Structures de données 1 – Exploration des structures de données
Structures de données — Plongée dans les structures de données (Partie 1)
Structures de données - Plonger dans les structures de données (Partie 1) Structures de données - Plonger dans les structures de données (Partie 1)
Source de l’article : https://medium.com/omarelgabrys-blog/diving-into-data-structures-6bc71b2e8f92
[TOC]
Lorsque nous rencontrons un problème de programmation, nous plongeons dans l’algorithme, tout en ignorant la structure des données sous-jacente. Et pire encore, nous pensons que l’utilisation d’une autre structure de données ne fera pas beaucoup de différence, même si nous pourrions considérablement améliorer les performances de notre code en choisissant une autre structure de données. Lorsque nous rencontrons un problème de programmation, nous nous plongeons dans les algorithmes tout en ignorant les structures de données sous-jacentes. Pour aggraver les choses, nous ne pensons pas que l’utilisation d’une autre structure de données fera une grande différence, même si nous pourrions grandement améliorer les performances de notre code en choisissant une autre structure de données.
Qu’est-ce qu’une structure de données Qu’est-ce qu’une structure de données
Cela ne commence pas sans se demander : quelle est cette foutue structure de données ? Cela ne commence pas par demander : qu’est-ce que c’est que la structure des données ?
Il s’agit d’un agencement intentionnel d’une collection de données que nous avons construite. est un arrangement intentionnel de la collecte de données que nous construisons.
Arrangement intentionnel Arrangement délibéré
L’arrangement intentionnel signifie l’arrangement fait exprès pour imposer, faire respecter, une sorte d’organisation systématique des données. L’arrangement intentionnel fait référence à un arrangement intentionnel visant à une organisation systématique des données. L’arrangement délibéré fait référence à l’arrangement délibéré des données dans une organisation systématique. L’arrangement intentionnel fait référence à un arrangement intentionnel qui impose une certaine organisation systématique des données.
Parce que c’est utile, cela nous facilite la vie et c’est facile à gérer lorsque vous conservez les informations associées ensemble. Parce que c’est utile, cela nous facilite la vie et c’est facile à gérer lorsque vous rassemblez des informations pertinentes.
Structures de données dans notre vie Structures de données dans notre vie
Nous avons besoin de structures de données dans nos programmes parce que nous pensons ainsi en tant qu’êtres humains. Dans nos programmes, nous avons besoin de structures de données parce que c’est ainsi que nous, les humains, pensons.
Une recette est une véritable structure de données, tout comme une liste de courses, un annuaire téléphonique, un dictionnaire, etc. Ils ont tous une structure, ils ont un format. Une recette est une véritable structure de données, au même titre qu’une liste de courses, un annuaire téléphonique, un dictionnaire, etc. Elles ont toutes une structure, elles ont toutes un format.
Structure de données et programmation orientée objet Structure de données et programmation orientée objet
Maintenant, si vous êtes un programmeur orienté objet, vous pensez peut-être : n’est-ce pas ce que nous faisons avec les classes et les objets ? Si vous êtes un programmeur orienté objet, vous vous demandez peut-être : n’est-ce pas ce que nous faisons avec les classes et les objets ?
Je veux dire, nous définissons ces objets du monde réel dans un programme parce que nous pensons de cette façon en tant qu’êtres humains, ou du moins nous sommes censés le faire. Je veux dire, nous définissons ces objets du monde réel dans un programme parce que nous pensons comme des humains, ou du moins nous sommes censés penser de cette façon.
Et oui, absolument. Les objets sont un type de structure de données, et pas le seul. Oui bien sûr. Un objet est une structure de données, pas la seule.
Cinq comportements fondamentaux Cinq comportements fondamentaux
Comment accéder, insérer, supprimer, rechercher et trier. Ce sont les opérations que vous effectuerez le plus probablement. Comment accéder, insérer, supprimer, rechercher et trier. Ce sont les actions que vous êtes le plus susceptible d’effectuer.
Toutes les structures de données n’ont pas les cinq comportements fondamentaux. Toutes les structures de données n’ont pas ces cinq comportements de base.
Par exemple, de nombreuses structures de données ne prennent en charge aucun type de comportement de recherche. Il s’agit simplement d’une grande collection, d’un gros conteneur de données, et si vous avez besoin de trouver quelque chose, vous parcourez tout vous-même. Et beaucoup ne proposent aucun type de comportement de tri. D’autres sont naturellement triés. Par exemple, de nombreuses structures de données ne prennent en charge aucun type de comportement de recherche, il s’agit simplement d’une grande collection, d’un gros conteneur de quelque chose, et si vous avez besoin de trouver quelque chose, il vous suffit de le parcourir vous-même. Et beaucoup n’offrent aucun comportement de tri. Autre ordre naturel.
Chaque structure de données a sa propre manière ou son algorithme différent pour trier, insérer, rechercher,… etc. Pourquoi ? Parce que, en raison de la nature de la structure des données, certains algorithmes sont utilisés avec une structure de données spécifique, alors que d’autres ne peuvent pas être utilisés. Chaque structure de données a sa propre manière ou différents algorithmes pour trier, insérer, rechercher, etc. Pourquoi ? Parce que, en raison de la nature des structures de données, certains algorithmes fonctionnent avec une structure de données spécifique et certains autres algorithmes ne peuvent pas être utilisés.
Plus l’algorithme est efficace & adapté, plus vous aurez une structure de données optimisée. Ces algorithmes peuvent être intégrés ou implémentés par le développeur pour gérer et exécuter ces structures de données. Plus l’algorithme est efficace et applicable, plus les structures de données peuvent être optimisées. Ces algorithmes peuvent être intégrés ou implémentés par les développeurs pour gérer et exécuter ces structures de données.
Lisez toujours la documentation du langage et vérifiez les performances des algorithmes utilisés avec la structure de données sous-jacente. Différents algorithmes peuvent être utilisés en fonction des données (taille, type, …) dont vous disposez. Lisez toujours la documentation du langage et vérifiez les performances des algorithmes utilisés avec les structures de données sous-jacentes. Différents algorithmes peuvent être utilisés en fonction des données (taille des données, type,…).
Tableaux unidimensionnels Tableau unidimensionnel
Le tableau est la structure de données la plus fondamentale et la plus couramment utilisée dans tous les langages de programmation. La prise en charge des tableaux unidimensionnels est généralement intégrée directement dans le langage principal lui-même. Les tableaux constituent la structure de données la plus basique et la plus couramment utilisée dans tous les langages de programmation. La prise en charge des tableaux unidimensionnels est généralement intégrée directement dans le langage principal lui-même.
Un tableau est une collection ordonnée d’éléments, où chaque élément à l’intérieur du tableau a un index. Un tableau est une collection ordonnée d’éléments et chaque élément du tableau possède un index.
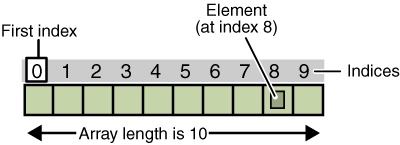
Index Index
Les index sont en ordre, ils sont des index de base zéro dans la plupart des langues, mais ce n’est pas le cas dans quelques autres langues. Les index sont séquentiels, dans la plupart des langues ce sont des index de base zéro, mais dans quelques autres langues ce n’est pas le cas.
Taille tailleLes tableaux les plus simples sont de taille fixe, également appelés immuables, c’est-à-dire des tableaux immuables. Ils peuvent être créés initialement à n’importe quelle taille. Mais une fois le tableau créé, vous ne pouvez plus y ajouter ou supprimer des éléments.
Le tableau le plus simple est de taille fixe, également appelé tableau immuable, c’est-à-dire un tableau qui ne peut pas être modifié. Ils peuvent être initialement créés dans n’importe quelle taille. Mais une fois le tableau créé, aucun élément ne peut y être ajouté ou supprimé.
Parfois, la possibilité d’ajouter ou de supprimer dynamiquement des éléments pendant l’exécution du programme est disponible dans le tableau standard d’un langage, et parfois vous disposez de plusieurs types de tableaux différents, selon que vous avez besoin d’un tableau fixe ou redimensionnable. Parfois, la possibilité d’ajouter ou de supprimer dynamiquement des éléments pendant l’exécution de votre programme est disponible dans les tableaux standard du langage, et parfois vous pouvez utiliser plusieurs types de tableaux différents, selon que vous avez besoin d’un tableau fixe ou d’un tableau redimensionnable.
Type de données Type de données
Les tableaux simples sont généralement limités à un type spécifique de données. C’est un tableau d’entiers ou un tableau de booléens. Mais certains langages vous permettent de créer des tableaux d’objets uniquement génériques, ce qui signifie que vous pouvez placer différents types de données. Les tableaux simples sont généralement limités à des types spécifiques de données. Il s’agit d’un tableau d’entiers ou d’un tableau de booléens. Mais certains langages permettent de créer des tableaux d’objets génériques, ce qui signifie que différents types de données peuvent être placés.
array = [123, true, "string", [1,2,3], object]
Tableaux multidimensionnels Tableau multidimensionnel
En poussant le tableau unidimensionnel un peu plus loin, nous pouvons avoir des tableaux à deux dimensions. En poussant plus loin le tableau unidimensionnel, nous pouvons obtenir un tableau bidimensionnel.
Il s’agit essentiellement d’un tableau de tableaux, où chaque élément de ce tableau contient lui-même un autre tableau. Il s’agit essentiellement d’un tableau de tableaux, chaque élément du tableau contenant lui-même un autre tableau.
Par conséquent, aucun élément du tableau n’est accessible avec un seul index, mais nous avons besoin de deux nombres pour y accéder. Parfois appelé matrice ou tableau car il s’agit en fait de lignes et de colonnes d’informations. Par conséquent, aucun élément du tableau n’est accessible avec un seul index, mais deux nombres sont nécessaires pour y accéder. Parfois appelé matrice ou tableau car il s’agit en fait de lignes et de colonnes d’informations.
Nous pouvons amener le tableau bidimensionnel vers des tableaux tridimensionnels et même plus. Nous pouvons développer davantage des tableaux bidimensionnels en tableaux tridimensionnels, et même plus.
Tableaux irréguliers Tableau irrégulier
Lorsque nous avons un tableau multidimensionnel, où chaque ligne, chaque élément doit avoir un nombre différent d’éléments. C’est là que les tableaux Jagged entrent en jeu. Lorsque nous avons un tableau multidimensionnel, chaque ligne et chaque élément doivent avoir un nombre différent d’éléments. C’est là que les tableaux irréguliers entrent en jeu.
C’est un tableau multidimensionnel où chaque élément peut avoir des tailles différentes. est un tableau multidimensionnel, chaque entrée peut être de tailles différentes.
