Estruturas de dados 1 – Aprofundando-se nas estruturas de dados
Estruturas de dados — Aprofundando-se nas estruturas de dados (Parte 1)
Estruturas de dados - Aprofundando-se nas estruturas de dados (Parte 1) Estruturas de dados - Aprofundando-se nas estruturas de dados (Parte 1)
Fonte do artigo: https://medium.com/omarelgabrys-blog/diving-into-data-structures-6bc71b2e8f92
[TOC]
Quando temos um problema de programação, mergulhamos no algoritmo, ignorando a estrutura de dados subjacente. E pior ainda, pensamos que usar outra estrutura de dados não fará muita diferença, embora pudéssemos melhorar enormemente o desempenho do nosso código escolhendo uma estrutura de dados alternativa. Quando encontramos um problema de programação, nos aprofundamos nos algoritmos, ignorando as estruturas de dados subjacentes. Para piorar a situação, não achamos que usar outra estrutura de dados fará muita diferença, embora pudéssemos melhorar muito o desempenho do nosso código escolhendo outra estrutura de dados.
O que é uma estrutura de dados O que é uma estrutura de dados
Não começa sem perguntar: qual é a estrutura de dados? Não começa perguntando: que diabos é a estrutura de dados?
É um arranjo intencional de uma coleção de dados que construímos. é um arranjo intencional da coleta de dados que construímos.
Arranjo Intencional Arranjo deliberado
O arranjo intencional significa o arranjo feito propositalmente para impor, para fazer cumprir, algum tipo de organização sistemática dos dados. O arranjo intencional refere-se a um arranjo proposital que visa alguma organização sistemática de dados. Arranjo deliberado refere-se ao arranjo deliberado de dados em alguma organização sistemática. Arranjo intencional refere-se a um arranjo intencional que impõe uma certa organização sistemática de dados.
Por ser útil, facilita a nossa vida e é fácil de gerenciar quando você mantém as informações relacionadas juntas. Por ser útil, facilita a nossa vida e é fácil de gerenciar quando você junta informações relevantes.
Estruturas de dados em nossa vida Estruturas de dados em nossa vida
Precisamos de estruturas de dados em nossos programas porque pensamos desta forma como seres humanos. Em nossos programas, precisamos de estruturas de dados porque é assim que nós, humanos, pensamos.
Uma receita é uma estrutura de dados real, assim como uma lista de compras, uma lista telefônica, um dicionário, etc. Todos eles têm uma estrutura, têm um formato. Uma receita é uma estrutura de dados real, assim como uma lista de compras, lista telefônica, dicionário, etc. Todos eles têm uma estrutura, todos têm um formato.
Estrutura de dados e programação orientada a objetos Estrutura de dados e programação orientada a objetos
Agora, se você é um programador orientado a objetos, pode estar pensando: Bem, não é isso que fazemos com classes e objetos? Se você é um programador orientado a objetos, pode estar pensando: não é isso que fazemos com classes e objetos?
Quero dizer, definimos esses objetos do mundo real em um programa porque pensamos dessa forma como seres humanos, ou pelo menos deveríamos fazê-lo. Quero dizer, definimos estes objetos do mundo real num programa porque pensamos como humanos, ou pelo menos deveríamos pensar dessa forma.
E sim, absolutamente. Objetos são um tipo de estrutura de dados e não o único. Sim claro. Um objeto é uma estrutura de dados, não a única.
Cinco Comportamentos Fundamentais Cinco Comportamentos Fundamentais
Como acessar, inserir, excluir, localizar e classificar. Estas são as operações que você provavelmente realizará. Como acessar, inserir, excluir, localizar e classificar. Estas são as ações que você provavelmente realizará.
Nem todas as estruturas de dados possuem os cinco comportamentos fundamentais. Nem todas as estruturas de dados possuem esses cinco comportamentos básicos.
Por exemplo, muitas estruturas de dados não suportam nenhum tipo de comportamento de pesquisa. É apenas uma grande coleção, um grande contêiner de coisas, e se você precisar encontrar algo, basta examinar tudo sozinho. E muitos não fornecem nenhum tipo de comportamento de classificação. Outros são classificados naturalmente. Por exemplo, muitas estruturas de dados não suportam nenhum tipo de comportamento de pesquisa, é apenas uma grande coleção, um grande contêiner de algo, e se você precisar encontrar algo, basta iterá-lo você mesmo. E muitos não oferecem nenhum comportamento de classificação. Outra ordenação natural.
Cada estrutura de dados tem sua própria maneira ou algoritmo diferente para classificar, inserir, localizar,… etc., por quê? Porque, devido à natureza da estrutura de dados, existem algoritmos utilizados com estrutura de dados específica, onde outros não podem ser utilizados. Cada estrutura de dados tem seu próprio jeito ou algoritmos diferentes para classificar, inserir, pesquisar, etc. Porque, devido à natureza das estruturas de dados, existem alguns algoritmos que funcionam com uma estrutura de dados específica e alguns outros algoritmos não podem ser utilizados.
Quanto mais eficiente e adequado for o algoritmo, mais você terá uma estrutura de dados otimizada. Esses algoritmos podem ser integrados ou implementados pelo desenvolvedor para gerenciar e executar essas estruturas de dados. Quanto mais eficiente e aplicável for o algoritmo, mais estruturas de dados otimizadas poderão ser obtidas. Esses algoritmos podem ser integrados ou implementados por desenvolvedores para gerenciar e executar essas estruturas de dados.
Sempre leia a documentação da linguagem e verifique o desempenho dos algoritmos utilizados com a estrutura de dados subjacente. Diferentes algoritmos podem ser usados com base nos dados (tamanho, tipo,…) que você possui. Sempre leia a documentação da linguagem e verifique o desempenho dos algoritmos usados com as estruturas de dados subjacentes. Diferentes algoritmos podem ser usados com base nos dados (tamanho dos dados, tipo,…).
Matrizes unidimensionais Matriz unidimensional
O array é a estrutura de dados mais fundamental e mais comumente usada em todas as linguagens de programação. O suporte para arrays unidimensionais geralmente é integrado diretamente na própria linguagem principal. Arrays são a estrutura de dados mais básica e comumente usada em todas as linguagens de programação. O suporte para arrays unidimensionais geralmente é integrado diretamente na própria linguagem principal.
Um array é uma coleção ordenada de itens, onde cada item dentro do array possui um índice. Uma matriz é uma coleção ordenada de itens e cada item da matriz possui um índice.
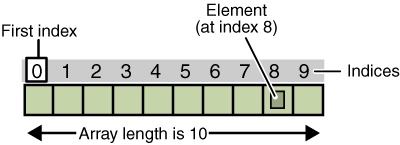
Índices Índice
Os índices estão em ordem, eles são índices baseados em zero na maioria dos idiomas, mas esse não é o caso com outros idiomas. Os índices são sequenciais, na maioria das linguagens são índices baseados em zero, mas em algumas outras linguagens este não é o caso.
Tamanho tamanhoOs arrays mais simples têm tamanho fixo, também chamados de imutáveis, ou seja, arrays imutáveis. Eles podem ser criados inicialmente em qualquer tamanho. Mas depois que o array é criado, você não pode adicionar ou remover elementos dele.
O array mais simples tem tamanho fixo, também conhecido como array imutável, ou seja, um array que não pode ser alterado. Eles podem ser criados inicialmente em qualquer tamanho. Mas uma vez que o array é criado, elementos não podem ser adicionados ou removidos dele.
Às vezes, a capacidade de adicionar ou remover elementos dinamicamente enquanto o programa está em execução é disponibilizada no array padrão de uma linguagem, e às vezes você tem vários tipos de array diferentes, dependendo se você precisa de um array fixo ou redimensionável. Às vezes, a capacidade de adicionar ou remover elementos dinamicamente enquanto o programa está em execução está disponível nos arrays padrão da linguagem e, às vezes, você pode usar vários tipos de array diferentes, dependendo se você precisa de um array fixo ou redimensionável.
Tipo de dados Tipo de dados
Matrizes simples normalmente são restritas a um tipo específico de dados. É uma matriz de números inteiros ou uma matriz de booleanos. Mas algumas linguagens permitem criar arrays apenas de objetos genéricos, o que significa que você pode colocar diferentes tipos de dados. Matrizes simples geralmente são limitadas a tipos específicos de dados. É uma matriz de números inteiros ou uma matriz de booleanos. Mas algumas linguagens permitem a criação de arrays de objetos genéricos, o que significa que diferentes tipos de dados podem ser colocados.
array = [123, true, "string", [1,2,3], object]
Matrizes multidimensionais Matriz multidimensional
Levando o array unidimensional um passo adiante, podemos ter arrays com duas dimensões. Indo mais longe no array unidimensional, podemos obter um array bidimensional.
É basicamente um array de arrays, onde cada item deste array contém outro array. É essencialmente um array de arrays, com cada item do array contendo outro array.
Portanto, qualquer elemento do array não é acessado com apenas um índice, mas precisamos de dois números para chegar até ele. Às vezes chamada de matriz ou tabela porque são, efetivamente, linhas e colunas de informações. Portanto, qualquer elemento do array não pode ser acessado com apenas um índice, mas são necessários dois números para acessá-lo. Às vezes chamada de matriz ou tabela porque, na verdade, são as linhas e colunas de informações.
Podemos levar o array bidimensional até os arrays tridimensionais e ainda mais. Podemos desenvolver ainda mais matrizes bidimensionais em matrizes tridimensionais e ainda mais.
Matrizes irregulares Matriz irregular
Quando temos um array Multidimensional, onde cada linha, cada item precisa ter um número diferente de itens. É onde os arrays Jagged entram em ação. Quando temos um array multidimensional, cada linha e cada item precisa ter um número diferente de itens. É aqui que os arrays irregulares entram em ação.
É um array multidimensional onde cada item pode ter tamanhos diferentes. é uma matriz multidimensional, cada entrada pode ter tamanhos diferentes.
