Estructuras de datos 1: profundización en las estructuras de datos
Estructuras de datos — Profundizando en las estructuras de datos (Parte 1)
Estructuras de datos: profundizar en las estructuras de datos (Parte 1) Estructuras de datos: profundizar en las estructuras de datos (Parte 1)
Fuente del artículo: https://medium.com/omarelgabrys-blog/diving-into-data-structures-6bc71b2e8f92
[TOC]
Cuando tenemos un problema de programación, nos sumergimos en el algoritmo, ignorando la estructura de datos subyacente. Y lo que es peor, creemos que usar otra estructura de datos no hará mucha diferencia, aunque podríamos mejorar enormemente el rendimiento de nuestro código eligiendo una estructura de datos alternativa. Cuando nos encontramos con un problema de programación, profundizamos en los algoritmos ignorando las estructuras de datos subyacentes. Para empeorar las cosas, no creemos que usar otra estructura de datos haga una gran diferencia, aunque podríamos mejorar en gran medida el rendimiento de nuestro código eligiendo otra estructura de datos.
¿Qué es una estructura de datos? ¿Qué es una estructura de datos?
No comienza sin preguntar: ¿Qué diablos es la estructura de datos? No comienza preguntando: ¿Qué diablos es la estructura de datos?
Es una disposición intencional de una colección de datos que hemos creado. es una disposición intencional de la recopilación de datos que construimos.
Disposición intencional Disposición deliberada
El acuerdo intencional significa el acuerdo realizado intencionalmente para imponer, para hacer cumplir, algún tipo de organización sistemática de los datos. La disposición intencional se refiere a una disposición intencionada destinada a alguna organización sistemática de datos. La disposición deliberada se refiere a la disposición deliberada de datos en alguna organización sistemática. La disposición intencional se refiere a una disposición intencional que impone una cierta organización sistemática de datos.
Debido a que es útil, nos hace la vida más fácil y es fácil de administrar cuando mantiene junta la información relacionada. Porque es útil, nos hace la vida más fácil y es fácil de gestionar cuando reúnes información relevante.
Estructuras de datos en nuestra vida Estructuras de datos en nuestra vida
Necesitamos estructuras de datos en nuestros programas porque pensamos así como seres humanos. En nuestros programas, necesitamos estructuras de datos porque así es como pensamos los humanos.
Una receta es una estructura de datos real, como lo es una lista de compras, una guía telefónica, un diccionario, etc. Todos tienen una estructura, tienen un formato. Una receta es una estructura de datos real, como una lista de compras, una guía telefónica, un diccionario, etc. Todos tienen una estructura, todos tienen un formato.
Estructura de datos y programación orientada a objetos Estructura de datos y programación orientada a objetos
Ahora bien, si eres un programador orientado a objetos, quizás estés pensando: Bueno, ¿no es esto lo que hacemos con las clases y los objetos? Si eres un programador orientado a objetos, quizás estés pensando, ¿no es esto lo que hacemos con las clases y los objetos?
Quiero decir, definimos estos objetos del mundo real en un programa porque pensamos de esta manera como seres humanos, o al menos se supone que debemos hacerlo. Quiero decir, definimos estos objetos del mundo real en un programa porque pensamos como humanos, o al menos se supone que debemos pensar de esa manera.
Y sí, absolutamente. Los objetos son un tipo de estructura de datos, y no el único. Sí, claro. Un objeto es una estructura de datos, no la única.
Cinco comportamientos fundamentales Cinco comportamientos fundamentales
Cómo acceder, insertar, eliminar, buscar y ordenar. Estas son las operaciones que probablemente realizarás. Cómo acceder, insertar, eliminar, buscar y ordenar. Estas son las acciones que es más probable que realices.
No todas las estructuras de datos tienen los cinco comportamientos fundamentales. No todas las estructuras de datos tienen estos cinco comportamientos básicos.
Por ejemplo, muchas estructuras de datos no admiten ningún tipo de comportamiento de búsqueda. Es solo una gran colección, un gran contenedor de cosas, y si necesita encontrar algo, simplemente revíselo todo usted mismo. Y muchos no ofrecen ningún tipo de comportamiento de clasificación. Otros se clasifican de forma natural. Por ejemplo, muchas estructuras de datos no admiten ningún tipo de comportamiento de búsqueda, es solo una gran colección, un gran contenedor de algo, y si necesita encontrar algo, solo tiene que iterarlo usted mismo. Y muchos no ofrecen ningún comportamiento de clasificación. Otro orden natural.
Cada estructura de datos tiene su propia forma diferente o un algoritmo diferente para ordenar, insertar, encontrar,…etc. ¿Por qué? Porque, debido a la naturaleza de la estructura de datos, hay algoritmos que se usan con una estructura de datos específica, donde algunos otros no se pueden usar. Cada estructura de datos tiene su propia forma diferente o diferentes algoritmos para ordenar, insertar, buscar, etc. ¿Por qué? Porque, debido a la naturaleza de las estructuras de datos, existen algunos algoritmos que funcionan con una estructura de datos específica y otros no se pueden utilizar.
Cuanto más eficiente y adecuado sea el algoritmo, más optimizada tendrá la estructura de datos. El desarrollador puede incorporar o implementar estos algoritmos para administrar y ejecutar estas estructuras de datos. Cuanto más eficiente y aplicable sea el algoritmo, más estructuras de datos optimizadas se podrán obtener. Los desarrolladores pueden incorporar o implementar estos algoritmos para administrar y ejecutar estas estructuras de datos.
Lea siempre la documentación del lenguaje y verifique el rendimiento de los algoritmos utilizados con la estructura de datos subyacente. Se pueden utilizar diferentes algoritmos según los datos (tamaño, tipo,…) que tenga. Lea siempre la documentación del lenguaje y verifique el rendimiento de los algoritmos utilizados con las estructuras de datos subyacentes. Se pueden utilizar diferentes algoritmos en función de los datos (tamaño de datos, tipo,…).
Matrices unidimensionales Matriz unidimensional
La matriz es la estructura de datos más fundamental y más utilizada en todos los lenguajes de programación. El soporte para matrices unidimensionales generalmente está integrado directamente en el propio lenguaje central. Las matrices son la estructura de datos más básica y comúnmente utilizada en todos los lenguajes de programación. El soporte para matrices unidimensionales generalmente está integrado directamente en el lenguaje principal.
Una matriz es una colección ordenada de elementos, donde cada elemento dentro de la matriz tiene un índice. Una matriz es una colección ordenada de elementos y cada elemento de la matriz tiene un índice.
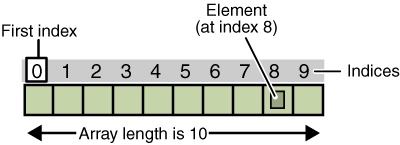
Índices Índice
Los índices están en orden, son índices de base cero en la mayoría de los idiomas, pero ese no es el caso con otros pocos idiomas. Los índices son secuenciales, en la mayoría de los idiomas son índices de base cero, pero en algunos otros idiomas este no es el caso.