 Les rangées ont un nombre différent de pierres
rangées avec différents nombres de pierres
Les rangées ont un nombre différent de pierres
rangées avec différents nombres de pierres
Quand utiliser des tableaux irréguliers Quand utiliser des tableaux irréguliers
Si vous disposez d’un tableau multidimensionnel qui enregistre le nombre de ventes chaque jour. Le premier indice correspond au mois, tandis que le second correspond au jour. Si vous disposez d’un tableau multidimensionnel enregistrant les ventes quotidiennes. Le premier index concerne le mois en cours et le deuxième index, le jour en cours.
sales = [[124,153,135, …], [135,545,342,678,], …]
Vous pouvez remarquer que janvier a 31 jours, tandis que le 29 février, et ainsi de suite. Ainsi, soit laisser les éléments non pertinents vides, soit les définir sur 0 ou -99 ou une autre valeur n’est pas toujours souhaitable. Mais vous ne devriez pas avoir d’éléments qui représentent des impossibilités. Comme en février, où les jours 30 et 31 n’existent pas. Vous pouvez remarquer que janvier compte 31 jours, tandis que février en a 29, et ainsi de suite. Par conséquent, il n’est pas toujours conseillé de laisser les éléments non pertinents vides, ou de les définir sur 0 ou -99 ou sur d’autres valeurs. Cependant, vous ne devez pas avoir d’éléments qui représentent l’impossible. Par exemple, en février, 30 et 31 jours n’existent pas.
Ainsi, en utilisant des tableaux Jagged, nous pouvons obtenir la moyenne des ventes d’un mois en récupérant toutes les ventes de ce mois, en les additionnant toutes et en les divisant par le nombre de jours de ce mois, sans avoir à ajouter de logique pour déterminer les jours que nous devrions ignorer. Ainsi, en utilisant un tableau irrégulier, nous pouvons obtenir les ventes moyennes d’un mois en récupérant toutes les ventes du mois, en les additionnant, puis en les divisant par le nombre de jours du mois, sans ajouter de logique pour calculer le nombre de jours qui doivent être ignorés.
Tableaux redimensionnables Tableaux redimensionnables
La plupart des langages fournissent une sorte de tableau redimensionnable, de tableau dynamique ou mutable. En Java, le tableau standard est de taille fixe et de type de données fixe, mais vous pouvez également créer un tableau redimensionnable à l’aide de ArrayList. La plupart des langages fournissent une sorte de tableau ajustable, dynamique ou mutable. En Java, les tableaux standard sont de taille et de type de données fixes. Cependant, vous pouvez également créer des tableaux redimensionnables à l’aide de ArrayList.
Ajout et suppression Ajout et suppression
L’emplacement où nous ajoutons un nouvel élément ou supprimons un élément existant est important, car l’ajout ou la suppression d’un élément à la fin est plus rapide qu’à un autre endroit. La position où vous ajoutez un nouvel élément ou supprimez un élément existant est importante, car l’ajout ou la suppression d’éléments à la fin est plus rapide qu’ailleurs.
Ainsi, les éléments devront être décalés vers la gauche ou vers la droite, et réindexés ; récommandé. Cela a donc un impact sur les performances. Par conséquent, l’élément doit être déplacé vers la gauche ou la droite et réindexé ; l’article doit être commandé à nouveau. Cela a donc un impact sur les performances.
La manière de déplacer diffère d’une langue à l’autre, certains déplaceront les éléments en place, mais d’autres copieront simplement tout le contenu de l’ancien tableau dans un nouveau, l’élément étant ajouté ou supprimé. Selon la façon dont fonctionne la conversion, selon la langue, certains déplaceront les éléments en place, tandis que d’autres copieront simplement l’intégralité du contenu de l’ancien tableau dans un nouveau tableau, ajoutant ou supprimant des éléments en même temps.
Tri des tableaux Tableau de triLe tri est toujours gourmand en calcul, vous devrez peut-être le faire mais nous voulons le minimiser. Ainsi, rester conscient de la quantité de données dont nous disposons et de la fréquence à laquelle nous demandons de les trier peut nous amener à choisir différentes structures de données.
Le tri nécessite toujours beaucoup de calculs, vous devrez peut-être le faire, mais nous souhaitons le minimiser. Par conséquent, comprendre la quantité de données dont nous disposons et la fréquence à laquelle nous avons besoin de trier peut nous conduire à choisir une structure de données différente.
 Trier les personnes par taille —pleacher.com
Trier par hauteur
Trier les personnes par taille —pleacher.com
Trier par hauteur
La fonctionnalité de tri intégrée La fonction de tri intégrée
Lorsque nous trions des tableaux, vous devez comprendre certaines choses pour comprendre la fonctionnalité de tri intégrée. Lorsque nous trions un tableau, vous devez connaître la fonctionnalité de tri intégrée.
Deuxièmement, la fonctionnalité de tri intégrée tentera-t-elle de trier un tableau existant en place ou créera-t-elle une autre copie ?. La plupart des langages tenteront de trier un tableau existant sur place, tandis que quelques-uns créeront une nouvelle copie du tableau d’origine pour contenir le tableau trié. Deuxièmement, la fonction de tri intégrée tente-t-elle de trier le tableau existant ou de créer une autre copie ? La plupart des langages tenteront de trier le tableau existant, tandis que quelques-uns créeront une nouvelle copie du tableau d’origine pour contenir le tableau trié.
Tri des objets personnalisés Tri des objets personnalisés
Dans les langages orientés objet, vous disposez souvent de tableaux de vos propres objets personnalisés, et pas seulement de tableaux de simples valeurs numériques ou même de chaînes. Dans les langages orientés objet, vous disposez généralement de votre propre tableau d’objets personnalisés, et pas seulement d’un simple tableau de nombres ou même d’un tableau de chaînes.
Lorsque vous demandez ensuite à ce tableau de trier ces objets à l’aide de la fonctionnalité de tri intégrée au langage. Il ne saura tout simplement pas comment le faire. Parce que vous devez fournir un peu plus d’informations sur les biens à trier en conséquence. Le tableau est ensuite invité à trier ces objets à l’aide de la fonctionnalité de tri intégrée au langage. Il ne sait tout simplement pas comment s’y prendre. Parce que vous devez fournir plus d’informations sur les propriétés de tri correspondantes.
Ainsi, par exemple, triez les utilisateurs par leur identifiant, leur nom ou leur date de naissance. Ceci définit la propriété de l’objet à trier en conséquence. Par exemple, triez les utilisateurs par identifiant, nom ou date de naissance. Ceci définit les propriétés de l’objet à trier en conséquence.
Il ne nécessite généralement que quelques lignes et est généralement appelé comparateur, fonction de comparaison ou méthode de comparaison. Généralement, seules quelques lignes de code sont requises et sont souvent appelées comparateurs, fonctions de comparaison ou méthodes de comparaison.
##Recherche de tableaux Rechercher un tableau
Si nous voulions savoir si une valeur spécifique existe ou non quelque part dans un tableau, nous pourrions parcourir les éléments du tableau, vérifier la valeur à cette position actuelle et voir si elle est égale à l’objectif ou non. Si nous voulons savoir si une valeur spécifique existe dans le tableau, nous pouvons parcourir les éléments du tableau et vérifier la valeur à la position actuelle pour voir si elle est égale à l’objectif.
 Continuez à chercher même sous le lit
Continue à chercher même sous le lit
Continuez à chercher même sous le lit
Continue à chercher même sous le lit
Dans le meilleur des cas, le premier élément est la valeur que nous recherchons. Dans le pire des cas, la valeur se trouve à la fin ou n’apparaît nulle part dans le tableau. Cette méthode est appelée recherche linéaire ou recherche séquentielle. Il s’agit d’une méthode de force brute peu élégante. Dans le meilleur des cas, le premier élément est la valeur que nous recherchons. Le pire des cas est que la valeur apparaisse à la fin du tableau ou nulle part dans le tableau. Cette méthode est appelée recherche linéaire ou recherche séquentielle. Il s’agit d’une méthode de force brute peu élégante.
Bien que les recherches linéaires soient simples à comprendre et faciles à écrire, elles fonctionneront, mais elles sont lentes. Et plus vous avez d’éléments, plus ils ralentissent. Bien que les recherches linéaires soient faciles à comprendre, faciles à écrire et fonctionnent, elles sont cependant lentes. Plus il y a d’éléments, plus c’est lent.
Les données doivent être commandées. Il faut trier les données.
S’il n’y a pas d’ordre, pas de séquence prévisible pour les valeurs du tableau, alors il se peut qu’il n’y ait pas d’autre option que de vérifier tous les éléments du tableau. Si les valeurs du tableau n’ont pas d’ordre, ni de séquence prévisible, alors il ne peut y avoir d’autre option que de vérifier tous les éléments du tableau.
Les données doivent donc être ordonnées de manière à ce que nous puissions utiliser un algorithme autre que la recherche linéaire. Par conséquent, il est de plus en plus important d’avoir une sorte d’ordre entre ces éléments. Par conséquent, les données doivent être triées d’une manière ou d’une autre afin que nous puissions utiliser des algorithmes autres que la recherche linéaire. Il devient donc de plus en plus important de trier ces éléments
Le défi de l’héritage des structures de données Le défi de l’héritage des structures de données
Vous pouvez parfois accepter d’utiliser une capacité de recherche lente, car la seule façon de résoudre ce problème est de trier le tableau, ce qui à son tour ajoutera une baisse de performances qui n’en vaut tout simplement pas la peine. Parfois, vous pouvez accepter d’utiliser une fonction de recherche lente, car la seule façon de résoudre le problème est de trier le tableau, ce qui à son tour ajoute une pénalité en termes de performances qui n’en vaut tout simplement pas la peine.
Donc, si vous souhaitez effectuer une recherche sur un tableau une fois, il est préférable d’avoir une complexité de O(N) pour la recherche linéaire, plutôt que de O(NLogN) pour le tri + O(LogN) pour la recherche. Si, toutefois, vous envisagez de rechercher beaucoup, vous pouvez d’abord trier le tableau une fois au début, et maintenant, vous pouvez effectuer une recherche avec O(LogN) à chaque fois au lieu d’une recherche linéaire O(N). Donc, si vous deviez effectuer une recherche une fois sur un tableau, ce serait O(N) plus compliqué pour une recherche linéaire que le tri O(NLogN) + O(LogN). Cependant, si vous envisagez d’effectuer beaucoup de recherches, vous pouvez d’abord trier le tableau une fois au début, et vous pouvez désormais effectuer une recherche avec O(LogN) à chaque fois au lieu de O(N) avec une recherche linéaire.Vous ne pouvez pas avoir une structure de données aussi bonne dans toutes les situations. Une structure de données naturellement triée nécessite moins de temps pour rechercher un élément et plus de temps pour l’insérer car elle maintient le tableau trié. Alors qu’un tableau de base nécessite plus de temps pour la recherche et moins de temps pour insérer des éléments à la fin du tableau. Vous ne pouvez pas avoir une structure de données aussi bonne dans toutes les situations. Une structure de données naturellement ordonnée nécessite moins de temps pour rechercher des éléments et plus de temps pour les insérer, car elle maintient l’ordre du tableau. Alors que les tableaux de base nécessitent plus de temps de recherche, l’insertion d’éléments à la fin du tableau prend moins de temps.