 As linhas têm um número diferente de pedras
linhas com diferentes números de pedras
As linhas têm um número diferente de pedras
linhas com diferentes números de pedras
Quando usar matrizes irregulares Quando usar matrizes irregulares
Se você tiver uma matriz multidimensional que registra o número de vendas todos os dias. O primeiro índice é para o mês, enquanto o segundo é para o dia. Se você tiver uma matriz multidimensional registrando as vendas diárias. O primeiro índice é para o mês atual e o segundo índice é para o dia atual.
sales = [[124,153,135, …], [135,545,342,678,], …]
Você pode notar que janeiro tem 31 dias, enquanto 29 de fevereiro e assim por diante. Portanto, deixar os elementos irrelevantes vazios ou defini-los como 0 ou -99 ou algum outro valor nem sempre é desejável. Mas você não deve ter elementos que representem impossibilidades. Como em fevereiro, onde os dias 30 e 31 não existem. Você pode notar que janeiro tem 31 dias, enquanto fevereiro tem 29 e assim por diante. Portanto, nem sempre é aconselhável manter os elementos irrelevantes vazios ou defini-los como 0 ou -99 ou outros valores. Porém, você não deve ter elementos que representem o impossível. Por exemplo, em fevereiro não existem 30 e 31 dias.
Portanto, usando Jagged Arrays, podemos obter a média de vendas em um mês pegando todas as vendas daquele mês, somando todas e dividindo pelo número de dias daquele mês, sem ter que adicionar lógica para descobrir os dias que deveríamos ignorar. Assim, usando um array irregular, podemos obter a média de vendas de um mês, pegando todas as vendas do mês, somando-as e depois dividindo pelo número de dias do mês, sem adicionar lógica para calcular o número de dias que deve ser ignorado.
Matrizes redimensionáveis Matrizes redimensionáveis
A maioria das linguagens fornece algum tipo de array redimensionável, ou array dinâmico, ou mutável. Em Java, o array padrão tem tamanho fixo e um tipo de dados fixo, mas você também pode criar um array redimensionável usando ArrayList. A maioria das linguagens fornece algum tipo de array ajustável, dinâmico ou mutável. Em Java, os arrays padrão têm tamanho e tipo de dados fixos; no entanto, você também pode criar arrays redimensionáveis usando ArrayList.
Adicionando e Removendo Adicionando e Removendo
O local onde adicionamos um novo elemento ou removemos um existente é importante, porque adicionar ou remover um elemento no final é mais rápido do que em qualquer outro lugar. A posição onde você adiciona um novo elemento ou remove um elemento existente é importante, pois adicionar ou remover elementos no final é mais rápido do que em qualquer outro lugar.
Assim, os elementos deverão ser deslocados para a esquerda ou para a direita e reindexados; reordenado. Portanto, isso tem um impacto no desempenho. Portanto, o elemento deve ser movido para a esquerda ou para a direita e reindexado; o item deve ser pedido novamente. Portanto, isso tem um impacto no desempenho.
A forma de mudar difere de idioma para outro, alguns estarão mudando os itens no lugar, mas outros apenas copiarão todo o conteúdo do array antigo para um novo com o item sendo adicionado ou removido. Da forma como a conversão funciona, dependendo do idioma, alguns irão mover os itens no lugar, porém, alguns irão apenas copiar todo o conteúdo do array antigo para um novo array, adicionando ou removendo itens ao mesmo tempo.
Classificando matrizes Classificando matrizA classificação é sempre intensiva em termos computacionais, pode ser necessário fazê-lo, mas queremos minimizá-la. Portanto, manter-nos cientes da quantidade de dados que temos e da frequência com que solicitamos a classificação pode nos levar a escolher diferentes estruturas de dados.
A classificação é sempre intensiva em termos computacionais, pode ser necessário fazer isso, mas queremos minimizá-la. Portanto, compreender a quantidade de dados que temos e com que frequência necessitamos de classificação pode nos levar a escolher uma estrutura de dados diferente.
 Classificando as pessoas por altura —pleacher.com
Classificar por altura
Classificando as pessoas por altura —pleacher.com
Classificar por altura
A funcionalidade de classificação integrada A função de classificação integrada
Quando classificamos arrays, há coisas que você precisa entender sobre a funcionalidade de classificação integrada. Quando classificamos um array, você precisa conhecer a funcionalidade de classificação integrada.
Em segundo lugar, a funcionalidade de classificação integrada tentará classificar uma matriz existente ou criará outra cópia? A maioria das linguagens tentará classificar um array existente, enquanto algumas criarão uma nova cópia do array original para conter o array classificado. Segundo, a função de classificação integrada tenta classificar a matriz existente ou criar outra cópia? A maioria das linguagens tentará classificar o array existente, enquanto algumas criarão uma nova cópia do array original para conter o array classificado.
Classificando objetos personalizados Classificando objetos personalizados
Em linguagens orientadas a objetos, muitas vezes você tem matrizes de seus próprios objetos personalizados, não apenas matrizes de valores numéricos simples ou mesmo de strings. Em linguagens orientadas a objetos, você geralmente tem seu próprio array de objetos personalizados, não apenas um simples array de números ou mesmo um array de strings.
Quando você pede a essa matriz para classificar esses objetos usando a funcionalidade de classificação integrada na linguagem. Simplesmente não saberá como fazê-lo. Porque você precisa fornecer um pouco mais de informações sobre qual propriedade classificar de acordo. A matriz é então solicitada para classificar esses objetos usando a funcionalidade de classificação incorporada na linguagem. Simplesmente não sabe como fazê-lo. Porque você precisa fornecer mais informações sobre as propriedades de classificação correspondentes.
Assim, por exemplo, classifique os usuários por ID, nome ou data de nascimento. Isso define a propriedade do objeto para classificação de acordo. Por exemplo, classifique os usuários por ID, nome ou data de nascimento. Isso define as propriedades do objeto a serem classificadas de acordo.
Geralmente precisa apenas de algumas linhas e é normalmente chamado de comparador, ou função de comparação, ou método de comparação. Normalmente, apenas algumas linhas de código são necessárias e geralmente são chamadas de comparadores, funções de comparação ou métodos de comparação.
##Pesquisando Arrays Pesquisando arrays
Se quiséssemos saber se um valor específico existe em algum lugar de um array ou não, poderíamos fazer um loop sobre os elementos do array e verificar o valor naquela posição atual e ver se é igual ao objetivo ou não. Se quisermos saber se existe um valor específico no array, podemos percorrer os elementos do array e verificar o valor na posição atual para ver se é igual ao objetivo.
 Continue procurando mesmo debaixo da cama
Continue olhando até embaixo da cama
Continue procurando mesmo debaixo da cama
Continue olhando até embaixo da cama
O melhor cenário é que o primeiro elemento seja o valor que procuramos. O pior caso é que o valor esteja no final ou não apareça em nenhum lugar do array. Este método é conhecido como pesquisa linear ou pesquisa sequencial. Este é um método deselegante de força bruta. Na melhor das hipóteses, o primeiro elemento é o valor que procuramos. O pior cenário é que o valor apareça no final da matriz ou não apareça em nenhum lugar da matriz. Este método é chamado de pesquisa linear ou pesquisa sequencial. Este é um método de força bruta deselegante.
Embora as pesquisas lineares sejam simples de entender e fáceis de escrever e funcionarão, mas são lentas. E quanto mais elementos você tiver, mais lentos eles ficarão. Embora as pesquisas lineares sejam fáceis de entender, fáceis de escrever e funcionem, elas são lentas. Quanto mais elementos houver, mais lento será.
Os dados precisam ser ordenados Precisa classificar os dados
Se não houver ordem, nenhuma sequência previsível para os valores na matriz, então, pode não haver outras opções além de verificar todos os elementos da matriz. Se os valores no array não tiverem ordem, nem sequência previsível, então pode não haver outra opção senão verificar todos os elementos do array.
Portanto, os dados devem ser ordenados de forma que possamos usar um algoritmo diferente da pesquisa linear. Portanto, ter algum tipo de ordem nesses elementos é cada vez mais significativo. Portanto, os dados devem ser ordenados de alguma forma para que possamos usar outros algoritmos além da busca linear. Portanto, torna-se cada vez mais importante classificar esses elementos
O desafio da herança das estruturas de dados O desafio da herança das estruturas de dados
Às vezes, você pode concordar em usar uma capacidade de pesquisa lenta, porque a única maneira de consertar isso é classificar o array, o que, por sua vez, adicionará um impacto no desempenho que simplesmente não vale a pena. Às vezes você pode concordar em usar uma função de pesquisa lenta porque a única maneira de resolver o problema é classificar o array, o que, por sua vez, adiciona uma penalidade de desempenho que simplesmente não vale a pena.
Portanto, se você for pesquisar em um array uma vez, é melhor ter uma complexidade de O(N) para pesquisa linear do que O(NLogN) para classificação + O(LogN) para pesquisa. Se, no entanto, você for pesquisar muito, então, você pode primeiro classificar o array uma vez no início, e agora, você pode pesquisar com O(LogN) todas as vezes em vez da pesquisa linear O(N). Portanto, se você pesquisasse uma vez em um array, seria O(N) mais complicado para uma pesquisa linear do que classificação O(NLogN) + O(LogN). No entanto, se você for fazer muitas pesquisas, primeiro poderá classificar a matriz uma vez no início e agora poderá pesquisar com O(LogN) todas as vezes, em vez de O(N) com uma pesquisa linear.Você não pode ter uma estrutura de dados que seja igualmente boa em todas as situações. Uma estrutura de dados ordenada naturalmente requer menos tempo na busca de um elemento e mais tempo na inserção porque mantém a matriz ordenada. Enquanto um array básico requer mais tempo de pesquisa e menos tempo de inserção de elementos no final do array. Você não pode ter uma estrutura de dados igualmente boa em todas as situações. Uma estrutura de dados ordenada naturalmente requer menos tempo para procurar elementos e mais tempo para inserir porque mantém a ordem do array. Embora os arrays básicos exijam mais tempo de pesquisa, a inserção de elementos no final do array leva menos tempo
##Lista de listas
As listas são estruturas de dados bastante simples. Sua estrutura acompanha a sequência de itens. As listas são estruturas de dados muito simples. Está estruturado para acompanhar a ordem dos itens.