Tamaño tamañoLas matrices más simples son de tamaño fijo, también llamadas inmutables, es decir, matrices inmutables. Se pueden crear inicialmente en cualquier tamaño. Pero una vez creada la matriz, no se pueden agregar ni eliminar elementos.
La matriz más simple es de tamaño fijo, también conocida como matriz inmutable, es decir, una matriz que no se puede cambiar. Inicialmente se pueden crear en cualquier tamaño. Pero una vez creada la matriz, no se pueden agregar ni eliminar elementos de ella.
A veces, la capacidad de agregar o eliminar elementos dinámicamente mientras el programa se ejecuta está disponible en la matriz estándar de un idioma y, a veces, tiene varios tipos de matrices diferentes, dependiendo de si necesita una matriz fija o de tamaño variable. A veces, la capacidad de agregar o eliminar elementos dinámicamente mientras el programa se está ejecutando está disponible en las matrices estándar del lenguaje y, a veces, puede usar varios tipos de matrices diferentes, dependiendo de si necesita una matriz fija o una matriz de tamaño variable.
Tipo de datos Tipo de datos
Las matrices simples suelen estar restringidas a un tipo específico de datos. Es una serie de números enteros o una serie de valores booleanos. Pero algunos lenguajes te permiten crear matrices de objetos genéricos, lo que significa que puedes colocar diferentes tipos de datos. Las matrices simples suelen estar limitadas a tipos de datos específicos. Es una matriz de números enteros o una matriz de valores booleanos. Pero algunos lenguajes permiten crear matrices de objetos genéricos, lo que significa que se pueden colocar diferentes tipos de datos.
array = [123, true, "string", [1,2,3], object]
Matrices multidimensionales Matriz multidimensional
Llevando la matriz unidimensional un paso más allá, podemos tener matrices con dos dimensiones. Llevando la matriz unidimensional más allá, podemos obtener una matriz bidimensional.
Es básicamente una matriz de matrices, donde cada elemento de esta matriz contiene otra matriz. Es esencialmente una matriz de matrices, y cada elemento de la matriz contiene otra matriz.
Por lo tanto, no se accede a ningún elemento de la matriz con un solo índice, sino que necesitamos dos números para llegar a él. A veces se la denomina matriz o tabla porque, efectivamente, se trata de filas y columnas de información. Por lo tanto, no se puede acceder a ningún elemento de la matriz con un solo índice, sino que se requieren dos números para acceder a él. A veces se le llama matriz o tabla porque en realidad son filas y columnas de información.
Podemos llevar la matriz bidimensional a matrices tridimensionales e incluso más. Podemos desarrollar aún más matrices bidimensionales en matrices tridimensionales, y aún más.
Matrices irregulares Matriz irregular
Cuando tenemos una matriz multidimensional, donde cada fila, cada elemento debe tener una cantidad diferente de elementos. Es donde entran en juego los arreglos irregulares. Cuando tenemos una matriz multidimensional, cada fila y cada elemento debe tener una cantidad diferente de elementos. Aquí es donde entran en juego las matrices irregulares.
Es una matriz multidimensional donde cada elemento puede tener diferentes tamaños. es una matriz multidimensional, cada entrada puede ser de diferentes tamaños.
 Las filas tienen diferente número de piedras.
filas con diferentes números de piedras
Las filas tienen diferente número de piedras.
filas con diferentes números de piedras
Cuándo usar matrices dentadas Cuándo usar matrices dentadas
Si tiene una matriz multidimensional que registra el número de ventas todos los días. El primer índice es para el mes, mientras que el segundo es para el día. Si tiene una matriz multidimensional que registra las ventas diarias. El primer índice es para el mes actual y el segundo índice es para el día actual.
sales = [[124,153,135, …], [135,545,342,678,], …]
Puedes notar que enero tiene 31 días, mientras que febrero tiene 29, y así sucesivamente. Por lo tanto, no siempre es deseable dejar los elementos irrelevantes vacíos o establecerlos en 0 o -99 o algún otro valor. Pero no debes tener elementos que representen imposibilidades. Como en febrero, donde los días 30 y 31 no existen. Puedes notar que enero tiene 31 días, mientras que febrero tiene 29, y así sucesivamente. Por lo tanto, no siempre es aconsejable mantener vacíos los elementos irrelevantes o establecerlos en 0 o -99 u otros valores. Sin embargo, no debes contar con elementos que representen lo imposible. Por ejemplo, en febrero no existen los días 30 y 31.
Entonces, usando Jagged Arrays, podemos obtener el promedio de ventas en un mes tomando todas las ventas de ese mes, sumándolas todas y dividiéndolas por la cantidad de días de ese mes, sin tener que agregar lógica para calcular los días que deberíamos ignorar. Entonces, usando una matriz irregular, podemos obtener las ventas promedio de un mes tomando todas las ventas del mes, sumándolas y luego dividiéndolas por la cantidad de días del mes, sin agregar lógica para calcular la cantidad de días que se deben ignorar.
Matrices redimensionables Matrices redimensionables
La mayoría de los lenguajes proporcionan algún tipo de matriz de tamaño variable, matriz dinámica o mutable. En Java, la matriz estándar tiene un tamaño fijo y un tipo de datos fijo, pero también puede crear una matriz de tamaño variable usando ArrayList. La mayoría de los lenguajes proporcionan algún tipo de matriz ajustable, dinámica o mutable. En Java, las matrices estándar tienen un tamaño y un tipo de datos fijos; sin embargo, también puede crear matrices de tamaño variable utilizando ArrayList.
Agregar y quitar Agregar y quitar
La ubicación donde agregamos un nuevo elemento o eliminamos uno existente sí importa, porque agregar o eliminar un elemento al final es más rápido que en cualquier otro lugar. La posición donde agrega un elemento nuevo o elimina un elemento existente sí importa, ya que agregar o eliminar elementos al final es más rápido que en cualquier otro lugar.
Por lo tanto, los elementos deberán desplazarse hacia la izquierda o hacia la derecha y volver a indexarse; reordenado. Por lo tanto, tiene un impacto en el rendimiento. Por lo tanto, el elemento debe moverse hacia la izquierda o hacia la derecha y volver a indexarse; el artículo debe ser reordenado. Por tanto, tiene un impacto en el rendimiento.
La forma de cambiar difiere de un idioma a otro, algunos cambiarán elementos en su lugar, pero otros simplemente copiarán todo el contenido de la matriz anterior en una nueva con el elemento que se agrega o elimina. La forma en que funciona la conversión, dependiendo del idioma, algunos moverán los elementos en su lugar, sin embargo, otros simplemente copiarán todo el contenido de la matriz anterior en una nueva matriz, agregando o eliminando elementos al mismo tiempo.