##Listes liste
Les listes sont des structures de données assez simples. Sa structure assure le suivi de la séquence des éléments. Les listes sont des structures de données très simples. Il est structuré pour garder une trace de l’ordre des éléments.
It’s a collection of items (called nodes) ordered in a linear sequence.
它是按线性顺序排列的项(称为节点)的集合。
Ces nœuds n’ont pas besoin d’être alloués les uns à côté des autres dans la mémoire comme l’est un tableau. Les nœuds n’ont pas besoin d’être alloués de manière adjacente en mémoire comme les tableaux.
Il existe un concept théorique général de programmation d’une liste, et il existe une implémentation spécifique d’une structure de données de liste, qui peut avoir repris cette idée de base de liste et ajouté tout un tas de fonctionnalités. Les listes sont implémentées soit sous forme de listes chaînées (simples, doubles, circulaires, …) ou sous forme de tableau dynamique. Il existe un concept de programmation théorique général des listes, et il existe une implémentation spécifique d’une structure de données de liste qui reprend probablement ce concept de liste de base et ajoute un tas de fonctionnalités. Les listes peuvent être implémentées sous forme de listes chaînées (listes chaînées simples, listes chaînées doubles, listes chaînées circulaires, listes chaînées circulaires) ou sous forme de tableaux dynamiques.
Un tableau contre une liste Tableau contre liste
Une liste est un type de structure de données différent d’un tableau. Les listes sont une structure de données différente de celle des tableaux.
La plus grande différence réside dans l’idée d’accès direct par rapport à l’accès séquentiel. Les tableaux autorisent les deux ; un accès direct et séquentiel, tandis que les listes autorisent uniquement un accès séquentiel. Et cela est dû à la manière dont ces structures de données sont stockées en mémoire. La plus grande différence réside dans le concept d’accès direct et d’accès séquentiel. Les tableaux autorisent les deux ; un accès direct et séquentiel, alors que les listes autorisent uniquement un accès séquentiel. Cela est dû à la manière dont ces structures de données sont stockées en mémoire.
La structure de la liste ne prend pas en charge l’index numérique comme l’est un tableau. La structure d’une liste ne prend pas en charge l’indexation numérique comme un tableau.
##Listes liées Liste liée
It’s a collection of nodes, where each node has a value and a link to the next node in the list.
它是节点的集合,每个节点都有一个值和到列表中下一个节点的链接。
Le pointeur du dernier nœud pointe vers NULL, ou terminateur, ou un nœud factice. Le pointeur du dernier nœud pointe vers NULL, ou terminateur, ou nœud virtuel.
 Liste chaînée — Wikipédia
Liste de liens - Wikipédia
Liste chaînée — Wikipédia
Liste de liens - Wikipédia
En raison de la façon dont il est construit, l’ajout et la suppression d’éléments sont beaucoup plus faciles qu’avec un tableau. En raison de la façon dont il est construit, l’ajout et la suppression d’éléments sont beaucoup plus simples qu’un tableau.
Mais, avec les tableaux, il faut se déplacer vers la gauche ou vers la droite pour conserver sa structure ordonnée significative. Même l’ajout d’éléments à la fin du tableau peut toujours nécessiter une réallocation de l’intégralité du tableau afin de stocker le tableau dans une zone contiguë de mémoire. Cependant, avec les tableaux, il doit être déplacé vers la gauche ou la droite pour conserver une structure ordonnée significative. Même si vous ajoutez un élément à la fin du tableau, vous devez toujours réaffecter l’intégralité du tableau afin que le tableau soit stocké dans une zone mémoire contiguë.
##Liste doublement chaînée Liste doublement chaînée
Ce que nous avons introduit est une liste chaînée, mais pour être encore un peu plus précis, il s’agit d’une « liste chaînée unique ». Nous pouvons également avoir une « liste doublement chaînée ». Nous avons introduit une liste chaînée, mais pour être plus précis, il s’agit de ce que l’on appelle une « liste chaînée unique ». Nous pouvons également avoir une « double liste chaînée ».
Au lieu que chaque nœud ait une référence uniquement au nœud suivant, nous ajoutons une donnée supplémentaire qui a également une référence au nœud précédent. Ainsi, cela nous permet d’avancer et de reculer, de parcourir la liste dans n’importe quelle direction. Au lieu que chaque nœud n’ait qu’une référence au nœud suivant, une autre donnée est ajoutée qui a également une référence au nœud précédent. Ainsi, cela nous permet d’avancer et de reculer, en parcourant la liste dans n’importe quelle direction.
 Liste doublement liée — Wikipédia
Liste doublement chaînée — Wikipédia
Liste doublement liée — Wikipédia
Liste doublement chaînée — Wikipédia
Les listes chaînées dans la plupart des langues sont généralement implémentées sous forme de listes doublement chaînées. Dans la plupart des langues, les listes chaînées sont généralement implémentées sous forme de listes doublement chaînées.
La liste simple ou doublement liée La liste simple ou doublement liée
L’opération Ajout demande clairement moins de travail dans une liste à lien unique, car une liste à double lien nécessite de modifier plus de liens qu’une liste à lien unique. Ajouter une opération ** à une liste à chaînage unique demande évidemment moins de travail puisqu’une liste à double chaînage nécessite plus de changements de lien qu’une liste à chaînage unique.
Pour une liste à chaînage unique, nous supposons que nous insérons en tête ou après un nœud donné. Pour les listes à chaînage unique, nous supposons l’insertion après le nœud principal ou un nœud donné.
En cas d’ajout avant un nœud donné, vous devez connaître le nœud avant ce nœud donné, ce qui vous obligera à accéder séquentiellement à tous les nœuds jusqu’à ce que vous trouviez le nœud que vous recherchez. Si vous souhaitez ajouter un nœud avant un nœud donné, vous devez connaître les nœuds avant ce nœud, ce qui vous obligera à visiter tous les nœuds séquentiellement jusqu’à ce que vous trouviez le nœud que vous recherchez.
La suppression est plus simple et potentiellement plus efficace dans une liste doublement chaînée, car dans une liste chaînée unique, vous devez connaître le nœud avant le nœud à supprimer. Dans une liste doublement chaînée, la suppression est plus simple et probablement plus efficace, car dans une liste simplement chaînée, vous devez connaître le nœud avant celui que vous souhaitez supprimer.
##Liste chaînée circulaire Liste chaînée circulaireDans une liste à chaînage unique, si le pointeur suivant du dernier nœud pointe vers le premier nœud. Ensuite, c’est « Liste chaînée circulaire ». Et si le pointeur précédent du premier nœud pointe également vers le dernier nœud. Maintenant, cela serait considéré comme une « liste circulaire doublement liée ». Dans une liste à chaînage unique, si le pointeur suivant du dernier nœud pointe vers le premier nœud. Ensuite, il y a la « liste chaînée circulaire ». Si le pointeur précédent du premier nœud pointe vers le dernier nœud. Désormais, cela serait considéré comme une « liste circulaire doublement chaînée ».

Liste chaînée circulaire — Wikipédia Liste chaînée circulaire — Wikipédia
Ce n’est pas courant, mais cela peut être utile pour certains problèmes. Donc, si nous arrivons à la fin de la liste et disons suivant, nous recommençons simplement au début. Ce n’est pas courant, mais cela peut être utile pour certains problèmes. Donc, si nous arrivons à la fin de la liste, disons la suivante, nous reprenons là où nous avons commencé.
##Pile de piles
Tout comme les tableaux et les listes, les piles et les files d’attente sont également des collections d’éléments. Ce sont simplement différentes manières de contenir plusieurs objets. Il s’agit d’une structure de données du dernier entré, premier sorti, sans se soucier des index numériques. Tout comme les tableaux et les listes, les piles et les files d’attente sont des collections d’éléments. Ce sont simplement des façons différentes de s’adapter à plusieurs projets. Il s’agit d’une structure de données dernier entré, premier sorti et ne se soucie pas des index numériques.
It’s a collection of items where we add and remove items to and from the top of the stack.
它是一个项集合,我们在堆栈顶部添加和删除项。
 Pile d’assiettes sales
tas de vaisselle sale
Pile d’assiettes sales
tas de vaisselle sale
Implémentation de la pile Implémentation de la pile
Une pile peut être facilement implémentée en utilisant un tableau ou une liste chaînée Les piles peuvent facilement être implémentées avec des tableaux ou des listes chaînées
Utilisation des piles Utilisation de la pile
Stack ne se limite pas à modéliser uniquement les situations du monde réel (idem pour les files d’attente). L’une des meilleures utilisations d’une pile en programmation est lors de l’analyse de code ou d’expressions, où vous devez faire quelque chose comme valider la quantité correcte d’accolades ouvrantes et fermantes, de crochets ou de parenthèses. Stack ne se limite pas à simuler des situations réelles (il en va de même pour les files d’attente). L’une des meilleures utilisations de la pile en programmation est lors de l’analyse du code ou d’une expression et vous devez faire quelque chose comme vérifier le nombre correct d’accolades ouvrantes, de crochets ou de crochets.
Les opérations de base des piles Les opérations de base de la pile
Ce sont : push(), pop() et peek(). push sert à pousser un nouvel élément en haut de la pile, et pop renverra (et supprimera) l’élément en haut, tandis que peek obtiendra l’élément en haut sans le supprimer. Ce sont : push(), pop() et peek(). push est utilisé pour pousser un nouvel élément au-dessus de la pile, pop renverra (et supprimera) l’élément supérieur et peek obtiendra l’élément supérieur sans le supprimer.
Piles contre tableaux contre listes liées Piles contre tableaux contre listes liées
Travailler avec une pile est plus simple que travailler avec des tableaux ou des listes chaînées, car vous pouvez faire moins avec une pile. L’utilisation d’une pile est plus simple que l’utilisation d’un tableau ou d’une liste chaînée, car vous pouvez faire moins de choses avec la pile.
Il s’agit d’une structure de données intentionnellement limitée, intentionnellement restreinte. Tout ce que nous faisons, c’est pousser, ouvrir et peut-être jeter un coup d’œil. Et si vous essayez de faire autre chose avec cette pile, vous utilisez la mauvaise structure de données. Il s’agit d’une structure de données intentionnellement restreinte. Tout ce que nous faisons, c’est pousser, ouvrir ou jeter un coup d’œil. Si vous souhaitez utiliser cette pile pour autre chose, vous utilisez la mauvaise structure de données.
##Files d’attente
La principale différence entre une pile et une file d’attente. Les piles sont du type dernier entré, premier sorti (LIFO), tandis que les files d’attente sont du premier entré, premier sorti (FIFO). Et comme pour les piles, nous ne devrions même pas penser aux index numériques. Différence clé entre la pile et la file d’attente. Les piles sont du type dernier entré, premier sorti (LIFO), tandis que les files d’attente sont du type premier entré, premier sorti (FIFO). Comme pour la pile, nous ne devrions même pas penser à l’indexation numérique.