It’s a collection of items (called nodes) ordered in a linear sequence.
它是按线性顺序排列的项(称为节点)的集合。
Esses nós não precisam ser alocados um ao lado do outro na memória como um array. Os nós não precisam ser alocados adjacentemente na memória como arrays.
Existe um conceito teórico geral de programação de uma lista e existe a implementação específica de uma estrutura de dados de lista, que pode ter pegado essa ideia básica de lista e adicionado um monte de funcionalidades. As listas são implementadas como listas vinculadas (simples, duplamente, circulares,…) ou como matriz dinâmica. Há um conceito teórico geral de programação de listas e há uma implementação específica de uma estrutura de dados de lista que provavelmente pega esse conceito básico de lista e adiciona um monte de funcionalidades. As listas podem ser implementadas como listas vinculadas (listas vinculadas individualmente, listas vinculadas duplamente, listas vinculadas circulares, listas vinculadas circulares) ou como matrizes dinâmicas.
Uma matriz versus uma lista Matriz versus uma lista
Uma lista é um tipo diferente de estrutura de dados de um array. As listas são uma estrutura de dados diferente das matrizes.
A maior diferença está na ideia de acesso direto versus acesso sequencial. Matrizes permitem ambos; acesso direto e sequencial, enquanto as listas permitem apenas acesso sequencial. E isso ocorre devido à forma como essas estruturas de dados são armazenadas na memória. A maior diferença é o conceito de acesso direto e acesso sequencial. Matrizes permitem ambos; acesso direto e sequencial, enquanto as listas permitem apenas acesso sequencial. Isso ocorre devido à maneira como essas estruturas de dados são armazenadas na memória.
A estrutura da lista não suporta índice numérico como um array. A estrutura de uma lista não suporta indexação numérica como uma matriz.
##Listas vinculadas Lista vinculada
It’s a collection of nodes, where each node has a value and a link to the next node in the list.
它是节点的集合,每个节点都有一个值和到列表中下一个节点的链接。
O ponteiro do último nó aponta para NULL, ou terminador, ou um nó fictício. O ponteiro do último nó aponta para NULL, ou terminador, ou nó virtual.
 Lista vinculada - wikipedia
Lista de links - Wikipédia
Lista vinculada - wikipedia
Lista de links - Wikipédia
Devido à forma como é construído, adicionar e remover elementos é muito, muito mais fácil do que com um array. Devido à forma como é construído, adicionar e remover elementos é muito mais simples do que um array.
Mas, com matrizes, é necessário mudar para a esquerda ou para a direita para manter sua estrutura ordenada significativa. Mesmo adicionar elementos no final do array ainda pode exigir a realocação de todo o array para armazená-lo em uma área contígua da memória. No entanto, com matrizes, ele precisa ser deslocado para a esquerda ou para a direita para manter uma estrutura ordenada significativa. Mesmo se você adicionar um elemento ao final do array, ainda precisará realocar todo o array para que o array seja armazenado em uma área de memória contígua.
##Lista duplamente vinculada Lista duplamente vinculada
O que introduzimos é uma lista vinculada, mas para ser um pouco mais específico, ela é chamada de “Lista vinculada individualmente”. Também podemos ter uma “Lista Duplamente Vinculada”. Introduzimos uma lista vinculada, mas para ser mais específico, esta é a chamada “lista vinculada individualmente”. Também podemos ter uma “lista duplamente vinculada”.
Em vez de cada nó ter uma referência apenas ao próximo nó, adicionamos mais um dado que também tem uma referência ao nó anterior. Então, nos permite avançar e retroceder, percorrer a lista em qualquer direção. Em vez de cada nó ter apenas uma referência ao próximo nó, é adicionado outro dado que também tem uma referência ao nó anterior. Assim, permite-nos avançar e retroceder, percorrendo a lista em qualquer direção.
 Lista duplamente vinculada - wikipedia
Lista duplamente vinculada - Wikipédia
Lista duplamente vinculada - wikipedia
Lista duplamente vinculada - Wikipédia
As listas vinculadas na maioria dos idiomas são normalmente implementadas como listas duplamente vinculadas. Na maioria dos idiomas, as listas vinculadas são geralmente implementadas como listas duplamente vinculadas.
A lista vinculada simples versus duplamente vinculada A lista vinculada simples versus duplamente vinculada
A operação Adicionar é claramente menos trabalhosa em uma lista vinculada individualmente, porque a lista duplamente vinculada requer a alteração de mais links do que uma lista vinculada individualmente. Adicionar uma operação ** a uma lista vinculada individualmente é obviamente menos trabalhoso, pois uma lista duplamente vinculada requer mais alterações de link do que uma lista vinculada individualmente.
Para lista vinculada individualmente, assumimos que inserimos no início ou após algum nó específico. Para listas vinculadas individualmente, assumimos a inserção após o nó principal ou algum nó específico.
No caso de adicionar antes de algum nó, você precisa conhecer o nó antes desse nó, o que exigirá que você acesse sequencialmente todos os nós até encontrar o nó que procura. Se você deseja adicionar um nó antes de um determinado nó, você precisa conhecer os nós anteriores a esse nó, o que exigirá que você visite todos os nós sequencialmente até encontrar o nó que procura.
Remover é mais simples e potencialmente mais eficiente na lista duplamente vinculada, porque na lista simples, você precisa conhecer o nó antes do nó a ser excluído. Em uma lista duplamente vinculada, a exclusão é mais simples e provavelmente mais eficiente, porque em uma lista simples, você precisa conhecer o nó antes do nó que deseja excluir.
##Lista vinculada circular Lista vinculada circularEm uma lista vinculada individualmente, se o próximo ponteiro do último nó apontar de volta para o primeiro nó. Então, é “Lista Vinculada Circular”. E se o ponteiro anterior do primeiro nó apontar também para o último nó. Agora, isso seria considerado uma “Lista Duplamente Vinculada Circular”. Em uma lista vinculada individualmente, se o próximo ponteiro do último nó apontar para o primeiro nó. Depois, há a “lista vinculada circular”. Se o ponteiro anterior do primeiro nó apontar para o último nó. Agora, isso seria considerado uma “lista circular duplamente vinculada”.

Lista Circular Vinculada - wikipedia Lista circular vinculada - Wikipedia
Não é comum, mas pode ser útil para certos problemas. Então, se chegarmos ao final da lista e dissermos próximo, simplesmente começaremos de novo do início. Isso não é comum, mas pode ser útil para determinados problemas. Então, se chegarmos ao fim da lista, digamos a próxima, começaremos de onde começamos.
##Pilha de pilhas
Assim como os arrays e as listas, as pilhas e as filas também são coleções de itens. São apenas maneiras diferentes de armazenar vários itens. É a estrutura de dados do último a entrar, o primeiro a sair, sem se preocupar com índices numéricos. Assim como arrays e listas, pilhas e filas são coleções de itens. São apenas maneiras diferentes de acomodar vários projetos. É uma estrutura de dados do tipo último a entrar, primeiro a sair e não se preocupa com índices numéricos.
It’s a collection of items where we add and remove items to and from the top of the stack.
它是一个项集合,我们在堆栈顶部添加和删除项。
 Pilha de pratos sujos
pilha de pratos sujos
Pilha de pratos sujos
pilha de pratos sujos
Implementação de pilha Implementação de pilha
Uma pilha pode ser facilmente implementada usando um array ou uma lista vinculada As pilhas podem ser facilmente implementadas com arrays ou listas vinculadas
Uso de pilhas Uso de pilha
Stack não se limita apenas a modelar situações do mundo real (o mesmo para filas). Um dos melhores usos para uma pilha na programação é ao analisar código ou expressões, onde você precisa fazer algo como validar a quantidade correta de abertura e fechamento de chaves, colchetes ou parênteses. Stack não se limita a simular situações do mundo real (o mesmo vale para filas). Um dos melhores usos da pilha na programação é ao analisar código ou uma expressão e você precisa fazer algo como verificar o número correto de colchetes, colchetes ou colchetes de abertura.
As operações básicas das pilhas As operações básicas da pilha
São eles: push(), pop() e peek(). push serve para colocar um novo elemento no topo da pilha, e pop retornará (e removerá) o elemento no topo, enquanto peek obterá o elemento no topo sem removê-lo. São eles: push(), pop() e peek(). push é usado para colocar um novo elemento no topo da pilha, pop retornará (e removerá) o elemento superior e peek obterá o elemento superior sem removê-lo.
Pilhas versus matrizes versus listas vinculadas Pilhas versus matrizes versus listas vinculadas
Trabalhar com pilha é mais simples do que trabalhar com arrays ou listas vinculadas, porque há menos coisas que você pode fazer com uma pilha. Usar uma pilha é mais simples do que usar um array ou lista vinculada porque há menos coisas que você pode fazer com a pilha.
Esta é uma estrutura de dados intencionalmente limitada e intencionalmente restrita. Tudo o que fazemos é empurrar e estourar e talvez espiar. E se você estiver tentando fazer qualquer outra coisa com essa pilha, estará usando a estrutura de dados errada. Esta é uma estrutura de dados intencionalmente restrita. Tudo o que fazemos é empurrar, estourar ou espiar. Se quiser usar essa pilha para outras coisas, você está usando a estrutura de dados errada.
##Filas Fila
A principal diferença entre uma pilha e uma fila. As pilhas são as últimas a entrar, primeiras a sair (LIFO), enquanto as filas são as primeiras a entrar, primeiras a sair (FIFO). E assim como acontece com as pilhas, não deveríamos nem pensar em índices numéricos. Diferença chave entre pilha e fila. As pilhas são o último a entrar, primeiro a sair (LIFO), enquanto as filas são o primeiro a entrar, primeiro a sair (FIFO). Assim como a pilha, não deveríamos nem pensar em indexação numérica.
It’s a collection of items where we add items to the end and remove items from the front of the queue.