Ordenar matrices Ordenar matricesLa clasificación siempre requiere un uso intensivo de recursos computacionales; es posible que tengas que hacerlo, pero queremos minimizarlo. Por lo tanto, ser consciente de la cantidad de datos que tenemos y de la frecuencia con la que solicitamos ordenarlos puede llevarnos a elegir diferentes estructuras de datos.
La clasificación siempre requiere un uso intensivo de recursos computacionales; es posible que tengas que hacerlo, pero queremos minimizarlo. Por lo tanto, comprender cuántos datos tenemos y con qué frecuencia debemos ordenarlos puede llevarnos a elegir una estructura de datos diferente.
 Clasificar personas por altura —pleacher.com
Ordenar por altura
Clasificar personas por altura —pleacher.com
Ordenar por altura
La función de clasificación incorporada La función de clasificación incorporada
Cuando ordenamos matrices, hay cosas que necesita para comprender la funcionalidad de clasificación incorporada. Cuando ordenamos una matriz, es necesario conocer la función de clasificación incorporada.
En segundo lugar, ¿la función de clasificación incorporada intentará ordenar una matriz existente en su lugar o creará otra copia? La mayoría de los lenguajes intentarán ordenar una matriz existente en su lugar, mientras que algunos crearán una nueva copia de la matriz original para contener la matriz ordenada. En segundo lugar, ¿la función de clasificación incorporada intenta ordenar la matriz existente o crear otra copia? La mayoría de los lenguajes intentarán ordenar la matriz existente, mientras que algunos crearán una nueva copia de la matriz original para contener la matriz ordenada.
Ordenar objetos personalizados Ordenar objetos personalizados
En los lenguajes orientados a objetos, a menudo tienes matrices de tus propios objetos personalizados, no sólo matrices de valores numéricos simples o incluso de cadenas. En los lenguajes orientados a objetos, normalmente tienes tu propia matriz de objetos personalizados, no sólo una simple matriz de números o incluso una matriz de cadenas.
Cuando luego le pide a esa matriz que ordene esos objetos usando la función de clasificación incorporada en el idioma. Simplemente no sabrá cómo hacerlo. Porque necesita proporcionar un poco más de información sobre qué propiedad clasificar en consecuencia. Luego se solicita a la matriz que ordene estos objetos utilizando la función de clasificación integrada en el lenguaje. Simplemente no sabe cómo hacerlo. Porque necesita proporcionar más información sobre las propiedades de clasificación correspondientes.
Entonces, por ejemplo, ordene los usuarios por su identificación, nombre o fecha de nacimiento. Esto define la propiedad del objeto para ordenar en consecuencia. Por ejemplo, ordene a los usuarios por su identificación, nombre o fecha de nacimiento. Esto define las propiedades del objeto para ordenar en consecuencia.
Por lo general, solo necesita unas pocas líneas y generalmente se llama comparador, función de comparación o método de comparación. Por lo general, sólo se requieren unas pocas líneas de código y, a menudo, se denominan comparadores, funciones de comparación o métodos de comparación.
##Buscando matrices Buscar matriz
Si quisiéramos saber si un valor específico existe en algún lugar de una matriz o no, podríamos recorrer los elementos de la matriz y verificar el valor en esa posición actual y ver si es igual al objetivo o no. Si queremos saber si existe un valor específico en la matriz, podemos recorrer los elementos de la matriz y verificar el valor en la posición actual para ver si es igual al objetivo.
 Sigue buscando incluso debajo de la cama.
Sigue mirando incluso debajo de la cama.
Sigue buscando incluso debajo de la cama.
Sigue mirando incluso debajo de la cama.
El mejor de los casos es que el primer elemento sea el valor que estamos buscando. El peor de los casos es que el valor esté al final o no aparezca en ninguna parte de la matriz. Este método se conoce como búsqueda lineal o búsqueda secuencial. Este es un método de fuerza bruta poco elegante. En el mejor de los casos, el primer elemento es el valor que buscamos. El peor de los casos es que el valor aparezca al final de la matriz o no aparezca en ninguna parte de la matriz. Este método se llama búsqueda lineal o búsqueda secuencial. Este es un método de fuerza bruta poco elegante.
Si bien las búsquedas lineales son fáciles de entender, fáciles de escribir y funcionarán, son lentas. Y cuantos más elementos tengas, más lentos se vuelven. Aunque las búsquedas lineales son fáciles de entender, fáciles de escribir y funcionan, son lentas. Cuantos más elementos hay, más lento es.
Los datos deben ordenarse Es necesario ordenar los datos
Si no hay orden, ni secuencia predecible para los valores de la matriz, entonces es posible que no haya otras opciones que verificar todos los elementos de la matriz. Si los valores en la matriz no tienen orden, ni secuencia predecible, entonces puede que no haya otra opción que verificar todos los elementos de la matriz.
Por lo tanto, los datos deben ordenarse de manera que podamos utilizar un algoritmo distinto de la búsqueda lineal. Por lo tanto, tener algún tipo de orden en esos elementos es cada vez más significativo. Por lo tanto, los datos deben ordenarse de alguna manera para que podamos utilizar algoritmos distintos a la búsqueda lineal. Por lo tanto, se vuelve cada vez más importante ordenar estos elementos.
El desafío de la herencia de las estructuras de datos El desafío de la herencia de las estructuras de datos
A veces puede aceptar utilizar una capacidad de búsqueda lenta, porque la única forma de solucionarlo es ordenar la matriz, lo que a su vez agregará un impacto en el rendimiento que simplemente no vale la pena. A veces puede aceptar utilizar una función de búsqueda lenta porque la única forma de resolver el problema es ordenar la matriz, lo que a su vez añade una penalización de rendimiento que simplemente no vale la pena.
Entonces, si va a buscar en una matriz una vez, es mejor tener una complejidad de O(N) para la búsqueda lineal, que O(NLogN) para ordenar + O(LogN) para la búsqueda. Sin embargo, si va a buscar mucho, primero puede ordenar la matriz una vez al principio y ahora puede buscar con O(LogN) cada vez en lugar de la búsqueda lineal O(N). Entonces, si buscara una vez en una matriz, sería O(N) más complicado para una búsqueda lineal que la clasificación O(NLogN) + O(LogN). Sin embargo, si va a realizar muchas búsquedas, primero puede ordenar la matriz una vez al principio y ahora puede buscar con O(LogN) cada vez en lugar de O(N) con una búsqueda lineal.No se puede tener una estructura de datos que sea igualmente buena en todas las situaciones. Una estructura de datos ordenada naturalmente requiere menos tiempo para buscar un elemento y más tiempo para insertarlo porque mantiene la matriz ordenada. Mientras que una matriz básica requiere más tiempo de búsqueda y menos tiempo para insertar elementos al final de la matriz. No se puede tener una estructura de datos que sea igualmente buena en todas las situaciones. Una estructura de datos ordenada naturalmente requiere menos tiempo para buscar elementos y más tiempo para insertarlos porque mantiene el orden de la matriz. Mientras que las matrices básicas requieren más tiempo de búsqueda, insertar elementos al final de la matriz lleva menos tiempo.