It’s a collection of items where we add items to the end and remove items from the front of the queue.
它是项的集合,我们在末尾添加项,并从队列前面删除项。
 File d’attente de personnes en ligne
File d’attente de personnes en ligne
Implémentation de la file d’attente Implémentation de la file d’attente
Comme pour les piles, une file d’attente peut être implémentée à l’aide d’un tableau ou d’une liste chaînée. Comme une pile, une file d’attente peut être implémentée à l’aide d’un tableau ou d’une liste chaînée.
Utilisation des files d’attente Utiliser les files d’attente
Les files d’attente sont très couramment utilisées dans les situations de concurrence pour garder une trace des tâches en attente d’être exécutées et s’assurer que nous les effectuons dans cet ordre. Les files d’attente sont très couramment utilisées dans les situations de concurrence pour suivre les tâches en attente d’exécution et garantir qu’elles sont traitées dans l’ordre.
Les opérations de base des files d’attente Les opérations de base de la file d’attente
Tout comme une pile : add(), remove() et peek(). Tout comme une pile : add(), remove() et peek().
Files d’attente prioritaires file d’attente prioritaire
Certaines langues proposent une version de file d’attente, appelée file d’attente prioritaire. Cela vous permet d’organiser les éléments dans la file d’attente en fonction de leur priorité. Certaines langues proposent une version d’une file d’attente appelée file d’attente prioritaire. Cela vous permet d’organiser les éléments dans la file d’attente en fonction de leur priorité.
It’s a queue, where items with higher priority step ahead of items with lower priority in the queue.
它是一个队列,在队列中优先级较高的项先于优先级较低的项。
Fonctionnement des files d’attente prioritaires Comment fonctionnent les files d’attente prioritaires
Lorsque vous ajoutez des éléments ayant la même priorité, ils seront mis en file d’attente normalement dans l’ordre du premier entré, premier sorti. Si quelque chose présente une priorité plus élevée, il passera devant eux dans la file d’attente. Lorsque vous ajoutez des éléments avec la même priorité, ils sont mis en file d’attente dans l’ordre normal. Si quelque chose avec une priorité plus élevée apparaît, il les devancera dans la file d’attente.
Définir la priorité Définir la priorité
Vous pouvez définir en fonction de ce qu’un élément a une priorité supérieure, inférieure ou égale. Cela se fait en implémentant un comparateur ou une fonction de comparaison (comme lors du tri de tableaux), où vous fournissez votre propre logique pour comparer la priorité entre les éléments. Vous pouvez définir en fonction de la priorité élevée, faible ou égale d’un élément. Ceci peut être réalisé en implémentant un comparateur ou une fonction de comparaison (tout comme le tri d’un tableau) où vous pouvez fournir votre propre logique lors de la comparaison des priorités entre les éléments.
##Deque file d’attente à double extrémitéLe deque, prononcé « DEK », est utilisé lorsque nous voulons exploiter la puissance de la file d’attente et de la pile, où vous pouvez ajouter ou supprimer du début ou de la fin. Deque se prononce “DEK” et nous utilisons deque lorsque nous voulons profiter des capacités des files d’attente et des piles, où nous pouvons ajouter ou supprimer depuis le début ou la fin.
It’s a queue and a stack at the same time.
它同时是一个队列和一个堆栈。
##Tableaux associatifs Tableau associatif
Ils donnent la possibilité d’utiliser des clés significatives pour travailler avec des éléments de nos structures de données, plutôt que de travailler avec des index numériques comme clés. Cela donne une relation significative entre la clé et la valeur. Ils permettent de traiter les éléments d’une structure de données en utilisant des clés significatives plutôt que des indices numériques comme clés. Cela fournit des relations significatives entre les clés et les valeurs.
It is a collection of key-value pairs.
它是键-值对的集合。
var user = {
firstName: "Bob",
lastName: "Jones",
age: 26,
email: "bob.jones@example.com"
};
L’implémentation de tableaux associatifs porte des noms différents. En Objective-C et Python, ils sont appelés dictionnaires. Les implémentations de tableaux associatifs portent des noms différents. En Objective-C et Python, ils sont appelés dictionnaires.
L’ordre des éléments L’ordre des éléments
Contrairement à un tableau de base, dans un tableau associatif, les clés n’ont pas besoin d’être dans un ordre spécifique. Parce que l’ordre n’est pas un problème dans les tableaux associatifs. Contrairement aux tableaux de base, les clés d’un tableau associatif n’ont pas besoin d’être dans un ordre spécifique. Parce que l’ordre n’a rien à voir avec les tableaux associatifs.
Bien sûr, vous trouverez peut-être utile de les trier par clé. Vous trouverez peut-être utile de les trier par valeur, ou vous n’aurez peut-être pas besoin de les trier du tout. Bien sûr, le tri par clé pourrait vous être utile. Vous trouverez peut-être utile de les trier par valeur, ou vous n’aurez peut-être pas besoin de les trier du tout.
Doublons de clés Doublons de clés
De la même manière que vous n’obtenez pas le même numéro d’index apparaissant deux fois dans un tableau de base, il ne peut y avoir de clés en double et les clés doivent être uniques dans un tableau associatif. De même, le même numéro d’index ne peut pas apparaître deux fois dans un tableau de base, il ne peut pas y avoir de clés en double et les clés doivent être uniques dans un tableau associatif.
Types de données clés et valeurs Types de données clé et valeur
Vous pouvez généralement utiliser n’importe quel type de données comme clé ou comme valeur. Il est courant d’utiliser une chaîne comme clé. Vous pouvez généralement utiliser n’importe quel type de données comme clé ou valeur. Habituellement, les chaînes sont utilisées comme clés.
La plupart des tableaux associés, qu’ils soient appelés dictionnaires, cartes ou hachages, sont implémentés à l’aide d’une structure de données de table de hachage. Nous allons donc commencer par hacher, puis nous plonger dans les tables de hachage. La plupart des tableaux associatifs sont implémentés à l’aide de structures de données de table de hachage, qu’il s’agisse de dictionnaires, de cartes ou de hachages. Nous allons donc commencer par les hachages, puis nous plonger dans les tables de hachage.
##Hachage de hachage
Le hachage est un concept précieux en programmation. Il est utilisé non seulement dans les structures de données, mais aussi dans la sécurité, la cryptographie, les graphiques et l’audio. Le hachage est un concept précieux en programmation. Il est utilisé non seulement pour les structures de données, mais également pour la sécurité, le cryptage, les graphiques et l’audio.
It’s a way to take our data and run it through a function, which will return a small, simplified reference generated from that original data.
这是一种获取数据并通过函数运行数据的方法,函数将返回从原始数据生成的一个小的、简化的引用。
 Le hachage est couramment utilisé avec les mots de passe Le hachage est couramment utilisé avec les mots de passe
Le hachage est couramment utilisé avec les mots de passe Le hachage est couramment utilisé avec les mots de passe
La référence peut être simplement un nombre entier, ou des lettres et des chiffres,…etc. La référence peut être simplement un nombre entier, ou des lettres et des chiffres, etc.
Pourquoi utiliser le hachage ? Pourquoi utiliser le hachage ?
Parce qu’être capable de prendre un objet complexe et de le hacher en une seule représentation entière. Nous pouvons donc utiliser cette valeur entière pour accéder à un certain emplacement dans la structure de données. Parce que vous pouvez hacher un objet complexe en une représentation entière. Par conséquent, nous pouvons utiliser cette valeur entière pour atteindre un certain emplacement dans la structure des données.
Le hachage n’est pas un cryptage Le hachage n’est pas un cryptage
Les fonctions de hachage ne sont pas réversibles ; Ils sont à sens unique. Ainsi, vous ne pouvez pas reconvertir le résultat d’une valeur de hachage en données d’origine. Par conséquent, vous perdez des informations lors du hachage, ce n’est pas grave, c’est intentionnel. Les fonctions de hachage sont irréversibles ; ils sont à sens unique. Par conséquent, vous ne pouvez pas reconvertir le résultat du hachage en données d’origine. Par conséquent, des informations sont perdues pendant le processus de hachage, et cela est intentionnel.
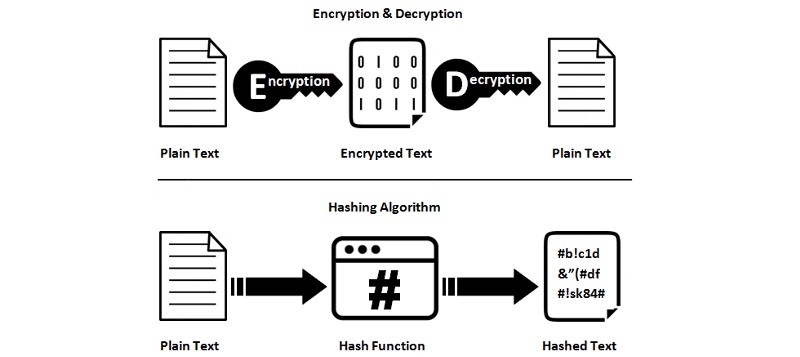 Hachage contre cryptage — ssl2buy.com Hachage contre cryptage — ssl2buy.com
Hachage contre cryptage — ssl2buy.com Hachage contre cryptage — ssl2buy.com
Implémentation de la fonction de hachage Implémentation de la fonction de hachage
Supposons que nous ayons une classe de personne définie et que nous souhaitions qu’une fonction de hachage soit définie sur cette classe. La fonction de hachage doit renvoyer une référence unique spécifique (généralement un entier) pour un objet personne spécifique. Cet entier unique est généré à partir des données d’un objet personne (prénom, nom, date de naissance, …etc). Supposons que nous définissions une classe de personne et que nous souhaitions définir une fonction de hachage sur cette classe. La fonction de hachage doit renvoyer une référence spécifique (généralement un entier) pour un objet personne spécifique. Cet entier est généré à partir des données de l’objet personne (prénom, nom, date de naissance, etc.).
Règles de hachage Règles de hachage
-
Si nous prenons exactement le même objet, avec ces mêmes données, et que nous l’introduisons à nouveau dans la fonction de hachage, je m’attendrais au même résultat de hachage.
-
Si vous avez deux objets différents que vous considérez égaux, ils doivent renvoyer la même valeur de hachage.
-
Alors que deux objets égaux devraient produire la même valeur de hachage, deux valeurs de hachage égales ne garantissent pas qu’elles proviennent d’objets égaux. Pourquoi ? Parce que deux objets différents peuvent, dans certaines circonstances, fournir le même résultat à partir d’une fonction de hachage (voir Hashing Collision). Deux objets égaux devraient produire la même valeur de hachage, mais il n’est pas garanti que deux valeurs de hachage égales proviennent d’objets égaux, pourquoi ? Parce que dans certains cas, deux objets différents peuvent transmettre le même résultat de la fonction de hachage (voir collisions de hachage).