它是项的集合,我们在末尾添加项,并从队列前面删除项。
 Fila de pessoas na fila
Fila de pessoas na fila
Implementação de fila Implementação de fila
Tal como acontece com as pilhas, uma fila pode ser implementada usando um array ou uma lista vinculada. Assim como uma pilha, uma fila pode ser implementada usando um array ou uma lista vinculada.
Uso de filas Usar filas
As filas são muito comumente usadas em situações de simultaneidade para controlar quais tarefas estão aguardando para serem executadas e garantir que sejam executadas nessa ordem. As filas são muito comumente usadas em situações de simultaneidade para controlar as tarefas que aguardam para serem executadas e garantir que sejam processadas em ordem.
As operações básicas das filas As operações básicas da fila
Assim como uma pilha: add(), remove() e peek(). Assim como uma pilha: add(), remove() e peek().
Filas prioritárias fila prioritária
Algumas linguagens oferecem uma versão de fila, chamada fila prioritária. Isso permite organizar os elementos na fila com base em sua prioridade. Algumas linguagens fornecem uma versão de uma fila chamada fila prioritária. Isso permite organizar os elementos da fila de acordo com a prioridade.
It’s a queue, where items with higher priority step ahead of items with lower priority in the queue.
它是一个队列,在队列中优先级较高的项先于优先级较低的项。
Como funcionam as filas prioritárias Como funcionam as filas prioritárias
Quando você adiciona itens com a mesma prioridade, eles serão enfileirados normalmente na ordem de primeiro a entrar, primeiro a sair. Se algo vier com uma prioridade mais alta, ele irá à frente deles na fila. Quando você adiciona itens com a mesma prioridade, eles são enfileirados na ordem normal. Se surgir algo com prioridade mais alta, ele irá à frente deles na fila.
Definindo a prioridade Definindo a prioridade
Você pode definir com base em qual elemento tem prioridade maior, menor ou igual. Isso é feito implementando um comparador ou uma função de comparação (como ao classificar arrays), onde você fornece sua própria lógica para comparar a prioridade entre os elementos. Você pode definir com base na alta prioridade, baixa prioridade ou prioridade igual de um elemento. Isso pode ser conseguido implementando um comparador ou uma função de comparação (assim como classificar um array), onde você pode fornecer sua própria lógica ao comparar prioridades entre elementos.
##Deque fila duplaO deque, pronunciado “DEK”, é usado quando queremos aproveitar o poder da fila e da pilha, onde você pode adicionar ou remover do início ou do fim. Deque é pronunciado como “DEK” e usamos deque quando queremos aproveitar os recursos de filas e pilhas, onde podemos adicionar ou excluir do início ou do fim.
It’s a queue and a stack at the same time.
它同时是一个队列和一个堆栈。
##Matrizes Associativas Matriz associativa
Eles permitem usar chaves significativas para trabalhar com elementos em nossas estruturas de dados, em vez de trabalhar com índices numéricos como chaves. Isso fornece um relacionamento significativo entre a chave e o valor. Eles permitem que os elementos de uma estrutura de dados sejam processados usando chaves significativas em vez de índices numéricos como chaves. Isso fornece relacionamentos significativos entre chaves e valores.
It is a collection of key-value pairs.
它是键-值对的集合。
var user = {
firstName: "Bob",
lastName: "Jones",
age: 26,
email: "bob.jones@example.com"
};
A implementação de arrays associativos tem nomes diferentes. Em Objective-C e Python, eles são chamados de dicionários. As implementações de matrizes associativas têm nomes diferentes. Em Objective-C e Python, eles são chamados de dicionários.
A Ordem dos Elementos A ordem dos elementos
Ao contrário de um array básico, em um array associativo as chaves não precisam estar em nenhuma ordem específica. Porque a ordem não é uma preocupação em matrizes associativas. Ao contrário dos arrays básicos, as chaves em um array associativo não precisam estar em nenhuma ordem específica. Porque a ordem não tem nada a ver com matrizes associativas.
Claro, pode ser útil classificá-los por chave. Talvez você ache útil classificá-los por valor ou talvez nem precise classificá-los. Claro, você pode achar útil classificar por chave. Talvez você ache útil classificá-los por valor ou talvez nem precise classificá-los.
Duplicatas de chaves Duplicatas de chaves
Da mesma forma que você não obtém o mesmo número de índice aparecendo duas vezes em um array básico, não pode haver chaves duplicadas e as chaves devem ser exclusivas em um array associativo. Da mesma forma, o mesmo número de índice não pode aparecer duas vezes em um array básico, não pode haver chaves duplicadas e as chaves devem ser exclusivas em um array associativo.
Tipos de dados de chaves e valores tipos de dados de chave e valor
Geralmente você pode usar qualquer tipo de dados como chave ou valor. É comum usar uma string como chave. Geralmente, você pode usar qualquer tipo de dados como chave ou valor. Normalmente strings são usadas como chaves.
A maioria das matrizes associadas, sejam elas chamadas de dicionários, mapas ou hashes, são implementadas usando uma estrutura de dados de tabela hash. Então, começaremos fazendo hash e depois mergulharemos nas tabelas hash. A maioria das matrizes associativas são implementadas usando estruturas de dados de tabelas hash, sejam elas dicionários, mapas ou hashes. Então, começaremos com hashes e depois mergulharemos nas tabelas de hash.
##Hashing
Hashing é um conceito valioso em programação. É usado não apenas em estruturas de dados, mas em segurança, criptografia, gráficos e áudio. Hashing é um conceito valioso em programação. É usado não apenas para estruturas de dados, mas também para segurança, criptografia, gráficos e áudio.
It’s a way to take our data and run it through a function, which will return a small, simplified reference generated from that original data.
这是一种获取数据并通过函数运行数据的方法,函数将返回从原始数据生成的一个小的、简化的引用。
 Hashing é comumente usado com senhas Hashing é comumente usado com senhas
Hashing é comumente usado com senhas Hashing é comumente usado com senhas
A referência pode ser apenas um número inteiro, ou letras e números,…etc. A referência pode ser apenas um número inteiro, ou letras e números, etc.
Por que usar hash? Por que usar hash?
Porque ser capaz de pegar um objeto complexo e reduzi-lo a uma única representação inteira. Portanto, podemos usar esse valor inteiro para chegar a um determinado local na estrutura de dados. Porque você pode fazer hash de um objeto complexo em uma representação inteira. Portanto, podemos usar esse valor inteiro para chegar a um determinado local na estrutura de dados.
Hashing não é criptografia Hashing não é criptografia
As funções hash não são reversíveis; Eles são unilaterais. Portanto, você não pode converter um resultado de valor hash de volta aos dados originais. Portanto, você perde informações durante o hash, tudo bem, isso é intencional. As funções hash são irreversíveis; eles são unilaterais. Portanto, você não pode converter o resultado do hash de volta aos dados originais. Portanto, as informações são perdidas durante o processo de hash, e isso é intencional.
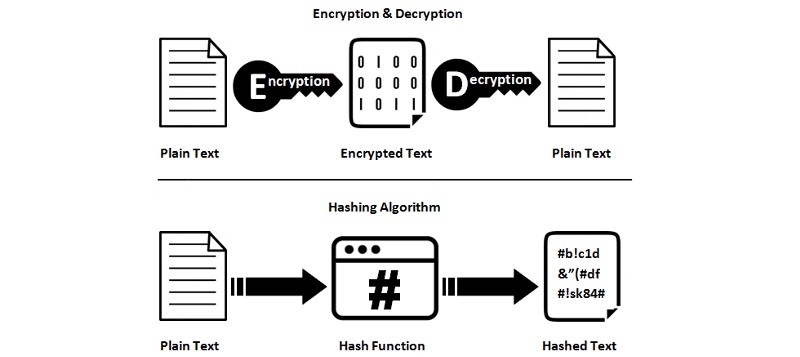 Hashing versus criptografia – ssl2buy.com Hashing versus criptografia – ssl2buy.com
Hashing versus criptografia – ssl2buy.com Hashing versus criptografia – ssl2buy.com
Implementação da função hash Implementação da função hash
Digamos que temos uma classe person definida e queremos uma função hash definida nesta classe. A função hash deve retornar uma referência única específica (geralmente um número inteiro) para um objeto pessoal específico. Este único número inteiro é gerado usando os dados de um objeto pessoa (nome, sobrenome, data de nascimento, etc.). Suponha que definimos uma classe de pessoa e queremos definir uma função hash nesta classe. A função hash deve retornar uma referência específica (geralmente um número inteiro) para um objeto pessoal específico. Este inteiro é gerado a partir dos dados do objeto pessoa (nome, sobrenome, aniversário, etc.).
Regras de hash Regras de hash
-
Se pegarmos exatamente o mesmo objeto, com os mesmos dados, e inseri-lo na função hash novamente, eu esperaria o mesmo resultado hash.
-
Se você tiver dois objetos diferentes que considere iguais, eles deverão retornar o mesmo valor de hash.
-
Embora dois objetos iguais devam produzir o mesmo valor de hash, dois valores de hash iguais não garantem que vieram de objetos iguais. Por quê? Porque dois objetos diferentes podem, em algumas circunstâncias, fornecer o mesmo resultado de uma função hash (consulte Colisão de hash). Dois objetos iguais devem produzir o mesmo valor de hash, mas não é garantido que dois valores de hash iguais venham de objetos iguais, por quê? Porque em alguns casos dois objetos diferentes podem passar o mesmo resultado da função hash (veja colisões de hash).
Colisão de hash Colisão de hash
É quando temos objetos diferentes com dados diferentes, mas dando o mesmo resultado de valor hash. Quando temos objetos e dados diferentes, mas obtemos o mesmo valor de hash.Pode ser porque a função hash é uma função hash simples, mas também é possível mesmo com funções hash mais complexas. Na maioria dos casos, tudo bem, podemos gerenciar a colisão de hash. Provavelmente isso ocorre porque a função hash é uma função hash simples, mas funções hash ainda mais complexas são possíveis. Na maioria dos casos, tudo bem e podemos gerenciar colisões de hash.