##Lista de listas
Las listas son estructuras de datos bastante simples. Su estructura realiza un seguimiento de la secuencia de elementos. Las listas son estructuras de datos muy simples. Está estructurado para realizar un seguimiento del orden de los artículos.
It’s a collection of items (called nodes) ordered in a linear sequence.
它是按线性顺序排列的项(称为节点)的集合。
Estos nodos no necesitan ubicarse uno al lado del otro en la memoria como lo es una matriz. No es necesario que los nodos se asignen de forma adyacente en la memoria como las matrices.
Existe un concepto de programación teórica general de una lista, y existe la implementación específica de una estructura de datos de lista, que puede haber tomado esta idea básica de lista y agregado una gran cantidad de funcionalidades. Las listas se implementan como listas enlazadas (simples, dobles, circulares,…) o como matrices dinámicas. Existe un concepto de programación teórica general de listas, y hay una implementación específica de una estructura de datos de lista que probablemente toma este concepto básico de lista y agrega un montón de funcionalidades. Las listas se pueden implementar como listas enlazadas (listas enlazadas individualmente, listas enlazadas doblemente, listas enlazadas circulares, listas enlazadas circulares) o como matrices dinámicas.
Una matriz versus una lista Matriz versus lista
Una lista es un tipo diferente de estructura de datos de una matriz. Las listas son una estructura de datos diferente a las matrices.
La mayor diferencia está en la idea de acceso directo frente a acceso secuencial. Las matrices permiten ambas cosas; acceso directo y secuencial, mientras que las listas permiten sólo acceso secuencial. Y esto se debe a la forma en que estas estructuras de datos se almacenan en la memoria. La mayor diferencia es el concepto de acceso directo y acceso secuencial. Las matrices permiten ambas cosas; acceso directo y secuencial, mientras que las listas solo permiten acceso secuencial. Esto se debe a la forma en que se almacenan estas estructuras de datos en la memoria.
La estructura de la lista no admite índices numéricos como lo es una matriz. La estructura de una lista no admite la indexación numérica como una matriz.
##Listas enlazadas Lista enlazada
It’s a collection of nodes, where each node has a value and a link to the next node in the list.
它是节点的集合,每个节点都有一个值和到列表中下一个节点的链接。
El puntero del último nodo apunta a NULL, o terminador, o un nodo ficticio. El puntero del último nodo apunta a NULL, terminador o nodo virtual.
 Lista enlazada - wikipedia
Lista de enlaces - Wikipedia
Lista enlazada - wikipedia
Lista de enlaces - Wikipedia
Debido a la forma en que está construido, agregar y eliminar elementos es mucho, mucho más fácil que con una matriz. Debido a la forma en que está construido, agregar y eliminar elementos es mucho más sencillo que una matriz.
Pero, con las matrices, es necesario desplazarse hacia la izquierda o hacia la derecha para mantener su estructura ordenada significativa. Incluso agregar elementos al final de la matriz puede requerir la reasignación de toda la matriz para almacenar la matriz en un área contigua de memoria. Sin embargo, con las matrices, es necesario desplazarla hacia la izquierda o hacia la derecha para mantener una estructura ordenada significativa. Incluso si agrega un elemento al final de la matriz, aún necesita reasignar toda la matriz para que se almacene en un área de memoria contigua.
##Lista doblemente enlazada Lista doblemente enlazada
Lo que hemos introducido es una lista enlazada, pero para ser un poco más específicos, se llama “Lista enlazada individualmente”. También podemos tener una “Lista Doblemente Enlazada”. Introdujimos una lista enlazada, pero para ser más específicos, esta es la llamada “lista enlazada individualmente”. También podemos tener una “lista doblemente enlazada”.
En lugar de que cada nodo tenga una referencia solo al siguiente nodo, agregamos un dato más que también tiene una referencia al nodo anterior. Entonces, nos permite avanzar y retroceder, recorrer la lista en cualquier dirección. En lugar de que cada nodo tenga solo una referencia al siguiente nodo, se agrega otro dato que también tiene una referencia al nodo anterior. Entonces, nos permite avanzar y retroceder, recorriendo la lista en cualquier dirección.
 Lista doblemente enlazada - wikipedia
Lista doblemente enlazada - Wikipedia
Lista doblemente enlazada - wikipedia
Lista doblemente enlazada - Wikipedia
Las listas enlazadas en la mayoría de los idiomas normalmente se implementan como listas doblemente enlazadas. En la mayoría de los idiomas, las listas enlazadas normalmente se implementan como listas doblemente enlazadas.
La lista simple y doblemente enlazada La lista simple y doblemente enlazada
La operación Agregar claramente requiere menos trabajo en una lista enlazada individualmente, porque una lista enlazada doblemente requiere cambiar más enlaces que una lista enlazada individualmente. Agregar una operación ** a una lista enlazada individualmente es obviamente menos trabajo ya que una lista doblemente enlazada requiere más cambios de enlace que una lista enlazada individualmente.
Para una lista enlazada individualmente, asumimos que insertamos al principio o después de algún nodo determinado. Para listas enlazadas individualmente, asumimos la inserción después del nodo principal o de algún nodo determinado.
En caso de agregar antes de un nodo determinado, necesitará conocer el nodo anterior a ese nodo determinado, lo que requerirá que acceda secuencialmente a todos los nodos hasta que encuentre el nodo que está buscando. Si desea agregar un nodo antes de un nodo determinado, necesita conocer los nodos anteriores a ese nodo, lo que requerirá que visite todos los nodos secuencialmente hasta encontrar el nodo que está buscando.
Eliminar es más simple y potencialmente más eficiente en una lista doblemente enlazada, porque en una lista simplemente enlazada, es necesario conocer el nodo antes del nodo que se va a eliminar. En una lista doblemente enlazada, la eliminación es más sencilla y probablemente más eficiente, porque en una lista simplemente enlazada, necesita conocer el nodo antes que el nodo que desea eliminar.
Lista circular enlazada Lista circular enlazadaEn una lista enlazada individualmente, si el siguiente puntero del último nodo apunta al primer nodo. Entonces, es “Lista circular enlazada”. Y si el puntero anterior del primer nodo apunta al último nodo también. Ahora bien, esto se consideraría una “Lista circular doblemente enlazada”.
En una lista enlazada individualmente, si el siguiente puntero del último nodo apunta al primer nodo. Luego está la “lista circular enlazada”. Si el puntero anterior del primer nodo apunta al último nodo. Ahora bien, esto se consideraría una “lista circular doblemente enlazada”.