Collision de hachage Collision de hachage
C’est lorsque nous avons différents objets avec des données différentes, mais donnant le même résultat de valeur de hachage. Lorsque nous avons des objets et des données différents, mais que nous obtenons la même valeur de hachage.Cela peut être dû au fait que la fonction de hachage est une simple fonction de hachage, mais cela est également possible même avec des fonctions de hachage plus complexes. Dans la plupart des cas, ce n’est pas grave, nous pouvons gérer la collision de hachage. Cela est probablement dû au fait que la fonction de hachage est une fonction de hachage simple, mais des fonctions de hachage encore plus complexes sont possibles. Dans la plupart des cas, cela est correct et nous pouvons gérer les collisions de hachage.
##Tables de hachage Table de hachage
L’idée du hachage était fondamentale pour comprendre la structure des données des tables de hachage. L’idée du hachage est la base pour comprendre la structure des données de la table de hachage.
It’s a typical data structure to implement an associative arrays; mapping keys to values.
实现关联数组是一种典型的数据结构;将键映射到值。
 Mappage des nombres (clés) aux boîtes Mappage des nombres (clés) aux boîtes
Mappage des nombres (clés) aux boîtes Mappage des nombres (clés) aux boîtes
Tables de hachage contre tableaux contre liste lignée Tables de hachage contre tableaux contre listes
Le grand avantage des tables de hachage par rapport aux tableaux et aux listes chaînées est qu’elles sont très rapides, à la fois pour vérifier si un élément existe ou trouver un élément spécifique dans une table de hachage, et pour insérer et supprimer des éléments. Le plus grand avantage des tables de hachage par rapport aux tableaux et aux listes chaînées est qu’elles sont très rapides, à la fois pour voir si un élément existe, pour trouver un élément spécifique dans la table de hachage et pour insérer et supprimer des éléments.
Comment fonctionnent les tables de hachage ? Comment fonctionnent les tables de hachage ?
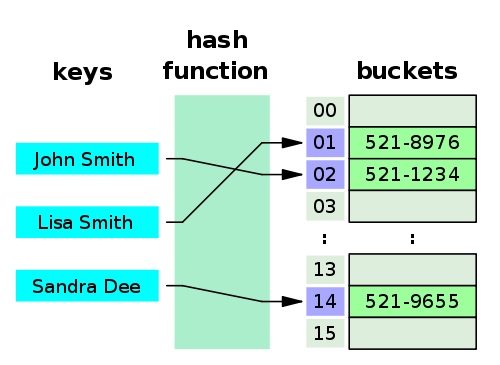 Un petit annuaire téléphonique comme table de hachage — Wikipédia Un petit annuaire téléphonique comme table de hachage — Wikipédia
Un petit annuaire téléphonique comme table de hachage — Wikipédia Un petit annuaire téléphonique comme table de hachage — Wikipédia
Lorsqu’une table de hachage est créée, il s’agit en réalité d’une structure de données très basée sur un tableau, et peut généralement être créée avec une capacité initiale. La table de hachage se compose d’un tableau d’emplacements ou de compartiments contenant les valeurs. Lorsqu’une table de hachage est créée, il s’agit en fait d’une structure de données très basée sur un tableau qui peut généralement être créée avec une capacité initiale. Une table de hachage se compose d’un tableau d’emplacements ou de compartiments contenant des valeurs.
Lors de l’ajout d’une paire clé-valeur, il prendra notre clé et l’exécutera via la fonction de hachage, obtenant une valeur de hachage spécifique (généralement un entier). Lors de l’ajout d’une paire clé-valeur, il prend notre clé et l’exécute via une fonction de hachage, ce qui donne une valeur de hachage spécifique (généralement un entier).
Si cette valeur de hachage est grande, vous devrez peut-être la simplifier par rapport à la taille actuelle de la table de hachage. Si ce hachage est volumineux, vous devrez peut-être le simplifier en fonction de la taille actuelle de la table de hachage.
Ensuite, il attribuera la valeur à un élément du tableau avec l’index égal à la valeur entière de hachage renvoyée. Il attribuera ensuite cette valeur à un élément du tableau avec un index égal à la valeur entière hachée renvoyée.
// adding a key-value pair
hash_table.add(key, value)
// what happen behind the scene
index = hash(key)
index = index % array_size
array[index] = value
Accéder à une valeur donnée avec une clé suit la même idée. Il prendra cette clé, l’exécutera via exactement la même fonction de hachage, et pourra ensuite accéder directement à un emplacement spécifique contenant la valeur que nous recherchons. Accéder à la valeur d’une clé donnée suit la même idée. Il prend cette clé, l’exécute via exactement la même fonction de hachage, puis peut accéder directement à un emplacement spécifique contenant la valeur que nous recherchons.
Il n’y a pas de recherche linéaire, pas de recherche binaire, pas de parcours de liste. Nous allons directement à l’élément dont nous avons besoin. Pas de recherches linéaires, pas de recherches binaires, pas de listes traversantes. Nous obtenons directement l’élément dont nous avons besoin.
Gestion des conflits de gestion des collisions
Nous pouvons nous attendre à ce qu’une collision de hachage se produise ; lorsque nous obtenons la même valeur de hachage pour différentes clés. Mais comment le gérer ? Nous pouvons nous attendre à ce que des collisions de hachage se produisent ; lorsque nous obtenons la même valeur de hachage pour différentes clés. Mais comment le gérer ?
Lorsque nous ajoutons une nouvelle paire clé-valeur et qu’une collision se produit, cela placera cette valeur au même emplacement, même s’il existe une autre valeur existante à cet emplacement. Lorsque nous ajoutons une nouvelle paire clé-valeur et qu’une collision se produit, cette valeur sera placée à la même position, même s’il existe une autre valeur existante à cette position.
Désormais, les implémentations de tables de hachage disposent de différentes manières de gérer automatiquement ce problème. Celles-ci vont du fait que chaque emplacement contient une collection simple, comme un tableau ou une liste chaînée. Désormais, les implémentations de tables de hachage disposent de différentes manières de gérer cela automatiquement. Chaque emplacement contient une collection simple, telle qu’un tableau ou une liste chaînée.
Ainsi, nous serions toujours en mesure d’accéder à n’importe quel emplacement très rapidement, mais une fois arrivés à l’emplacement avec plusieurs valeurs, la table de hachage parcourra cette liste interne pour trouver ce que nous recherchons. Nous pouvons donc toujours accéder à n’importe quel emplacement très rapidement, mais une fois que nous arrivons à un emplacement avec plusieurs valeurs, la table de hachage parcourt cette liste interne pour trouver ce que nous recherchons.
Chaque nœud de la liste chaînée contiendra à son tour la valeur associée à une clé spécifique. De plus, il contiendra cette clé ou une référence à cette clé. Car en cas de plusieurs valeurs au même emplacement, nous devons savoir à quelle clé appartient cette valeur. Chaque nœud de la liste chaînée contient à son tour une valeur associée à une clé spécifique. De plus, il contiendra la clé ou une référence à la clé. Car pour plusieurs valeurs au sein d’une même position, nous devons savoir à quelle clé appartient cette valeur.
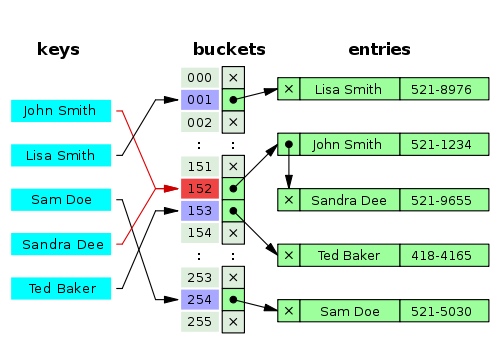 Collision de hachage résolue par chaînage séparé — Wikipédia Collision de hachage résolue par chaînage séparé — Wikipédia
Collision de hachage résolue par chaînage séparé — Wikipédia Collision de hachage résolue par chaînage séparé — Wikipédia
C’est ce qu’on appelle la « technique de chaînage séparé » dans les tables de hachage. Il existe désormais d’autres techniques pour gérer les collisions dans les tables de hachage, notamment l’adressage ouvert, le hachage Cuckoo, la marelle et le hachage Robin des Bois. Il s’agit de la « technique de liaison indépendante » dans les tables de hachage. Aujourd’hui, il existe d’autres techniques pour gérer les collisions au sein des tables de hachage, notamment l’adressage ouvert, le hachage coucou, la marelle et le hachage Robin des Bois.
Écriture de fonctions de hachage Écriture de fonctions de hachage
Lorsque vous souhaitez stocker des paires clé-valeur à l’aide d’une structure de données de table de hachage, la plupart des objets ont probablement déjà une fonction de hachage. Le comportement par défaut est généralement de renvoyer un entier ; calculé à partir de l’adresse mémoire de cet objet. Lorsque vous souhaitez utiliser une structure de données de table de hachage pour stocker des paires clé-valeur, la plupart des objets ont probablement déjà une fonction de hachage. Le comportement par défaut consiste généralement à renvoyer un entier ; calculé à partir de l’adresse mémoire de l’objet.Si jamais vous remplacez le comportement d’égalité dans votre classe, vous devez remplacer le comportement de hachage. Parce que les codes de hachage sont tellement liés à l’égalité, et si vous avez deux objets que vous considérez égaux, ils doivent renvoyer la même valeur de hachage. Si jamais vous remplacez le comportement d’égalité dans une classe, vous devez remplacer le comportement de hachage. Parce que les codes de hachage sont très étroitement liés à l’égalité, et si vous considérez deux objets égaux, ils doivent renvoyer la même valeur de hachage.
Encore une fois, si vous modifiez ce que signifie que vos objets soient égaux, vous devez également modifier ce que signifie hacher ces objets. De même, si vous modifiez la signification de l’égalité des objets, vous devez également modifier la signification du hachage de ces objets.
Les objets chaîne ont déjà remplacé leur propre comportement d’égalité et de hachage. Ainsi, si vous avez deux objets chaîne distincts, ils compteront toujours comme égaux et renverront le même hachage s’ils ont la même valeur, même s’il s’agit en fait d’objets chaîne distincts alloués dans différentes parties de la mémoire. Les objets chaîne ont remplacé leur propre comportement d’égalité et de hachage. Ainsi, si vous avez deux objets chaîne distincts, ils seront toujours égaux et renverront le même hachage s’ils ont la même valeur, même s’il s’agit en réalité d’objets chaîne distincts alloués dans différentes parties de la mémoire.
##Ensembles définis
Lorsque tout ce dont vous avez besoin est un grand conteneur, vous pouvez y mettre un tas d’articles, sans vous soucier de la séquence. Lorsque vous avez juste besoin d’un grand conteneur, vous pouvez y mettre un tas de choses et vous n’avez pas à penser à l’ordre.
Il n’y a pas de séquence spécifique comme avec une liste chaînée, une pile ou une file d’attente. Il n’y a pas de paires clé-valeur comme avec une table de hachage. Il n’y a pas de séquence spécifique, telle qu’une liste chaînée, une pile ou une file d’attente. Il n’y a pas de paires clé-valeur, tout comme une table de hachage.