##Tabelas hash Tabela hash
A ideia de hashing foi fundamental para entender a estrutura de dados da tabela hash. A ideia de hash é a base para a compreensão da estrutura de dados da tabela hash.
It’s a typical data structure to implement an associative arrays; mapping keys to values.
实现关联数组是一种典型的数据结构;将键映射到值。
 Mapeando números (chaves) para caixas Mapeando números (chaves) para caixas
Mapeando números (chaves) para caixas Mapeando números (chaves) para caixas
Tabelas hash versus matrizes versus lista alinhada Tabelas hash versus matrizes versus listas
O grande benefício das tabelas hash sobre arrays e listas vinculadas é que elas são muito rápidas, tanto para verificar se um item existe ou encontrar um item específico em uma tabela hash, quanto para inserir e excluir itens. O maior benefício das tabelas hash em comparação com arrays e listas vinculadas é que elas são muito rápidas, tanto para ver se um item existe, quanto para encontrar um item específico na tabela hash e para inserir e excluir itens.
Como funcionam as tabelas hash? Como funcionam as tabelas hash?
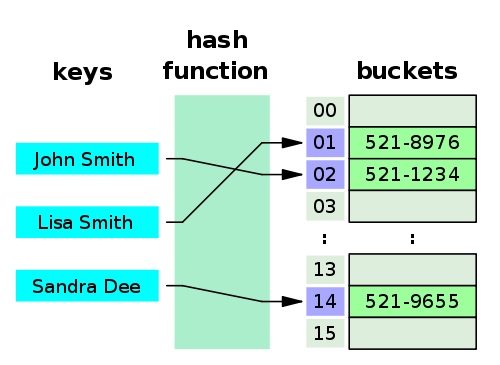 Uma pequena lista telefônica como uma tabela hash - Wikipedia Uma pequena lista telefônica como uma tabela hash - Wikipedia
Uma pequena lista telefônica como uma tabela hash - Wikipedia Uma pequena lista telefônica como uma tabela hash - Wikipedia
Quando uma tabela hash é criada, ela é internamente uma estrutura de dados muito baseada em array e geralmente pode ser criada com uma capacidade inicial. A tabela hash consiste em uma matriz de slots ou intervalos que contêm os valores. Quando uma tabela hash é criada, ela é na verdade uma estrutura de dados baseada em array que geralmente pode ser criada com uma capacidade inicial. Uma tabela hash consiste em uma matriz de slots ou buckets contendo valores.
Ao adicionar um par chave-valor, ele pegará nossa chave e a executará por meio da função hash, obtendo um valor hash específico (geralmente um número inteiro). Ao adicionar um par chave-valor, ele pega nossa chave e a executa por meio de uma função hash, resultando em um valor hash específico (geralmente um número inteiro).
Se esse valor de hash for grande, talvez seja necessário simplificá-lo em relação ao tamanho atual da tabela de hash. Se esse hash for grande, talvez seja necessário simplificá-lo com base no tamanho atual da tabela hash.
Em seguida, ele atribuirá o valor a um elemento da matriz com o índice igual ao valor inteiro hash retornado. Em seguida, ele atribuirá esse valor a um elemento da matriz com um índice igual ao valor inteiro com hash retornado.
// adding a key-value pair
hash_table.add(key, value)
// what happen behind the scene
index = hash(key)
index = index % array_size
array[index] = value
Acessar um valor dado uma chave segue a mesma ideia. Ele pegará essa chave, executará exatamente a mesma função hash e poderá ir diretamente para um local específico que contém o valor que procuramos. Acessar o valor de uma determinada chave segue a mesma ideia. Ele pega essa chave, executa-a exatamente pela mesma função hash e, em seguida, pode ir diretamente para um local específico que contém o valor que procuramos.
Não há pesquisa linear, nem pesquisa binária, nem percorrer uma lista. Simplesmente vamos direto ao elemento que precisamos. Sem pesquisas lineares, sem pesquisas binárias, sem listas de passagem. Obtemos diretamente o elemento que precisamos.
Gerenciando conflitos de gerenciamento de colisões
Podemos esperar que surja uma colisão de hash; quando obtemos o mesmo valor de hash para chaves diferentes. Mas, como administrar isso? Podemos esperar que ocorram colisões de hash; quando obtemos o mesmo valor de hash para chaves diferentes. Mas, como administrar isso?
Quando adicionamos um novo par de valores-chave e ocorre uma colisão, esse valor será colocado no mesmo local, mesmo que haja outro valor existente naquele local. Quando adicionamos um novo par de valores-chave e ocorre uma colisão, esse valor será colocado na mesma posição, mesmo que exista outro valor nessa posição.
Agora, as implementações de tabelas hash têm diferentes maneiras de lidar automaticamente com isso. Eles variam desde que cada local contenha uma coleção simples, como um array ou uma lista vinculada. Agora, as implementações de tabelas hash têm diferentes maneiras de lidar com isso automaticamente. Cada local contém uma coleção simples, como uma matriz ou lista vinculada.
Assim, ainda seríamos capazes de chegar a qualquer local muito rapidamente, mas assim que chegarmos ao local com vários valores, a tabela hash percorrerá essa lista interna para encontrar o que procuramos. Portanto, ainda podemos chegar a qualquer local muito rapidamente, mas quando chegamos a um local com vários valores, a tabela hash percorre essa lista interna para encontrar o que procuramos.
Cada nó na lista vinculada, por sua vez, conterá o valor associado a uma chave específica. Além disso, conterá essa chave ou uma referência a essa chave. Pois no caso de vários valores dentro do mesmo local, precisamos saber a qual chave esse valor pertence. Cada nó na lista vinculada, por sua vez, contém um valor associado a uma chave específica. Além disso, conterá a chave ou uma referência à chave. Porque para vários valores dentro da mesma posição, precisamos saber a qual chave esse valor pertence.
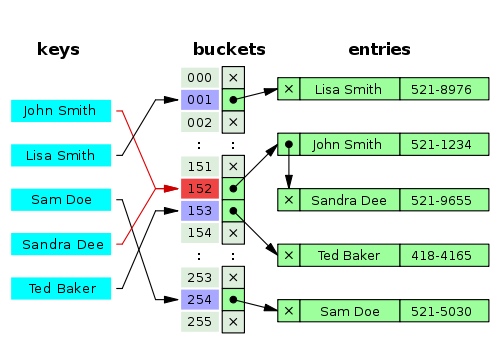 Colisão de hash resolvida por encadeamento separado — wikipedia Colisão de hash resolvida por encadeamento separado — Wikipedia
Colisão de hash resolvida por encadeamento separado — wikipedia Colisão de hash resolvida por encadeamento separado — Wikipedia
Isso é chamado de “Técnica de encadeamento separado” em tabelas hash. Agora, existem outras técnicas para gerenciar colisões dentro de tabelas hash, incluindo endereçamento aberto, hashing Cuckoo, hop-scotch e hashing Robin Hood. Esta é a “técnica de vinculação independente” em tabelas hash. Hoje, existem outras técnicas para gerenciar colisões em tabelas hash, incluindo endereçamento aberto, hashing cuco, amarelinha e hashing Robin Hood.
Escrevendo funções hash Escrevendo funções hash
Quando você deseja armazenar pares de valores-chave usando estrutura de dados de tabela hash, provavelmente a maioria dos objetos já possui função hash. O comportamento padrão geralmente retorna um número inteiro; calculado a partir do endereço de memória desse objeto. Quando você deseja usar uma estrutura de dados de tabela hash para armazenar pares de valores-chave, provavelmente a maioria dos objetos já possui uma função hash. O comportamento padrão geralmente é retornar um número inteiro; calculado a partir do endereço de memória do objeto.Se você substituir o comportamento de igualdade em sua classe, deverá substituir o comportamento de hash. Porque os códigos hash estão muito ligados à igualdade e, se você tiver dois objetos que considera iguais, eles deverão retornar o mesmo valor hash. Se você substituir o comportamento de igualdade em uma classe, deverá substituir o comportamento de hash. Como os códigos hash estão intimamente relacionados à igualdade, e se houver dois objetos que você considera iguais, eles deverão retornar o mesmo valor hash.
Novamente, se você alterar o que significa que seus objetos sejam iguais, você também deverá alterar o que significa fazer hash desses objetos. Da mesma forma, se você alterar o significado da igualdade dos objetos, também deverá alterar o significado do hash desses objetos.
Os objetos String já substituíram sua própria igualdade e comportamento de hash. Portanto, se você tiver dois objetos string separados, eles ainda contarão como iguais e retornarão o mesmo hash, se tiverem o mesmo valor, mesmo que sejam, na verdade, objetos string separados alocados em partes diferentes da memória. Os objetos String substituíram a igualdade e o comportamento de hashing próprios. Portanto, se você tiver dois objetos string separados, eles ainda serão iguais e retornarão o mesmo hash se tiverem o mesmo valor, mesmo que sejam, na verdade, objetos string separados alocados em diferentes partes da memória.
##Conjuntos definidos
Quando tudo o que você precisa é de um contêiner grande, você pode colocar vários itens nele, sem se importar com a sequência. Quando você só precisa de um contêiner grande, você pode colocar um monte de coisas nele e não precisa se preocupar com a ordem.
Não existe uma sequência específica como acontece com uma lista encadeada, ou uma pilha, ou uma fila. Não há pares de valores-chave como em uma tabela hash. Não há sequência específica, como lista vinculada, pilha ou fila. Não existem pares de valores-chave, assim como uma tabela hash.
It’s an unordered collection of items, with no repeated values.
它是一个无序的项目集合,没有重复的值。
Por não ordenado, quero dizer que não existe índice como um array. Não ordenado significa que não há índice como em um array.