Lista circular enlazada - wikipedia Lista circular enlazada - Wikipedia
No es común, pero puede resultar útil para determinados problemas. Entonces, si llegamos al final de la lista y decimos siguiente, simplemente comenzamos de nuevo desde el principio. Esto no es común, pero puede resultar útil para ciertos problemas. Entonces, si llegamos al final de la lista, digamos el siguiente, comenzamos donde empezamos.
Pila de pilas
Al igual que las matrices y las listas, las pilas y las colas también son colecciones de elementos. Son simplemente diferentes formas en que podemos sostener varios artículos. Es una estructura de datos de último en entrar, primero en salir, sin preocuparse por los índices numéricos. Al igual que las matrices y las listas, las pilas y las colas son colecciones de elementos. Son simplemente diferentes formas en que podemos acomodar múltiples proyectos. Es una estructura de datos de último en entrar, primero en salir y no se preocupa por los índices numéricos.
It’s a collection of items where we add and remove items to and from the top of the stack.
它是一个项集合,我们在堆栈顶部添加和删除项。
 Pila de platos sucios
montón de platos sucios
Pila de platos sucios
montón de platos sucios
Implementación de pila Implementación de pila
Una pila se puede implementar fácilmente utilizando una matriz o una lista vinculada Las pilas se pueden implementar fácilmente con matrices o listas vinculadas
Uso de pilas Uso de pila
Stack no se limita a modelar únicamente situaciones del mundo real (lo mismo ocurre con las colas). Uno de los mejores usos de una pila en programación es al analizar código o expresiones, donde necesita hacer algo como validar la cantidad correcta de llaves, corchetes o paréntesis de apertura y cierre. Stack no se limita a simular situaciones del mundo real (lo mismo ocurre con las colas). Uno de los mejores usos de la pila en programación es cuando se analiza código o una expresión y es necesario hacer algo como verificar el número correcto de llaves de apertura, corchetes o corchetes.
Las operaciones básicas de las pilas Las operaciones básicas de la pila
Son: push(), pop() y peek(). push es para empujar un nuevo elemento en la parte superior de la pila, y pop devolverá (y eliminará) el elemento en la parte superior, mientras que peek obtendrá el elemento en la parte superior sin eliminarlo. Ellos son: push(), pop() y peek(). push se usa para empujar un nuevo elemento en la parte superior de la pila, pop devolverá (y eliminará) el elemento superior y peek obtendrá el elemento superior sin eliminarlo.
Pilas frente a matrices frente a listas enlazadas Pilas frente a matrices frente a listas enlazadas
Trabajar con una pila es más sencillo que trabajar con matrices o listas enlazadas, porque hay menos cosas que puedes hacer con una pila. Usar una pila es más simple que usar una matriz o una lista vinculada porque hay menos cosas que puedes hacer con la pila.
Esta es una estructura de datos intencionalmente limitada y restringida. Todo lo que hacemos es empujar y hacer estallar y tal vez mirar. Y si intentas hacer algo más con esta pila, estás utilizando la estructura de datos incorrecta. Esta es una estructura de datos intencionalmente restringida. Todo lo que hacemos es empujar, hacer estallar o mirar. Si desea utilizar esta pila para otras cosas, está utilizando la estructura de datos incorrecta.
##Colas Cola
La diferencia clave entre una pila y una cola. Las pilas son las últimas en entrar, primero en salir (LIFO), mientras que las colas son las primeras en entrar, primero en salir (FIFO). Y al igual que con las pilas, ni siquiera deberíamos pensar en índices numéricos. Diferencia clave entre pila y cola. Las pilas son las últimas en entrar, las primeras en salir (LIFO), mientras que las colas son las primeras en entrar, primero en salir (FIFO). Al igual que la pila, ni siquiera deberíamos pensar en la indexación numérica.
It’s a collection of items where we add items to the end and remove items from the front of the queue.
它是项的集合,我们在末尾添加项,并从队列前面删除项。
 Cola de personas personas en fila
Cola de personas personas en fila
Implementación de colas Implementación de colas
Al igual que con las pilas, una cola se puede implementar utilizando una matriz o una lista vinculada. Al igual que una pila, una cola se puede implementar mediante una matriz o una lista vinculada.
Uso de colas Usar colas
Las colas se usan muy comúnmente en situaciones de concurrencia para realizar un seguimiento de las tareas que están esperando ser realizadas y asegurarnos de que las realizamos en ese orden. Las colas se utilizan con mucha frecuencia en situaciones de concurrencia para realizar un seguimiento de las tareas que esperan ser ejecutadas y garantizar que se procesen en orden.
Las operaciones básicas de las colas Las operaciones básicas de la cola
Como una pila: agregar(), eliminar() y mirar(). Como una pila: agregar(), eliminar() y mirar().
Colas de prioridad cola de prioridad
Algunos idiomas ofrecen una versión de una cola, llamada cola prioritaria. Esto le permite organizar elementos en la cola según su prioridad. Algunos idiomas proporcionan una versión de una cola llamada cola prioritaria. Esto le permite organizar los elementos en la cola según su prioridad.
It’s a queue, where items with higher priority step ahead of items with lower priority in the queue.
它是一个队列,在队列中优先级较高的项先于优先级较低的项。
Cómo funcionan las colas prioritarias Cómo funcionan las colas prioritarias
Cuando agrega elementos que tienen la misma prioridad, se pondrán en cola normalmente en el orden de primero en entrar, primero en salir. Si algo llega con una prioridad más alta, irá delante de ellos en la cola. Cuando agrega elementos con la misma prioridad, se ponen en cola en el orden normal. Si surge algo con mayor prioridad, irá delante de ellos en la cola.
Definiendo la prioridad Definiendo la prioridad
Puede definir en función de qué elemento tiene mayor, menor o igual prioridad. Esto se hace implementando un comparador o una función de comparación (como cuando se clasifican matrices), donde usted proporciona su propia lógica para comparar la prioridad entre elementos. Puede definir en función de la prioridad alta, baja o igual de un elemento. Esto se puede lograr implementando un comparador o una función de comparación (como ordenar una matriz) donde puede proporcionar su propia lógica al comparar prioridades entre elementos.
Deque cola de doble extremoEl deque, pronunciado “DEK”, se usa cuando queremos aprovechar el poder de la cola y la pila, donde se puede agregar o eliminar desde el inicio o el final.
Deque se pronuncia “DEK” y usamos deque cuando queremos aprovechar las capacidades de las colas y pilas, donde podemos agregar o eliminar desde el principio o el final.
It’s a queue and a stack at the same time.