It’s an unordered collection of items, with no repeated values.
它是一个无序的项目集合,没有重复的值。
Par non ordonné, je veux dire qu’il n’y a pas d’index comme un tableau. Non ordonné signifie qu’il n’y a pas d’index comme dans un tableau.
 Un sac d’épicerie rempli de nourriture Un sac de nourriture
Un sac d’épicerie rempli de nourriture Un sac de nourriture
Implémentation de l’ensemble Implémentation de l’ensemble
Les ensembles utilisent en fait la même idée de structure de données de tables de hachage la plupart du temps. Mais, au lieu de paires clé-valeur (hacher une clé et stocker sa valeur), lorsque vous utilisez un ensemble, la clé est également considérée comme la valeur (ou la valeur est affectée à une valeur factice ou par défaut). Les collections utilisent en fait la même idée de structure de données de table de hachage dans la plupart des cas. Cependant, contrairement aux paires clé-valeur (où la clé est hachée et sa valeur est stockée), lorsque vous travaillez avec des collections, les clés sont également considérées comme des valeurs (ou les valeurs sont affectées à des valeurs factices ou par défaut).
Ainsi, pour obtenir une valeur spécifique ou un objet spécifique dans l’ensemble, vous devez disposer de l’objet lui-même. Et la seule raison de le faire est de vérifier son existence. C’est ce qu’on appelle souvent la « vérification de l’adhésion ». Ainsi, pour obtenir une valeur spécifique dans la collection ou un objet spécifique, vous avez besoin de l’objet lui-même. La seule raison de le faire est de tester s’il existe. C’est ce qu’on appelle souvent « vérifier l’adhésion ».
Les ensembles peuvent être implémentés à l’aide d’un arbre de recherche binaire auto-équilibré pour les ensembles triés, ou d’une table de hachage pour les ensembles non triés. Les ensembles triés peuvent être implémentés à l’aide d’arbres de recherche binaires auto-équilibrés, ou des ensembles non triés peuvent être implémentés à l’aide de tables de hachage.
L’avantage des sets Les avantages des sets
Contrairement à un tableau, aux valeurs d’un tableau associatif ou à une liste chaînée, les ensembles n’autorisent pas les doublons. Vous ne pouvez pas ajouter deux fois le même objet, la même valeur au même ensemble. Contrairement aux valeurs des tableaux, des tableaux associatifs ou des listes chaînées, les ensembles n’autorisent pas les doublons. Le même objet et la même valeur ne peuvent pas être ajoutés deux fois à la même collection.
Les ensembles sont conçus pour une recherche très rapide, afin de pouvoir voir très rapidement si nous avons déjà une valeur contenue dans une collection. Les collections sont conçues pour des recherches rapides, afin que vous puissiez voir très rapidement si une valeur est déjà contenue dans la collection.
Vous pouvez également parcourir tous les éléments d’un ensemble, mais il se peut que vous n’ayez aucun ordre garanti. Vous pouvez également parcourir tous les éléments d’une collection et vous ne disposerez peut-être d’aucun ordre garanti.
##Arbres arbre L’idée d’une structure de données arborescente est que nous avons une collection de nœuds, et les nœuds ont des connexions, ils ont des liens entre eux. Le concept d’une structure de données arborescente est que nous avons un ensemble de nœuds, et ces nœuds ont des connexions, et il existe des liens entre eux.
Cela ressemble aux listes chaînées. Mais dans une liste chaînée, nous passons toujours d’un nœud à un seul nœud suivant spécifique. Dans une arborescence, chaque nœud peut être lié à un, deux ou plusieurs nœuds. Cela ressemble à une liste chaînée. Mais dans une liste chaînée, nous passons toujours d’un nœud à un nœud suivant spécifique. Dans un arbre, chaque nœud peut être lié à un, deux ou plusieurs nœuds.
It’s a collection of nodes, where each node might link to one, or two, or more nodes.
它是节点的集合,每个节点可能链接到一个、两个或多个节点。
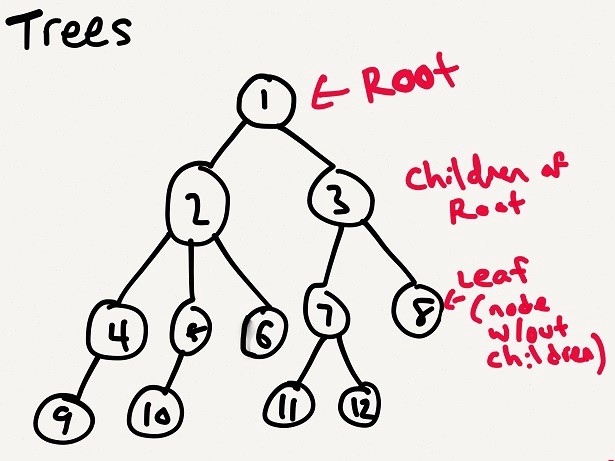 Un arbre - richardkho.com
Un arbre - richardkho.com
Terminologies des arbres Terminologie des arbres
Certaines terminologies accompagnent l’arbre. Vous pouvez en savoir plus à leur sujet ici. Ils sont essentiels pour comprendre et travailler avec les arbres. Quelques termes accompagnent cet arbre. Vous pouvez trouver plus d’informations à leur sujet ici. Ils sont essentiels à la compréhension et à l’étude des arbres.
Arbres binaires Arbre binaire
Un arbre binaire est simplement un arbre avec un maximum de deux nœuds enfants pour tout nœud parent. Les arbres binaires sont souvent utilisés pour implémenter une structure merveilleusement consultable appelée « arbre de recherche binaire » ou « BST ». Un arbre binaire est un arbre avec au plus deux nœuds enfants pour tout nœud parent. Les arbres binaires sont souvent utilisés pour implémenter une structure de recherche sophistiquée appelée « arbre de recherche binaire » ou « BST ».
##Arbres de recherche binaire (BST) Arbre de recherche binaire (BST)
It’s a specific type of binary tree, where the left child node is less than its parent, and a right child node is greater than its parent.
它是一种特定类型的二叉树,其中左子节点小于其父节点,而右子节点大于其父节点。
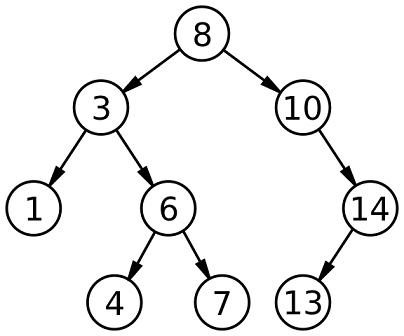 Un arbre de recherche binaire (BST) — Wikipédia Un arbre de recherche binaire (BST) — Wikipédia
Un arbre de recherche binaire (BST) — Wikipédia Un arbre de recherche binaire (BST) — Wikipédia
Comment fonctionnent les arbres de recherche binaires ? Comment fonctionnent les arbres de recherche binaires ?
La règle est que le nœud enfant gauche doit être inférieur à ses parents, et qu’un nœud enfant droit doit être supérieur à ses parents, et cette règle s’applique tout au long de l’arborescence. La règle est que le nœud enfant gauche doit être plus petit que son nœud parent et que le nœud enfant droit doit être plus grand que son nœud parent, et cette règle se poursuit dans l’arborescence.Et au fur et à mesure que nous insérons de nouveaux nœuds avec des valeurs, la règle sera toujours suivie pour garantir que l’arborescence reste triée. Lorsque nous insérons un nouveau nœud avec une valeur, des règles seront toujours suivies pour garantir que l’arborescence reste triée.
Il s’agit donc d’une structure de données qui reste naturellement triée et elle est parfois appelée « un arbre trié » ou « un arbre ordonné ». Par conséquent, il s’agit d’une structure de données qui maintient naturellement l’ordre, et est parfois appelée « arbre trié » ou « arbre ordonné ».
Stockage des nœuds sous forme de paires clé-valeur Stockage des nœuds sous forme de paires clé-valeur
Les arbres de recherche binaires sont souvent utilisés pour stocker des paires clé-valeur, ce qui signifie que les nœuds sont constitués d’une clé et d’une valeur associée. Et c’est la clé qui serait utilisée pour trier les nœuds en conséquence dans un arbre de recherche binaire. Les arbres de recherche binaires sont généralement utilisés pour stocker des paires clé-valeur, c’est-à-dire que les nœuds sont constitués d’une clé et d’une valeur associée. C’est la clé pour trier les nœuds dans un arbre de recherche binaire.
Doublons
Vous ne pouvez pas avoir de clés en double, tout comme vous n’avez pas de clés en double dans une table de hachage ou même dans un tableau. Il ne peut pas y avoir de clés en double, tout comme il ne peut pas y avoir de clés en double dans une table de hachage ou même dans un tableau.
Ajout et accès à des nœuds Ajout et accès à des nœuds
L’ajout et l’accès à des nœuds suivent la même règle mentionnée ci-dessus. Si le nœud actuel est inférieur à, allez à droite, s’il est supérieur à, allez à gauche. L’ajout et l’accès à des nœuds suivent les mêmes règles que ci-dessus. Si le nœud actuel est plus petit, allez à droite, s’il est plus grand, allez à gauche.
Récupérer les nœuds dans l’ordre Récupérer les nœuds dans l’ordre
L’autre avantage est que les arbres de recherche binaires restent triés. Ainsi, si nous récupérons les éléments de gauche à droite, de bas en haut, nous les sortirons tous dans l’ordre. Un autre avantage est que les arbres de recherche binaires maintiennent l’ordre. Ainsi, si nous récupérons les éléments de gauche à droite et de bas en haut, nous les remettrons dans l’ordre.
Arbre déséquilibré Arbre déséquilibré
C’est lorsque l’arbre a plus de niveaux de nœuds à droite qu’à gauche (ou vice versa). Lorsqu’il y a plus de nœuds à droite de l’arbre qu’à gauche (et vice versa).
Bien qu’il soit inhabituel que ce genre de chose se produise, nous ne pouvons pas toujours garantir que la manière dont les données sont ajoutées nous permettra de construire un arbre avec une structure parfaitement symétrique sur toute sa longueur. Bien que cela se produise rarement, nous ne pouvons pas toujours garantir que nous ajoutons des données de manière à nous permettre de construire un arbre avec une structure complètement symétrique.
Dans ce cas on dit que notre arbre est déséquilibré ; Il y a plus de niveaux d’un côté que de l’autre. Et nous devrions effectuer plus de vérifications pour rechercher, insérer ou supprimer des valeurs sur le côté droit que sur le côté gauche (ou vice-versa). Dans ce cas, on dit que l’arbre est déséquilibré ; un côté a plus de niveaux d’énergie que l’autre. Nous devons effectuer plus de vérifications pour rechercher, insérer ou supprimer une valeur à droite qu’à gauche (ou vice versa).
