.3 Implementação do código
// LSD Radix Sort
var counter = [];
function radixSort(arr, maxDigit) {
var mod = 10;
var dev = 1;
for (var i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {
for(var j = 0; j < arr.length; j++) {
var bucket = parseInt((arr[j] % mod) / dev);
if(counter[bucket]==null) {
counter[bucket] = [];
}
counter[bucket].push(arr[j]);
}
var pos = 0;
for(var j = 0; j < counter.length; j++) {
var value = null;
if(counter[j]!=null) {
while ((value = counter[j].shift()) != null) {
arr[pos++] = value;
}
}
}
}
return arr;
}
10.4 Análise de Algoritmo
A classificação Radix é baseada na classificação separada e na coleta separada, portanto é estável. No entanto, o desempenho da classificação radix é um pouco pior do que a classificação por balde. Cada alocação de palavras-chave requer O(n) complexidade de tempo, e a obtenção de uma nova sequência de palavras-chave após a alocação requer O(n) complexidade de tempo. Se os dados a serem classificados puderem ser divididos em d palavras-chave, a complexidade de tempo da classificação radix será O(d*2n). Claro, d é muito menor que n, então é basicamente linear.
A complexidade espacial da classificação radix é O(n+k), onde k é o número de buckets. Geralmente n >> k, então o espaço extra precisa de cerca de n.
What to read next
Want more posts about Translation?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Translation?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home