它同时是一个队列和一个堆栈。
##Matrices asociativas Matriz asociativa
Brindan la posibilidad de utilizar claves significativas para trabajar con elementos de nuestras estructuras de datos, en lugar de trabajar con índices numéricos como claves. Esto proporciona una relación significativa entre la clave y el valor. Permiten que los elementos de una estructura de datos se procesen utilizando claves significativas en lugar de índices numéricos como claves. Esto proporciona relaciones significativas entre claves y valores.
It is a collection of key-value pairs.
它是键-值对的集合。
var user = {
firstName: "Bob",
lastName: "Jones",
age: 26,
email: "bob.jones@example.com"
};
La implementación de matrices asociativas tiene diferentes nombres. En Objective-C y Python, se llaman diccionarios. Las implementaciones de matrices asociativas tienen diferentes nombres. En Objective-C y Python, se denominan diccionarios.
El orden de los elementos El orden de los elementos
A diferencia de una matriz básica, en una matriz asociativa las claves no necesitan estar en ningún orden específico. Porque el orden no es una preocupación en las matrices asociativas. A diferencia de las matrices básicas, las claves de una matriz asociativa no necesitan estar en ningún orden específico. Porque el orden no tiene nada que ver con las matrices asociativas.
Claro, puede resultarle útil ordenarlos por clave. Puede que le resulte útil ordenarlos por valor o puede que no necesite ordenarlos en absoluto. Por supuesto, puede resultarle útil ordenar por clave. Puede resultarle útil ordenarlos por valor o puede que no necesite ordenarlos en absoluto.
Clave duplicada Clave duplicada
De la misma manera que no aparece el mismo número de índice dos veces en una matriz básica, no puede haber claves duplicadas y las claves deben ser únicas en una matriz asociativa. Asimismo, el mismo número de índice no puede aparecer dos veces en una matriz básica, no puede haber claves duplicadas y las claves deben ser únicas en una matriz asociativa.
Claves y valores Tipos de datos Tipos de datos de clave y valor
Normalmente puede utilizar cualquier tipo de datos como clave o valor. Es común utilizar una cadena como clave. Generalmente puede utilizar cualquier tipo de datos como clave o valor. Por lo general, las cadenas se utilizan como claves.
La mayoría de las matrices asociadas, ya sea que se llamen diccionarios, mapas o hashes, se implementan utilizando la estructura de datos de la tabla hash. Entonces, comenzaremos con el hash y luego nos sumergiremos en las tablas hash. La mayoría de las matrices asociativas se implementan utilizando estructuras de datos de tablas hash, ya sean diccionarios, mapas o hashes. Entonces, comenzaremos con los hashes y luego nos sumergiremos en las tablas hash.
##Hashing Hash
El hash es un concepto valioso en programación. Se utiliza no sólo en estructuras de datos, sino también en seguridad, criptografía, gráficos y audio. El hash es un concepto valioso en programación. Se utiliza no sólo para estructuras de datos sino también para seguridad, cifrado, gráficos y audio.
It’s a way to take our data and run it through a function, which will return a small, simplified reference generated from that original data.
这是一种获取数据并通过函数运行数据的方法,函数将返回从原始数据生成的一个小的、简化的引用。
 Hashing se usa comúnmente con contraseñas Hashing se usa comúnmente con contraseñas
Hashing se usa comúnmente con contraseñas Hashing se usa comúnmente con contraseñas
La referencia puede ser simplemente un número entero, letras y números, etc. La referencia puede ser simplemente un número entero, letras y números, etc.
¿Por qué utilizar hash? ¿Por qué utilizar hash?
Porque poder tomar un objeto complejo y reducirlo a una única representación entera. Entonces, podemos usar ese valor entero para llegar a una ubicación determinada en la estructura de datos. Porque puedes convertir un objeto complejo en una representación entera. Por lo tanto, podemos utilizar este valor entero para alcanzar una determinada ubicación en la estructura de datos.
Hashing no es cifrado Hashing no es cifrado
Las funciones hash no son reversibles; Son unidireccionales. Por lo tanto, no puede convertir el resultado de un valor hash a los datos originales. Por lo tanto, se pierde información al hacer hash, está bien, es intencional. Las funciones hash son irreversibles; son unidireccionales. Por lo tanto, no puede convertir el resultado hash a los datos originales. Por lo tanto, la información se pierde durante el proceso de hash y esto es intencional.
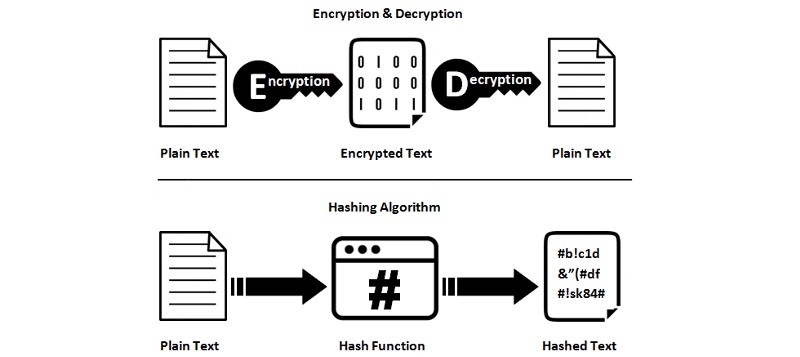 Hashing versus cifrado - ssl2buy.com Hashing versus cifrado - ssl2buy.com
Hashing versus cifrado - ssl2buy.com Hashing versus cifrado - ssl2buy.com
Implementación de la función hash Implementación de la función hash
Digamos que tenemos una clase de persona definida y queremos definir una función hash en esta clase. La función hash debe devolver una referencia única específica (generalmente un número entero) para un objeto de persona específico. Este único número entero se genera utilizando los datos de un objeto de persona (nombre, apellido, fecha de nacimiento, etc.). Supongamos que definimos una clase de persona y queremos definir una función hash en esta clase. La función hash debe devolver una referencia específica (normalmente un número entero) para un objeto persona específico. Este número entero se genera utilizando los datos del objeto persona (nombre, apellido, fecha de nacimiento, etc.).
Reglas de hash Reglas de hash
-
Si tomamos exactamente el mismo objeto, con estos mismos datos, y lo introducimos nuevamente en la función hash, esperaría el mismo resultado hash.
-
Si tienes dos objetos diferentes que consideras iguales, deberían devolver el mismo valor hash.
-
Si bien dos objetos iguales deberían producir el mismo valor hash, dos valores hash iguales no garantizan que provengan de objetos iguales, ¿por qué? Porque dos objetos diferentes pueden, bajo algunas circunstancias, entregar el mismo resultado a partir de una función hash (consulte Colisión de hash). Dos objetos iguales deberían producir el mismo valor hash, pero no se garantiza que dos valores hash iguales provengan de objetos iguales, ¿por qué? Porque en algunos casos dos objetos diferentes pueden pasar el mismo resultado de la función hash (ver colisiones hash).