Implémentations de l’arbre de recherche binaire Implémentation de l’arbre de recherche binaire
Ce dont nous avons parlé est l’idée abstraite d’une structure de données d’arbre de recherche binaire. Mais il existe plusieurs implémentations de cette idée d’arbre de recherche binaire qui sont des arbres de recherche binaires auto-équilibrés. Ce dont nous avons discuté est l’idée abstraite d’une structure de données d’arbre de recherche binaire. Cependant, il existe plusieurs implémentations de cette idée d’arbre de recherche binaire qui sont des arbres de recherche binaires auto-équilibrés.
L’idée importante pour équilibrer un arbre de recherche binaire est que le nombre de niveaux est à peu près égal les uns aux autres. Nous n’avons pas trois niveaux à gauche et vingt à droite. L’idée importante pour équilibrer un arbre de recherche binaire est que le nombre de niveaux est approximativement égal. Il n’y a pas trois étages à gauche ni vingt étages à droite.
Des exemples d’arbres auto-équilibrés pourraient être : les arbres Rouge-Noir, AVL ou Adelson-Velskii et Landis, Splay, Scapegoat, et plus encore. Des exemples d’arbres auto-équilibrés peuvent être : les arbres rouge-noir, AVL ou Adelson-Velskii et Landis, les arbres Splay, les arbres bouc émissaire, etc.
Arbre de recherche binaire contre table de hachage Arbre de recherche binaire contre table de hachage
Les deux sont rapides pour l’insertion, rapides pour la suppression, rapides pour accéder à n’importe quel élément, même de grande taille. Mais comme les arbres de recherche binaires restent triés, ils nous permettent d’extraire tous les éléments de l’arbre dans l’ordre, là où la table de hachage ne garantit pas un ordre spécifique. Les deux méthodes permettent une insertion et une suppression rapides et un accès rapide à n’importe quel élément, même les plus volumineux. Cependant, étant donné que les arbres de recherche binaires maintiennent l’ordre, ils nous permettent de retirer tous les éléments de l’arbre dans l’ordre, alors que les tables de hachage ne peuvent pas garantir un ordre spécifique.
##Tas tas Les tas sont généralement implémentés en utilisant l’idée d’un arbre binaire, pas un arbre de recherche binaire mais quand même un arbre binaire. C’est un moyen d’implémenter d’autres types de données abstraits comme la file d’attente prioritaire. Le tas est généralement implémenté en utilisant l’idée d’un arbre binaire, pas un arbre de recherche binaire, mais un arbre binaire. Ils constituent un moyen d’implémenter d’autres types de données abstraits tels que les files d’attente prioritaires.
It’s a specific type of binary tree, where we add nodes from top to bottom, left to right, and child nodes must be less (or greater) than or equal their parents.
这是一种特定类型的二叉树,我们从上到下、从左到右添加节点,子节点必须小于(或大于)或等于它们的父节点。
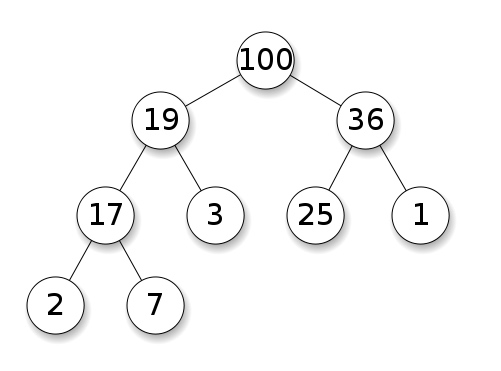 Max Heap - Wikipédia Le plus grand tas - Wikipédia
Max Heap - Wikipédia Le plus grand tas - Wikipédia
Par conséquent, nous remplissons complètement n’importe quel niveau avant de passer au suivant. Nous n’avons donc pas à craindre que l’arbre ne soit déséquilibré comme le peut un arbre de recherche binaire. Nous remplirons donc complètement n’importe quel niveau avant de passer au niveau suivant. Nous n’avons donc pas à craindre que l’arbre ne soit déséquilibré comme un arbre de recherche binaire.
Tas min/max
Un tas min indique que tout nœud enfant doit être supérieur (ou égal) à son nœud parent, tandis qu’un tas max indique que tout nœud enfant doit être inférieur (ou égal) à son nœud parent. Cependant, peu nous importe si un nœud est inférieur ou supérieur à son frère. Min-heap indique que tout nœud enfant doit être supérieur (ou égal à) son nœud parent, tandis que max-heap indique que tout nœud enfant doit être inférieur (ou égal à) son nœud parent. Cependant, peu nous importe si un nœud est plus petit ou plus grand que ses frères et sœurs.
Comment fonctionnent les tas ? Comment fonctionne le tas ?
Donc, en cas de Min Heap : Donc, pour un tas min :1. Nous continuons à ajouter des éléments de haut en bas, de gauche à droite 2. Ensuite, comparez avec le nœud parent ; Est-il inférieur à son parent ? Ensuite, comparez avec le nœud parent ; Est-il inférieur à son parent ? 3. Si tel est le cas, échangez le nœud avec son parent, 4. Continuez à suivre les étapes 2 à 3 jusqu’à ce que le nœud soit supérieur à son parent (ou qu’il devienne le nœud racine). comme indiqué. Continuez à exécuter les étapes 2 à 3 jusqu’à ce que le nœud soit plus grand que son parent (ou qu’il devienne le nœud racine).
Ce petit échange de nœuds permet à un tas de rester organisé. Cet échange de petits nœuds permet au tas de rester organisé.
Le tas n’est pas entièrement trié Le tas n’est pas complètement trié
Contrairement à un arbre de recherche binaire, qui reste trié et où nous pouvons facilement parcourir l’arbre et tout récupérer dans l’ordre. Contrairement aux arbres de recherche binaires, qui maintiennent l’ordre, nous pouvons facilement parcourir l’arbre et tout récupérer dans l’ordre.
Parce que si vous remarquez qu’à un niveau particulier au-delà de la racine, les valeurs ne doivent pas nécessairement être dans un ordre spécifique, tant qu’elles sont toutes supérieures (ou inférieures) à leur parent. Parce que si vous remarquez, à un niveau particulier après la racine, les valeurs ne doivent pas nécessairement apparaître dans un ordre particulier, tant qu’elles sont toutes supérieures (ou inférieures) à leur parent.
L’un des avantages de cette méthode est qu’un tas n’a pas besoin de se réorganiser autant que cela pourrait être nécessaire avec un arbre de recherche binaire. L’un des avantages de ceci est que le tas n’a pas besoin de se réorganiser autant qu’avec un arbre de recherche binaire.
La seule chose dont nous pouvons être sûrs, c’est que le nœud parent sera toujours inférieur ou supérieur à ses nœuds enfants, et donc la valeur minimale ou maximale sera toujours en haut. Une chose dont nous pouvons être sûrs est qu’un nœud parent est toujours plus petit ou plus grand que ses enfants, donc la valeur minimale ou maximale est toujours en haut.
Et par conséquent, les tas sont très utiles pour l’idée d’une file d’attente prioritaire. Par conséquent, le tas est particulièrement utile pour le concept de files d’attente prioritaires.
##Graphiques Graphiques
Les limitations d’un arbre n’existent plus ici. Un nœud peut être lié à plusieurs autres nœuds, sans séquence spécifique, sans nœud racine. Les limites des arbres n’existent plus. Un nœud peut être lié à plusieurs autres nœuds sans ordre particulier et sans nœud racine.
C’est une collection de nœuds, où un nœud peut être lié à plusieurs autres nœuds, sans séquence spécifique, sans nœud racine. Il s’agit d’un ensemble de nœuds où un nœud peut être lié à plusieurs autres nœuds, sans ordre particulier et sans nœud racine.
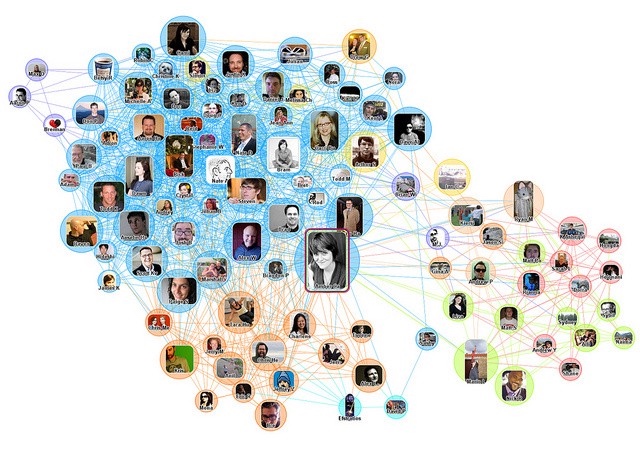 Un graphique d’un réseau social
Schéma du réseau social
Un graphique d’un réseau social
Schéma du réseau social
Théorie des graphes en mathématiques Théorie des graphes en mathématiques
Parce que les graphes en informatique sont si étroitement liés à la théorie des graphes en mathématiques. Il est courant d’entendre des termes mathématiques utilisés. Ainsi, dans la théorie des graphes, nous appelons les nœuds « sommets » et les liens entre eux sont appelés « arêtes ». Parce que le graphisme en informatique et la théorie graphique en mathématiques sont étroitement liés. Il est très courant d’utiliser des termes mathématiques. Par conséquent, dans la théorie des graphes, nous appelons les nœuds des « sommets » et les liens entre eux des « arêtes ».
Utilisation des graphiques Utilisation des graphiques
Nous pourrions utiliser un graphe pour modéliser un réseau social avec pour chaque nœud une personne. Ou encore, modéliser les distances entre les villes. Nous pourrions modéliser un réseau Ethernet dans un bureau, dans un bâtiment entier ou dans une ville. Nous pouvons utiliser un graphique pour modéliser un réseau social avec des nœuds pour chaque personne. Vous pouvez également modéliser la distance entre les villes. Nous pouvons modéliser un réseau Ethernet dans un bureau, un bâtiment entier ou une ville.
Graphiques directs et indirects Graphiques directs et indirects
Nous pouvons également dire si ces bords doivent avoir une direction vers eux ou non. On peut aussi dire si ces arêtes doivent avoir une direction.
Dans certaines situations, il est logique que toute arête, toute connexion entre deux sommets, soit à sens unique ; Ainsi, le nœud A est connecté au nœud B, alors que l’inverse n’est pas vrai ; le nœud B n’est PAS connecté au nœud A. Dans certains cas, toute arête, toute connexion entre deux sommets est à sens unique ; par conséquent, le nœud A est connecté au nœud B, mais pas l’inverse ; le nœud B n’est pas connecté au nœud A.
Dans d’autres situations, vous souhaiterez peut-être pouvoir suivre ce bord, ce lien, dans les deux sens ; Ainsi, le nœud A est connecté au nœud B, et le nœud B est également connecté au nœud A. Dans d’autres cas, vous souhaiterez peut-être suivre ce bord, ce lien, dans n’importe quelle direction ; Le nœud A se connecte au nœud B et le nœud B se connecte au nœud A.