 Uma sacola de comida Uma sacola de comida
Uma sacola de comida Uma sacola de comida
Definir implementação Definir implementação
Na verdade, os conjuntos usam a mesma ideia de estrutura de dados de tabelas hash na maioria das vezes. Mas, em vez de pares de valores-chave (hash de uma chave e armazenamento de seu valor), quando você está usando um conjunto, a chave também é considerada como o valor (ou o valor é atribuído a um valor fictício ou padrão). Na verdade, as coleções usam a mesma ideia de uma estrutura de dados de tabela hash na maioria dos casos. No entanto, diferentemente dos pares chave-valor (onde a chave é hash e seu valor é armazenado), ao trabalhar com coleções as chaves também são consideradas valores (ou os valores são atribuídos a valores fictícios ou padrão).
Portanto, para obter qualquer valor específico, ou qualquer objeto específico do conjunto, você precisa ter o próprio objeto. E a única razão para fazer isso é verificar sua existência. Isto é muitas vezes referido como “verificar a adesão”. Portanto, para obter qualquer valor específico na coleção, ou qualquer objeto específico, você precisa do próprio objeto. A única razão para fazer isso é testar se ele existe. Isso geralmente é chamado de “verificação de adesão”.
Os conjuntos podem ser implementados usando uma árvore de pesquisa binária com autoequilíbrio para conjuntos classificados ou uma tabela hash para conjuntos não classificados. Conjuntos classificados podem ser implementados usando árvores de pesquisa binárias com auto-equilíbrio, ou conjuntos não classificados podem ser implementados usando tabelas hash.
A vantagem dos conjuntos As vantagens dos conjuntos
Ao contrário de uma matriz, ou de valores em uma matriz associativa ou de uma lista vinculada, os conjuntos não permitem duplicatas. Você não pode adicionar o mesmo objeto, o mesmo valor duas vezes ao mesmo conjunto. Ao contrário dos valores em matrizes, matrizes associativas ou listas vinculadas, os conjuntos não permitem duplicatas. O mesmo objeto e o mesmo valor não podem ser adicionados duas vezes à mesma coleção.
Os conjuntos são projetados para uma pesquisa muito rápida, para podermos ver rapidamente se já temos um valor contido em uma coleção. As coleções são projetadas para pesquisas rápidas, para que você possa ver rapidamente se um valor já está contido na coleção.
Você também pode iterar todos os elementos de um conjunto, mas pode não ter nenhuma ordem garantida. Você também pode iterar todos os elementos de uma coleção e pode não ter nenhuma ordem garantida.
##Árvores A ideia de uma estrutura de dados em árvore é que temos uma coleção de nós, e os nós têm conexões, eles têm links entre si. O conceito de estrutura de dados em árvore é que temos um conjunto de nós, e esses nós têm conexões e há links entre eles.
Isso parece semelhante a listas vinculadas. Mas em uma lista vinculada, sempre vamos de um nó para um único nó seguinte específico. Enquanto estiver em uma árvore, cada nó pode estar vinculado a um, dois ou mais nós. Isso parece semelhante a uma lista vinculada. Mas em uma lista vinculada, sempre vamos de um nó para um próximo nó específico. Em uma árvore, cada nó pode estar ligado a um, dois ou mais nós.
It’s a collection of nodes, where each node might link to one, or two, or more nodes.
它是节点的集合,每个节点可能链接到一个、两个或多个节点。
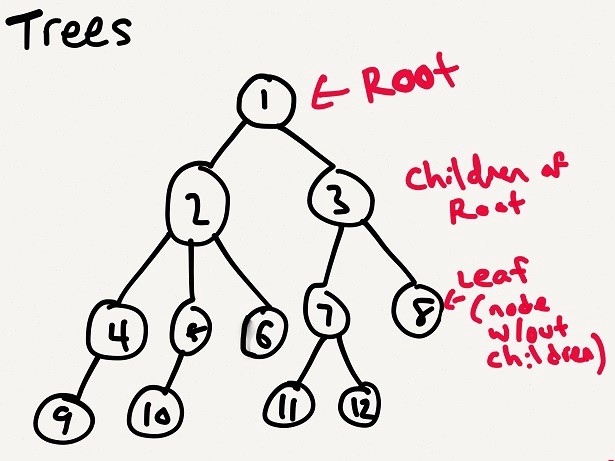 Uma árvore - richardkho.com
Uma árvore - richardkho.com
Terminologias de árvore Terminologia de árvore
Existem algumas terminologias que acompanham a árvore. Você pode encontrar mais sobre eles aqui. Eles são essenciais para entender e trabalhar com árvores. Existem alguns termos que acompanham esta árvore. Você pode encontrar mais informações sobre eles aqui. Eles são essenciais para compreender e estudar as árvores.
Árvores binárias Árvore binária
Uma árvore binária é apenas uma árvore com no máximo dois nós filhos para qualquer nó pai. As árvores binárias são frequentemente usadas para implementar uma estrutura maravilhosamente pesquisável chamada “Árvore de pesquisa binária” ou “BST”. Uma árvore binária é uma árvore com no máximo dois nós filhos para qualquer nó pai. As árvores binárias são frequentemente usadas para implementar uma estrutura pesquisável sofisticada chamada “árvore de pesquisa binária” ou “BST”.
##Árvores de pesquisa binária (BST) Árvore de pesquisa binária (BST)
It’s a specific type of binary tree, where the left child node is less than its parent, and a right child node is greater than its parent.
它是一种特定类型的二叉树,其中左子节点小于其父节点,而右子节点大于其父节点。
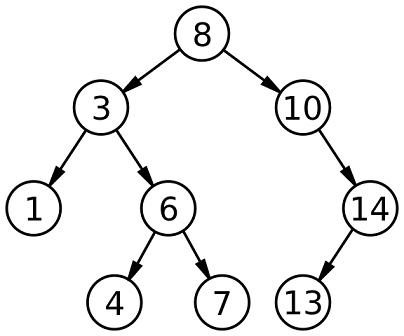 Uma árvore de pesquisa binária (BST) - Wikipedia Uma árvore de pesquisa binária (BST) - Wikipedia
Uma árvore de pesquisa binária (BST) - Wikipedia Uma árvore de pesquisa binária (BST) - Wikipedia
Como funcionam as árvores de pesquisa binária? Como funcionam as árvores de pesquisa binária?
A regra é que o nó filho esquerdo deve ser menor que seus pais, e um nó filho direito deve ser maior que seus pais, e essa regra segue todo o caminho na árvore. A regra é que o nó filho esquerdo deve ser menor que seu nó pai, e o nó filho direito deve ser maior que seu nó pai, e esta regra continua descendo na árvore.E à medida que inserimos novos nós com valores, a regra sempre será seguida para garantir que a árvore permaneça ordenada. Quando inserimos um novo nó com um valor, sempre serão seguidas regras para garantir que a árvore permaneça ordenada.
Portanto, é uma estrutura de dados que permanece ordenada naturalmente e às vezes é chamada de “Árvore Classificada” ou “Árvore Ordenada”. Portanto, é uma estrutura de dados que mantém a ordem naturalmente e às vezes é chamada de “árvore classificada” ou “árvore ordenada”.
Armazenando nós como pares de valores-chave Armazenando nós como pares de valores-chave
Árvores de pesquisa binária são frequentemente usadas para armazenar pares de valores-chave, ou seja, os nós consistem em uma chave e um valor associado. E é a chave que seria usada para classificar os nós de acordo em uma árvore de pesquisa binária. As árvores de pesquisa binária são normalmente usadas para armazenar pares de valores-chave, ou seja, os nós consistem em uma chave e um valor associado. Esta é a chave para ordenar os nós em uma árvore de pesquisa binária.
Duplicatas
Você não pode ter chaves duplicadas, assim como não pode ter chaves duplicadas em uma tabela hash ou mesmo em um array. Não pode haver chaves duplicadas, assim como não pode haver chaves duplicadas em uma tabela hash ou mesmo em um array.
Adicionando e acessando nós Adicionando e acessando nós
Adicionar e acessar nós segue a mesma regra mencionada acima. Se o nó atual for menor que, vá para a direita; se for maior, vá para a esquerda. Adicionar e acessar nós segue as mesmas regras acima. Se o nó atual for menor, vá para a direita, se for maior, vá para a esquerda.
Recuperar nós em ordem Recuperar nós em ordem
O outro benefício é que as árvores de pesquisa binária permanecem classificadas. Portanto, se recuperarmos os itens da esquerda para a direita, de baixo para cima, colocaremos todos em ordem. Outro benefício é que as árvores de busca binária mantêm a ordem. Portanto, se recuperarmos os itens da esquerda para a direita e de baixo para cima, iremos colocá-los em ordem.
Árvore desequilibrada Árvore desequilibrada
É quando a árvore possui mais níveis de nós no lado direito do que no esquerdo (ou vice-versa). Quando há mais nós no lado direito da árvore do que no esquerdo (e vice-versa).
Embora seja incomum que esse tipo de coisa aconteça, nem sempre podemos garantir que a forma como os dados são adicionados nos permitirá construir uma árvore com uma estrutura perfeitamente simétrica em toda a sua extensão. Embora isso raramente aconteça, nem sempre podemos garantir que adicionamos dados de uma forma que nos permita construir uma árvore com uma estrutura completamente simétrica.
Neste caso dizemos que a nossa árvore está desequilibrada; Existem mais níveis de um lado do que do outro. E teríamos que realizar mais verificações para encontrar, inserir ou excluir quaisquer valores no lado direito do que faríamos no lado esquerdo (ou vice-versa). Neste caso dizemos que a árvore está desequilibrada; um lado tem mais níveis de energia que o outro. Precisamos realizar mais verificações para encontrar, inserir ou excluir qualquer valor à direita do que à esquerda (ou vice-versa).
Implementações de árvore de pesquisa binária Implementação de árvore de pesquisa binária
Estamos falando da ideia abstrata de uma estrutura de dados em árvore de pesquisa binária. Porém, existem várias implementações dessa ideia de árvore de pesquisa binária que são árvores de pesquisa binária com autoequilíbrio. O que estamos discutindo é a ideia abstrata de uma estrutura de dados em árvore de pesquisa binária. No entanto, existem várias implementações dessa ideia de árvore de pesquisa binária que são árvores de pesquisa binária com autoequilíbrio.