Colisión de hash Colisión de hash
Es cuando tenemos diferentes objetos con diferentes datos, pero dando el mismo resultado de valor hash. Cuando tenemos diferentes objetos y diferentes datos, pero obtenemos el mismo valor hash.Podría deberse a que la función hash es una función hash simple, pero también es posible incluso con funciones hash más complejas. En la mayoría de los casos, está bien, podemos gestionar la colisión de hash. Probablemente esto se deba a que la función hash es una función hash simple, pero son posibles funciones hash aún más complejas. En la mayoría de los casos, esto está bien y podemos gestionar las colisiones de hash.
##Tablas hash Tabla hash
La idea del hash fue fundamental para comprender la estructura de datos de la tabla hash. La idea de hash es la base para comprender la estructura de datos de la tabla hash.
It’s a typical data structure to implement an associative arrays; mapping keys to values.
实现关联数组是一种典型的数据结构;将键映射到值。
 Asignación de números (claves) a cuadros Asignación de números (claves) a cuadros
Asignación de números (claves) a cuadros Asignación de números (claves) a cuadros
Tablas hash frente a matrices frente a lista rayada Tablas hash frente a matrices frente a listas
La gran ventaja de las tablas hash sobre las matrices y las listas enlazadas es que son muy rápidas, tanto para ver si un elemento existe o encontrar un elemento específico en una tabla hash, como para insertar y eliminar elementos. El mayor beneficio de las tablas hash en comparación con las matrices y las listas vinculadas es que son muy rápidas, tanto para ver si existe un elemento, para encontrar un elemento específico en la tabla hash como para insertar y eliminar elementos.
¿Cómo funcionan las tablas hash? ¿Cómo funcionan las tablas hash?
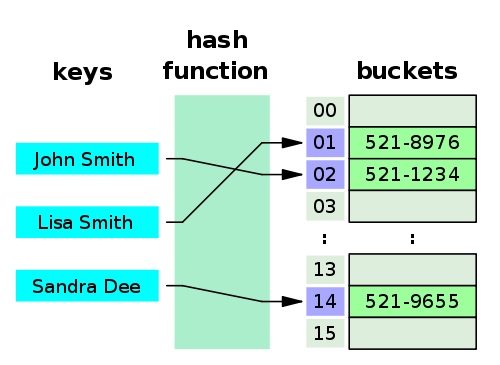 Una pequeña guía telefónica como tabla hash — Wikipedia Una pequeña guía telefónica como tabla hash — Wikipedia
Una pequeña guía telefónica como tabla hash — Wikipedia Una pequeña guía telefónica como tabla hash — Wikipedia
Cuando se crea una tabla hash, en realidad es internamente una estructura de datos muy basada en matrices y, por lo general, se puede crear con una capacidad inicial. La tabla hash consta de una serie de ranuras o depósitos que contienen los valores. Cuando se crea una tabla hash, en realidad es una estructura de datos muy basada en matrices que generalmente se puede crear con una capacidad inicial. Una tabla hash consta de una matriz de espacios o depósitos que contienen valores.
Al agregar un par clave-valor, tomará nuestra clave y la ejecutará a través de la función hash, obteniendo un valor hash específico (generalmente un número entero). Al agregar un par clave-valor, toma nuestra clave y la ejecuta a través de una función hash, lo que da como resultado un valor hash específico (generalmente un número entero).
Si este valor hash es grande, es posible que deba simplificarlo con respecto al tamaño actual de la tabla hash. Si este hash es grande, es posible que deba simplificarlo según el tamaño actual de la tabla hash.
Luego, asignará el valor a un elemento de la matriz con el índice igual al valor entero hash devuelto. Luego asignará ese valor a un elemento de la matriz con un índice igual al valor entero hash devuelto.
// adding a key-value pair
hash_table.add(key, value)
// what happen behind the scene
index = hash(key)
index = index % array_size
array[index] = value
Acceder a un valor dada una clave sigue la misma idea. Tomará esa clave, la ejecutará exactamente a través de la misma función hash y luego podrá ir directamente a una ubicación específica que contenga el valor que estamos buscando. Acceder al valor de una clave determinada sigue la misma idea. Toma esa clave, la ejecuta exactamente a través de la misma función hash y luego puede ir directamente a una ubicación específica que contiene el valor que estamos buscando.
No hay búsqueda lineal, búsqueda binaria, ni recorrido por una lista. Simplemente vamos directamente al elemento que necesitamos. Sin búsquedas lineales, sin búsquedas binarias, sin listas transversales. Obtenemos directamente el elemento que necesitamos.
Gestión de conflictos de gestión de colisiones
Podemos esperar que surja una colisión de hash; cuando obtenemos el mismo valor hash para diferentes claves. Pero, ¿cómo gestionarlo? Podemos esperar que se produzcan colisiones de hash; cuando obtenemos el mismo valor hash para diferentes claves. Pero, ¿cómo gestionarlo?
Cuando agregamos un nuevo par clave-valor y ocurre una colisión, pondrá ese valor en la misma ubicación, incluso si hay otro valor existente en esa ubicación. Cuando agregamos un nuevo par clave-valor y se produce una colisión, colocará ese valor en la misma posición, incluso si hay otro valor existente en esa posición.
Ahora, las implementaciones de tablas hash tienen diferentes formas de abordar esto automáticamente. Estos van desde que cada ubicación contiene una colección simple, como una matriz o una lista vinculada. Ahora, las implementaciones de tablas hash tienen diferentes formas de manejar esto automáticamente. Cada ubicación contiene una colección simple, como una matriz o una lista vinculada.
Por lo tanto, aún podríamos llegar a cualquier ubicación muy rápido, pero una vez que lleguemos a la ubicación con múltiples valores, la tabla hash recorrerá esa lista interna para encontrar lo que estamos buscando. Así que aún podemos llegar a cualquier ubicación muy rápidamente, pero una vez que llegamos a una ubicación con múltiples valores, la tabla hash revisa esa lista interna para encontrar lo que estamos buscando.
Cada nodo de la lista vinculada contendrá a su vez el valor asociado con una clave específica. Además, contendrá esa clave o una referencia a esa clave. Porque en el caso de varios valores dentro de la misma ubicación, necesitamos saber a qué clave pertenece este valor. Cada nodo de la lista vinculada contiene a su vez un valor asociado con una clave específica. Además, contendrá la clave o una referencia a la clave. Porque para varios valores dentro de la misma posición, necesitamos saber a qué clave pertenece este valor.