Graphiques pondérés Graphique pondéré
Vous pouvez également attribuer un poids à chaque bord ; associant un numéro, à chacune des arêtes. Vous pouvez également attribuer un poids à chaque arête ; associer un numéro à chaque arête.
Vous pourriez faire cela pour représenter, par exemple, les distances entre les villes, si vous essayiez de calculer l’itinéraire le plus court entre plusieurs emplacements. Vous pouvez également utiliser un poids pour indiquer quels bords sont prioritaires sur les autres bords. Vous pouvez représenter, par exemple, la distance entre les villes si vous souhaitez calculer l’itinéraire le plus court entre plusieurs emplacements. Vous pouvez également utiliser des poids pour indiquer quels bords sont préférés aux autres.
##Types de données abstraits (ADT) types de données abstraits (adt)
Avant de plonger dans les types de données abstraits, ce qu’ils sont et la différence entre eux et d’autres concepts. Définissons ce qu’on entend par type de données. Avant de nous plonger dans les types de données abstraits, comprenons ce qu’ils sont et en quoi ils diffèrent des autres concepts. Définissons ce que signifient les types de données.
Type de données Type de données
Le type de données d’une variable détermine les valeurs qu’elle peut contenir, ainsi que les opérations qui peuvent y être effectuées.
Les types de données comprennent : les types de données primitifs, complexes ou composites et abstraits. Les types de données incluent : les types de données de base, les types de données complexes ou les types de données composites et les types de données abstraits.
Un type de données abstrait (ADT) Type de données abstrait (ADT)C’est un type de données, tout comme les types de données primitifs entiers et booléens. Un ADT se compose non seulement d’opérations, mais également de valeurs des données sous-jacentes et de contraintes sur les opérations.
Il s’agit d’un type de données, tout comme les types de données primitifs entiers et booléens. ADT contient non seulement les opérations, mais également les valeurs des données sous-jacentes et les contraintes sur les opérations.
Une contrainte pour une pile serait que chaque pop renvoie toujours l’élément le plus récemment poussé qui n’a pas encore été poppé. La contrainte de la pile est que chaque pop renvoie toujours l’élément le plus récemment poussé qui n’a pas encore été poppé.
La mise en œuvre réelle d’un ADT est abstraite et nous n’avons pas à nous en soucier. Ainsi, la manière dont une pile est réellement implémentée n’est pas si importante. Une pile peut être et est souvent implémentée en arrière-plan à l’aide d’un tableau dynamique, mais elle pourrait plutôt être implémentée avec une liste chaînée. Cela n’a vraiment pas d’importance. La mise en œuvre réelle d’ADT est abstraite et nous n’avons pas besoin de nous en soucier. La manière dont la pile est implémentée n’a donc pas d’importance. Les piles peuvent et sont généralement implémentées à l’aide de tableaux dynamiques sous le capot, mais elles peuvent également être implémentées à l’aide de listes chaînées. Cela n’a vraiment pas d’importance.
Les listes, les piles, les files d’attente et bien plus encore sont tous des types de données abstraits. Les listes, les piles, les files d’attente, etc. sont tous des types de données abstraits.
Un type de données abstrait et une structure de données Type de données abstrait et une structure de données
ADT n’est pas une alternative à une structure de données, ce sont des concepts différents. ADT ne remplace pas les structures de données, ce sont des concepts différents.
Lorsque nous parlons de structure de données de pile, nous faisons référence à la façon dont les piles sont implémentées et organisées dans la mémoire. Mais, lorsque nous parlons de pile ADT, nous faisons référence au type de données de pile qui a un ensemble d’opérations définies, les contraintes des opérations et les valeurs possibles. Lorsque nous parlons de structure de données de pile, nous faisons référence à la manière dont la pile est implémentée et organisée en mémoire. Cependant, lorsque nous parlons de pile ADT, nous entendons un type de données de pile qui a un ensemble défini d’opérations, de contraintes d’opération et de valeurs possibles.
Nous ne nous soucions pas de l’implémentation sous-jacente, comme lors de l’utilisation d’entiers, nous sommes abstraits de la façon dont les entiers sont représentés dans la mémoire, nous ne nous intéressons qu’aux opérations (ajouter, soustraire,…) et aux valeurs possibles (…, −2, −1, 0, 1, 2, …). Nous ne nous soucions pas de l’implémentation sous-jacente, car lorsqu’on travaille avec des entiers, on s’éloigne de la représentation des entiers en mémoire, on ne s’intéresse qu’aux opérations (addition, soustraction, …), et aux valeurs possibles (…−2−1,0,1,2,…).
Les structures de données peuvent implémenter un ou plusieurs types de données abstraits (ADT) particuliers, qui spécifient les opérations pouvant être effectuées sur une structure de données. Une structure de données peut implémenter un ou plusieurs types de données abstraits (ADT) spécifiques, qui spécifient les opérations pouvant être effectuées sur la structure de données.
Un type de données abstrait n’est PAS une classe abstraite Un type de données abstrait n’est PAS une classe abstraite
Les deux n’ont rien à voir l’un avec l’autre. Une classe abstraite définit uniquement les opérations, parfois avec des commentaires décrivant les contraintes, laissant l’implémentation réelle aux classes héritières. Ni l’un ni l’autre n’a rien à voir avec l’autre. Les classes abstraites définissent uniquement des opérations, parfois avec des annotations décrivant les contraintes, laissant l’implémentation réelle aux classes héritières.
Bien que les ADT soient souvent implémentés sous forme d’interfaces (classes abstraites) comme en Java. Par exemple, l’interface List en Java définit les opérations de List ADT, tandis que les classes héritières définissent l’implémentation réelle (structure de données). Alors que les adts sont généralement implémentés sous forme d’interfaces (classes abstraites), comme en Java. Par exemple, l’interface List en Java définit les opérations de List ADT, tandis que les classes héritées définissent l’implémentation réelle (structure de données).
Mais ce n’est pas toujours le cas. Par exemple, Java a une classe de pile. C’est une classe concrète ordinaire, mais une pile est également un type de données abstrait, ce qui signifie qu’elle représente l’idée d’avoir une structure de données dernier entré, premier sorti. Ainsi, stack est une véritable classe concrète et c’est aussi un type de données abstrait. Mais ce n’est pas toujours le cas. Par exemple, Java a une classe de pile, qui est une classe concrète normale, mais la pile est également un type de données abstrait, c’est-à-dire qu’elle représente une structure de données dernier entré, premier sorti. Stack est une classe concrète et un type de données abstrait.
Un type de données abstrait est un concept théorique Un type de données abstrait est un concept théorique
Un type de données abstrait (ADT) est un concept théorique qui n’a aucun rapport avec la programmation de mots-clés. Le type de données abstrait (ADT) est un concept théorique qui n’a rien à voir avec la programmation de mots-clés.
Ainsi, si nous avons une pile, nous avons une structure de données dernier entré, premier sorti, que nous pouvons pousser, afficher et jeter un coup d’œil. C’est ce que nous attendons d’une pile qu’elle soit capable de faire. Qu’une pile soit implémentée en tant que classe concrète ou autre, elle a toujours l’idée d’une structure de données du dernier entré, premier sorti. Ainsi, si nous avons une pile, nous avons une structure de données LIFO que nous pouvons pousser, afficher et consulter. C’est ce que nous attendons de la pile. Que la pile soit implémentée en tant que classe concrète ou autre chose, elle a toujours le concept de structure de données dernier entré, premier sorti.
##ConclusionConclusion
Décider de la structure des données Déterminer la structure des données
Vous devez vous poser quelques questions clés avant de décider de la structure des données Avant de décider d’une structure de données, vous devez vous poser quelques questions clés
- De combien de données disposez-vous ? De combien de données disposez-vous ?
- À quelle fréquence cela change-t-il ? À quelle fréquence cela change-t-il ?
- Avez-vous besoin de le trier, avez-vous besoin de le rechercher ? Accès, insertion ou suppression plus rapide ? Accès, insertion ou suppression plus rapide ?
S’il existe un endroit où vous ne disposez que de quantités insignifiantes de données, cela n’aura pas beaucoup d’importance. À moins bien sûr que ces quantités de données changent si fréquemment ou que vous disposiez de grandes quantités de données. S’il n’y a qu’une petite quantité de données quelque part, cela n’a pas d’importance. À moins bien sûr que ces volumes de données changent très fréquemment ou que vous disposiez de beaucoup de données.### Structures de données immuables Structures de données immuables Maintenant, un principe général selon lequel les structures de données immuables ou de taille fixe ont tendance à être plus rapides et plus petites en mémoire que les structures mutables. Désormais, un principe général est que les structures de données immuables ou de taille fixe ont tendance à être plus rapides et plus petites en mémoire que les structures mutables.
Pourquoi devrions-nous restreindre les fonctionnalités des tableaux ? La raison en est que plus vous avez de contraintes (comme une taille fixe, un type de données spécifique,…), plus votre structure de données peut être rapide et petite. Pourquoi limiter les caractéristiques des tableaux ? La raison en est que plus il y a de contraintes (telles qu’une taille fixe, un type de données spécifique…), plus la structure des données sera rapide et petite.
Les pièges d’avoir une structure de données avec de nombreuses fonctionnalités (non restreintes) sont que le compilateur ne peut pas allouer la quantité idéale d’espace, il doit donc introduire une surcharge pour prendre en charge la flexibilité de la structure de données (comme différents types de données,…). L’inconvénient des structures de données avec de nombreuses fonctionnalités (sans restriction) est que le compilateur ne peut pas allouer une quantité idéale d’espace et doit donc introduire une surcharge pour prendre en charge la flexibilité de la structure de données (comme les différents types de données, …).
Améliorez les performances de votre code Améliorez les performances de votre code
Si vous examinez le code existant pour voir ce qu’il faut améliorer, voyez celui qui contient le plus de données. Il n’y a pas de meilleur moyen de tirer le meilleur parti de ces structures de données que de constater certaines des améliorations de performances que vous pouvez obtenir, simplement en passant d’une structure à une autre. Si vous examinez le code existant pour déterminer les points à améliorer, regardez où la plupart des données sont enregistrées. Lorsque vous voyez que vous pouvez obtenir des améliorations de performances en passant simplement d’une structure à une autre, il n’y a pas de meilleur moyen de vraiment tirer le meilleur parti de ces structures de données.
Différences de langues Différences de langues
Les algorithmes utilisés avec chaque structure de données diffèrent d’un langage à l’autre, et la mise en œuvre réelle de la structure de données diffère d’un langage à l’autre. Cela vaut donc la peine d’examiner de près votre documentation linguistique. Les algorithmes utilisés par chaque structure de données varient d’une langue à l’autre, et la mise en œuvre réelle de la structure de données varie d’une langue à l’autre. Il est donc nécessaire de revoir attentivement votre documentation linguistique.
What to read next
Want more posts about Algorithms?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Algorithms?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home