A ideia importante ao equilibrar uma árvore de pesquisa binária é que o número de níveis seja aproximadamente igual entre si. Não temos três níveis à esquerda e vinte à direita. A ideia importante no balanceamento de uma árvore de busca binária é que o número de níveis seja aproximadamente igual. Não há três andares à esquerda nem vinte andares à direita.
Exemplos de árvores de autoequilíbrio podem ser: Red-Black, AVL ou Adelson-Velskii e Landis’, Splay, árvores de bode expiatório e muito mais. Exemplos de árvores com autoequilíbrio podem ser: árvores rubro-negras, AVL ou Adelson-Velskii e Landis’, árvores Splay, árvores de bode expiatório, etc.
Árvore de pesquisa binária versus tabela hash Árvore de pesquisa binária versus tabela hash
Ambos são rápidos para inserção, rápidos para exclusão, rápidos para acessar qualquer elemento mesmo em tamanhos grandes. Mas, como as árvores de pesquisa binária permanecem ordenadas, elas nos permitem colocar todos os itens da árvore em ordem, onde a tabela hash não garante uma ordem específica. Ambos os métodos fornecem inserção rápida, exclusão rápida e acesso rápido a qualquer elemento, mesmo os grandes. No entanto, como as árvores de busca binária mantêm a ordem, elas nos permitem retirar todos os itens da árvore em ordem, enquanto as tabelas hash não podem garantir uma ordem específica.
Montes, montes
Heaps geralmente são implementados usando a ideia de uma árvore binária, não uma árvore binária de pesquisa, mas ainda assim uma árvore binária. Eles são uma forma de implementar outros tipos de dados abstratos, como a fila de prioridade. O heap geralmente é implementado usando a ideia de uma árvore binária, não uma árvore binária de pesquisa, mas uma árvore binária. Eles são uma forma de implementar outros tipos de dados abstratos, como filas de prioridade.
It’s a specific type of binary tree, where we add nodes from top to bottom, left to right, and child nodes must be less (or greater) than or equal their parents.
这是一种特定类型的二叉树,我们从上到下、从左到右添加节点,子节点必须小于(或大于)或等于它们的父节点。
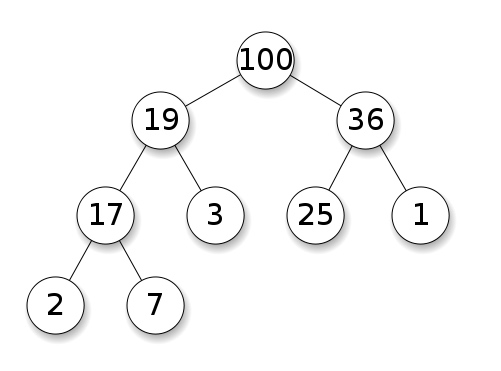 Max Heap - Wikipedia O maior heap - Wikipedia
Max Heap - Wikipedia O maior heap - Wikipedia
Portanto, preenchemos completamente qualquer nível antes de passar para o próximo. Portanto, não precisamos nos preocupar com o desequilíbrio da árvore, como acontece com uma árvore de pesquisa binária. Portanto, preencheremos completamente qualquer nível antes de passar para o próximo nível. Portanto, não precisamos nos preocupar com a possibilidade de a árvore ficar desequilibrada como uma árvore de pesquisa binária.
Pilha mínima versus máxima
Um heap mínimo afirma que qualquer nó filho deve ser maior (ou igual) ao seu nó pai, enquanto um heap máximo afirma que qualquer nó filho deve ser menor que (ou igual) ao seu nó pai. No entanto, não nos importamos se um nó é menor ou maior que seu irmão. O heap mínimo afirma que qualquer nó filho deve ser maior que (ou igual a) seu nó pai, enquanto o heap máximo afirma que qualquer nó filho deve ser menor que (ou igual a) seu nó pai. No entanto, não nos importamos se um nó é menor ou maior que seus irmãos.
Como funcionam os montes? Como funciona a pilha?
Então, no caso de Min Heap: Então, para um min-heap:1. Continuamos adicionando elementos de cima para baixo, da esquerda para a direita 2. Em seguida, compare com o nó pai; É menor que seu pai? Em seguida, compare com o nó pai; É menor que seu pai? 3. Em caso afirmativo, troque o nó com seu pai, 4. Continue executando as etapas 2 a 3 até que o nó seja maior que seu pai (ou se torne o nó raiz). como mostrado. Continue executando as etapas 2 a 3 até que o nó seja maior que seu pai (ou se torne o nó raiz).
Essa pequena troca de nós é como um heap se mantém organizado. Essa pequena troca de nós é como o heap se mantém organizado.
O heap não está totalmente classificado O heap não está completamente classificado
Ao contrário de uma árvore de pesquisa binária, que permanece classificada e onde podemos facilmente percorrer a árvore e recuperar tudo em ordem. Ao contrário das árvores de busca binária, que mantêm a ordem, podemos facilmente percorrer a árvore e recuperar tudo em ordem.
Porque se você notar que em qualquer nível específico após a raiz, os valores não precisam estar em nenhuma ordem específica, desde que sejam todos maiores (ou menores) que seus pais. Porque se você notar, em qualquer nível específico após a raiz, os valores não precisam aparecer em nenhuma ordem específica, desde que sejam todos maiores (ou menores) que seus pais.
Um dos benefícios disso é que um heap não precisa se reorganizar tanto quanto seria necessário com uma árvore de pesquisa binária. Um benefício disso é que o heap não precisa se reorganizar tanto quanto acontece com uma árvore de pesquisa binária.
A única coisa de que podemos ter certeza é que o nó pai sempre será menor ou maior que seus nós filhos e, portanto, o valor mínimo ou máximo estará sempre no topo. Uma coisa de que podemos ter certeza é que um nó pai é sempre menor ou maior que seus filhos, portanto o valor mínimo ou máximo está sempre no topo.
E, portanto, os heaps são mais úteis para a ideia de uma fila prioritária. Portanto, o heap é mais útil para o conceito de filas prioritárias.
##Gráficos Gráficos
As limitações de uma árvore não existem mais aqui. Um nó pode se vincular a vários outros nós, sem sequência específica, sem nó raiz. As limitações das árvores não existem mais. Um nó pode ser vinculado a vários outros nós sem uma ordem específica e sem um nó raiz.
É uma coleção de nós, onde um nó pode se vincular a vários outros nós, sem sequência específica, sem nó raiz. É uma coleção de nós onde um nó pode ser vinculado a vários outros nós, sem nenhuma sequência específica e sem um nó raiz.
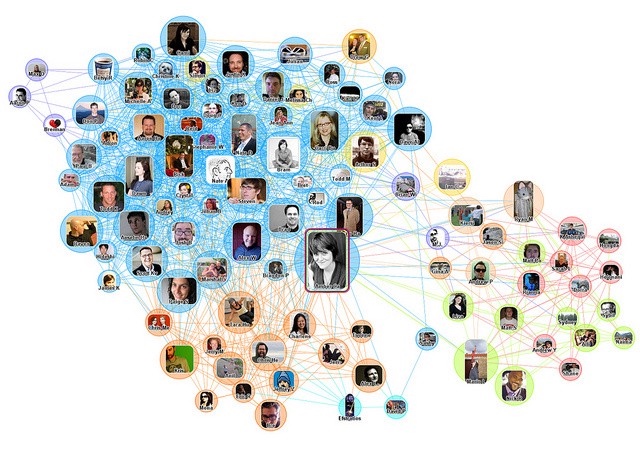 Um gráfico de uma rede social
Diagrama de rede social
Um gráfico de uma rede social
Diagrama de rede social
Teoria dos Grafos em Matemática Teoria dos Grafos em Matemática
Porque os gráficos na ciência da computação estão intimamente ligados à teoria dos grafos na matemática. É comum ouvir termos matemáticos usados. Portanto, na teoria dos grafos, chamamos os nós de “vértices” e as ligações entre eles são chamadas de “arestas”. Porque os gráficos na ciência da computação e a teoria gráfica na matemática estão intimamente ligados. É muito comum usar termos matemáticos. Portanto, na teoria dos grafos, chamamos os nós de “vértices” e as ligações entre eles de “arestas”.
Uso de gráficos Uso de gráfico
Poderíamos usar um gráfico para modelar uma rede social com cada nó sendo uma pessoa. Ou modelando as distâncias entre cidades. Poderíamos modelar uma rede Ethernet em um escritório, ou em um prédio inteiro, ou em uma cidade. Podemos usar um gráfico para modelar uma rede social com nós para cada pessoa. Alternativamente, modele a distância entre cidades. Podemos modelar uma rede Ethernet em um escritório, um prédio inteiro ou uma cidade.
Gráficos diretos e indiretos Gráficos diretos e indiretos
Também podemos dizer se essas arestas devem ter uma direção ou não. Também podemos dizer se essas arestas devem ter uma direção.
Em algumas situações, faz sentido que qualquer aresta, qualquer conexão entre dois vértices, seja unidirecional; Portanto, o nó A está conectado ao nó B, enquanto o inverso não é verdadeiro; o nó B NÃO está conectado ao nó A. Em alguns casos, qualquer aresta, qualquer conexão entre dois vértices, é unidirecional; portanto, o nó A está conectado ao nó B, mas não vice-versa; o nó B não está conectado ao nó A.
Em outras situações, você pode querer seguir aquela borda, aquele link, em qualquer direção; Portanto, o nó A está conectado ao nó B e também o nó B está conectado ao nó A. Em outros casos, você pode querer seguir essa borda, esse link, em qualquer direção; o nó A se conecta ao nó B e o nó B se conecta ao nó A.
Gráficos ponderados Gráfico ponderado
Você também pode dar um peso a cada aresta; associando um número, com cada uma das arestas. Você também pode dar um peso a cada aresta; associe um número a cada aresta.
Você poderia fazer isso para representar, digamos, as distâncias entre cidades, se estivesse tentando calcular a rota mais curta entre vários locais. Ou você pode usar um peso para indicar quais arestas têm prioridade sobre outras arestas. Você poderia representar, digamos, a distância entre cidades se quisesse calcular a rota mais curta entre vários locais. Alternativamente, você pode usar pesos para indicar quais arestas são preferidas em relação a outras.
##Tipos de dados abstratos (ADTs) tipos de dados abstratos (adt)
Antes de mergulhar nos tipos de dados abstratos, o que são e a diferença entre eles e outros conceitos. Vamos definir o que significa um tipo de dados. Antes de nos aprofundarmos nos tipos de dados abstratos, vamos entender o que são e como diferem de outros conceitos. Vamos definir o que significam os tipos de dados.
Tipo de dados Tipo de dados
O tipo de dados de uma variável determina os valores que ela pode conter, além das operações que podem ser realizadas nela.
Os tipos de dados consistem em: tipos de dados primitivos, complexos ou compostos e abstratos. Os tipos de dados incluem: tipos de dados básicos, tipos de dados complexos ou tipos de dados compostos e tipos de dados abstratos.
Um tipo de dados abstratos (ADT) Tipo de dados abstratos (ADT)É um tipo de dados, assim como os tipos de dados primitivos inteiros e booleanos. Um ADT consiste não apenas em operações, mas também em valores dos dados subjacentes e em restrições às operações.
É um tipo de dados, assim como os tipos de dados primitivos inteiros e booleanos. ADT contém não apenas operações, mas também os valores dos dados subjacentes e restrições às operações.
Uma restrição para uma pilha seria que cada pop sempre retornasse o item enviado mais recentemente que ainda não foi pop-up. A restrição da pilha é que cada pop sempre retorna o item enviado mais recentemente que ainda não foi pop-up.
A implementação real de um ADT é abstraída e não precisamos nos preocupar com isso. Portanto, como uma pilha é realmente implementada não é tão importante. Uma pilha pode ser e geralmente é implementada nos bastidores usando um array dinâmico, mas em vez disso pode ser implementada com uma lista vinculada. Realmente não importa. A implementação real do ADT é abstrata e não precisamos nos preocupar. Portanto, não importa como a pilha é implementada. As pilhas podem e geralmente são implementadas usando matrizes dinâmicas subjacentes, mas também podem ser implementadas usando listas vinculadas. Realmente não importa.
Listas, pilhas, filas e muito mais são tipos de dados abstratos. Listas, pilhas, filas, etc. são todos tipos de dados abstratos.
Um tipo de dados abstrato e estrutura de dados Tipo de dados abstrato e estrutura de dados
ADT não é uma alternativa a uma estrutura de dados, são conceitos diferentes. ADT não substitui estruturas de dados, são conceitos diferentes.
Quando dizemos estrutura de dados da pilha, nos referimos a como as pilhas são implementadas e organizadas na memória. Mas, quando dizemos pilha ADT, nos referimos ao tipo de dados da pilha que possui um conjunto de operações definidas, as restrições das operações e os valores possíveis. Quando falamos sobre estrutura de dados da pilha, estamos nos referindo a como a pilha é implementada e organizada na memória. No entanto, quando dizemos stack ADT, queremos dizer um tipo de dados de pilha que possui um conjunto definido de operações, restrições de operação e valores possíveis.
Não nos importamos com a implementação subjacente, assim como quando usamos inteiros, somos abstraídos de como os inteiros são representados na memória, estamos interessados apenas nas operações (somar, subtrair,…) e nos valores possíveis (…, −2, −1, 0, 1, 2,…). Não nos importamos com a implementação subjacente, pois ao trabalhar com inteiros, rompemos com a representação de inteiros na memória, estamos interessados apenas nas operações (adição, subtração, …) e nos valores possíveis (…−2−1,0,1,2,…).
As estruturas de dados podem implementar um ou mais tipos de dados abstratos (ADT) específicos, que especificam as operações que podem ser executadas em uma estrutura de dados. Uma estrutura de dados pode implementar um ou mais tipos de dados abstratos (ADTs) específicos, que especificam as operações que podem ser executadas na estrutura de dados.
Um tipo de dados abstrato NÃO é uma classe abstrata Um tipo de dados abstrato NÃO é uma classe abstrata
Ambos não têm nada a ver um com o outro. Uma classe abstrata define apenas as operações, às vezes com comentários que descrevem as restrições, deixando a implementação real para as classes herdeiras. Nenhum dos dois tem nada a ver com o outro. As classes abstratas apenas definem operações, às vezes com anotações que descrevem restrições, deixando a implementação real para as classes herdadas.
Embora os ADTs sejam frequentemente implementados como interfaces (classes abstratas), como em Java. Por exemplo, a interface List em Java define as operações do List ADT, enquanto as classes herdadas definem a implementação real (estrutura de dados). Embora os anúncios geralmente sejam implementados como interfaces (classes abstratas), como em Java. Por exemplo, a interface List em Java define as operações do List ADT, enquanto as classes herdadas definem a implementação real (estrutura de dados).
Mas nem sempre é esse o caso. Por exemplo, Java tem uma classe de pilha. É uma classe concreta regular, mas uma pilha também é um tipo de dados abstrato, ou seja, representa a ideia de ter uma estrutura de dados do tipo último a entrar, primeiro a sair. Portanto, stack é uma classe concreta real e também um tipo de dados abstrato. Mas nem sempre é esse o caso. Por exemplo, Java possui uma classe de pilha, que é uma classe concreta regular, mas a pilha também é um tipo de dados abstrato, ou seja, representa uma estrutura de dados do tipo último a entrar, primeiro a sair. Stack é uma classe concreta e um tipo de dados abstrato.
Um tipo de dados abstrato é um conceito teórico Um tipo de dados abstrato é um conceito teórico
Um tipo de dados abstrato (ADT) é um conceito teórico irrelevante para palavras-chave de programação. O tipo de dados abstrato (ADT) é um conceito teórico que não tem nada a ver com palavras-chave de programação.
Portanto, se tivermos uma pilha, teremos uma estrutura de dados último a entrar, primeiro a sair, que podemos enviar, exibir e espiar. Isso é o que esperamos que uma pilha seja capaz de fazer. Quer uma pilha seja implementada como uma classe concreta ou qualquer outra coisa, ela ainda tem a ideia de uma estrutura de dados último a entrar, primeiro a sair. Portanto, se tivermos uma pilha, teremos uma estrutura de dados LIFO que podemos enviar, exibir e espiar. Isso é o que esperamos que a pilha faça. Independentemente de a pilha ser implementada como uma classe concreta ou outra coisa, ela ainda possui o conceito de uma estrutura de dados do tipo último a entrar, primeiro a sair.
##Conclusão Conclusão
Decidindo sobre a estrutura de dados Determinando a estrutura de dados
Existem algumas perguntas importantes que você precisa fazer antes de decidir sobre a estrutura de dados Antes de decidir sobre uma estrutura de dados, você precisa fazer algumas perguntas importantes
*Quantos dados você tem? Quantos dados você tem?
- Com que frequência isso muda? Com que frequência isso muda?
- Você precisa classificá-lo, precisa pesquisá-lo? Mais rápido para acessar, inserir ou excluir? Mais rápido para acessar, inserir ou excluir?
Se houver algum lugar onde você tenha apenas quantidades triviais de dados, isso não fará muita diferença. A menos, é claro, que essas quantidades de dados mudem com muita frequência ou que você tenha grandes quantidades de dados. Se houver apenas uma pequena quantidade de dados em algum lugar, não importa. A menos, é claro, que esses volumes de dados mudem com muita frequência ou que você tenha muitos dados.### Estruturas de dados imutáveis Estruturas de dados imutáveis Agora, um princípio geral de que estruturas de dados imutáveis ou de tamanho fixo tendem a ser mais rápidas e menores em memória do que as mutáveis. Agora, um princípio geral é que estruturas de dados imutáveis ou de tamanho fixo tendem a ser mais rápidas e menores em memória do que estruturas mutáveis.
Por que devemos restringir os recursos dos arrays? A razão é que quanto mais restrições você tiver (como tamanho fixo, tipo de dados específico,…), mais rápida e menor será a sua estrutura de dados. Por que limitar as características dos arrays? A razão é que quanto mais restrições (como tamanho fixo, tipo de dados específico…), mais rápida e menor será a estrutura de dados.
A armadilha de ter uma estrutura de dados com muitos recursos (não restritos) é que o compilador não consegue alocar a quantidade ideal de espaço, portanto, deve introduzir sobrecarga para suportar a flexibilidade da estrutura de dados (como diferentes tipos de dados,…). A desvantagem das estruturas de dados com muitos recursos (irrestritos) é que o compilador não pode alocar uma quantidade ideal de espaço e, portanto, deve introduzir sobrecarga para suportar a flexibilidade da estrutura de dados (como diferentes tipos de dados, …).
Melhore o desempenho do seu código Melhore o desempenho do código
Se você estiver analisando o código existente para ver o que precisa ser melhorado, veja o que contém mais dados. Não há melhor maneira de realmente aproveitar ao máximo essas estruturas de dados do que observar algumas das melhorias de desempenho que você pode obter, simplesmente mudando de uma estrutura para outra. Se você estiver analisando o código existente para ver onde precisa de melhorias, observe onde a maioria dos dados está sendo salva. Quando você percebe que pode obter algumas melhorias de desempenho simplesmente mudando de uma estrutura para outra, não há melhor maneira de realmente aproveitar ao máximo essas estruturas de dados.
Diferenças em idiomas Diferenças em idiomas
Os algoritmos usados com cada estrutura de dados diferem de uma linguagem para outra, e a implementação real da estrutura de dados difere de uma linguagem para outra. Portanto, vale a pena examinar atentamente a documentação do seu idioma. Os algoritmos usados por cada estrutura de dados variam de idioma para idioma, e a implementação real da estrutura de dados varia de idioma para idioma. Portanto, é necessário revisar cuidadosamente a documentação do seu idioma.
What to read next
Want more posts about Algorithms?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Algorithms?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home