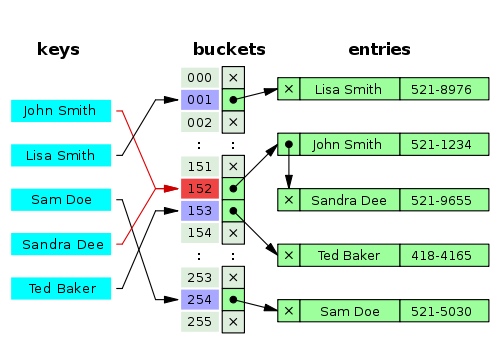 Colisión de hash resuelta mediante encadenamiento por separado - wikipedia Colisión de hash resuelta mediante encadenamiento por separado - Wikipedia
Colisión de hash resuelta mediante encadenamiento por separado - wikipedia Colisión de hash resuelta mediante encadenamiento por separado - Wikipedia
Esto es lo que se llama “Técnica de encadenamiento separado” en las tablas hash. Ahora, existen otras técnicas para gestionar colisiones dentro de tablas hash, incluido el direccionamiento abierto, el hash Cuckoo, la rayuela y el hash Robin Hood. Esta es la “técnica de enlace independiente” en las tablas hash. Hoy en día, existen otras técnicas para gestionar colisiones dentro de tablas hash, incluido el direccionamiento abierto, el hash cuco, la rayuela y el hash Robin Hood.
Escritura de funciones hash Escritura de funciones hash
Cuando desee almacenar pares clave-valor utilizando la estructura de datos de la tabla hash, probablemente la mayoría de los objetos ya tengan una función hash. El comportamiento predeterminado suele ser el de devolver un número entero; calculado a partir de la dirección de memoria de ese objeto. Cuando desee utilizar una estructura de datos de tabla hash para almacenar pares clave-valor, probablemente la mayoría de los objetos ya tengan una función hash. El comportamiento predeterminado suele ser devolver un número entero; calculado a partir de la dirección de memoria del objeto.Si alguna vez anula el comportamiento de igualdad en su clase, debe anular el comportamiento hash. Porque los códigos hash están muy ligados a la igualdad y, si tienes dos objetos que consideras iguales, deberían devolver el mismo valor hash. Si alguna vez anula el comportamiento de igualdad en una clase, debe anular el comportamiento de hash. Porque los códigos hash están muy relacionados con la igualdad, y si hay dos objetos que consideras iguales, deberían devolver el mismo valor hash.
Nuevamente, si cambia lo que significa que sus objetos sean iguales, también debe cambiar lo que significa aplicar hash a estos objetos. Del mismo modo, si cambia el significado de igualdad de objetos, también debe cambiar el significado de hash de esos objetos.
Los objetos de cadena ya anularon su propia igualdad y comportamiento hash. Entonces, si tiene dos objetos de cadena separados, seguirán contando como iguales y devolverán el mismo hash, si tienen el mismo valor, incluso si en realidad son objetos de cadena separados asignados en diferentes partes de la memoria. Los objetos de cadena han anulado su propio comportamiento de igualdad y hash. Entonces, si tiene dos objetos de cadena separados, seguirán siendo iguales y devolverán el mismo hash si tienen el mismo valor, aunque en realidad sean objetos de cadena separados asignados en diferentes partes de la memoria.
Conjuntos establecidos
Cuando todo lo que necesitas es un contenedor grande, puedes poner un montón de elementos en él, sin que te importe la secuencia. Cuando solo necesitas un contenedor grande, puedes poner un montón de cosas en él y no tienes que pensar en el orden.
No existe una secuencia específica como ocurre con una lista vinculada, una pila o una cola. No hay pares clave-valor como ocurre con una tabla hash. No existe una secuencia específica, como una lista vinculada, pila o cola. No hay pares clave-valor, como en una tabla hash.
It’s an unordered collection of items, with no repeated values.
它是一个无序的项目集合,没有重复的值。
Por desordenado, quiero decir que no hay un índice como una matriz. Desordenado significa que no hay ningún índice como en una matriz.
 Una bolsa de comida del supermercado Una bolsa de comida
Una bolsa de comida del supermercado Una bolsa de comida
Establecer implementación Establecer implementación
En realidad, los conjuntos utilizan la misma idea de estructura de datos de tablas hash la mayor parte del tiempo. Pero, en lugar de pares clave-valor (hash de una clave y almacenar su valor), cuando se utiliza un conjunto, la clave también se considera como el valor (o el valor se asigna a un valor ficticio o predeterminado). En realidad, las colecciones utilizan la misma idea de una estructura de datos de tabla hash en la mayoría de los casos. Sin embargo, a diferencia de los pares clave-valor (donde la clave se aplica mediante hash y su valor se almacena), cuando se trabaja con colecciones, las claves también se consideran valores (o los valores se asignan a valores ficticios o predeterminados).
Entonces, para obtener cualquier valor específico, o cualquier objeto específico en el conjunto, necesitas tener el objeto en sí. Y la única razón para hacer esto es comprobar su existencia. A esto se le suele denominar “verificar membresía”. Entonces, para obtener cualquier valor específico en la colección, o cualquier objeto específico, necesitas el objeto en sí. La única razón para hacer esto es comprobar si existe. A esto se le suele llamar “comprobar la membresía”.
Los conjuntos se pueden implementar utilizando un árbol de búsqueda binario autoequilibrado para conjuntos ordenados o una tabla hash para conjuntos no clasificados. Los conjuntos ordenados se pueden implementar utilizando árboles de búsqueda binarios autoequilibrados, o se pueden implementar conjuntos no clasificados utilizando tablas hash.
La ventaja de los conjuntos Las ventajas de los conjuntos
A diferencia de una matriz, de los valores de una matriz asociativa o de una lista vinculada, los conjuntos no permiten duplicados. No puedes agregar el mismo objeto, el mismo valor dos veces al mismo conjunto. A diferencia de los valores en matrices, matrices asociativas o listas vinculadas, los conjuntos no permiten duplicados. No se puede añadir dos veces el mismo objeto y el mismo valor a la misma colección.
Los conjuntos están diseñados para una búsqueda muy rápida, para poder ver rápidamente si ya tenemos un valor contenido en una colección. Las colecciones están diseñadas para búsquedas rápidas, de modo que pueda ver rápidamente si un valor ya está contenido en la colección.
También puede recorrer todos los elementos de un conjunto, pero es posible que no tenga ningún orden garantizado. También puede iterar sobre todos los elementos de una colección y es posible que no tenga ningún orden garantizado.
##árboles árbol La idea de una estructura de datos de árbol es que tenemos una colección de nodos y los nodos tienen conexiones, tienen vínculos entre sí. El concepto de una estructura de datos de árbol es que tenemos un conjunto de nodos, y estos nodos tienen conexiones y existen vínculos entre ellos.
Esto suena similar a las listas enlazadas. Pero en una lista enlazada, siempre pasamos de un nodo a un siguiente nodo específico. Mientras está en un árbol, cada nodo puede vincularse a uno, dos o más nodos. Esto suena similar a una lista vinculada. Pero en una lista enlazada, siempre pasamos de un nodo a un siguiente nodo específico. En un árbol, cada nodo puede estar vinculado a uno, dos o más nodos.
It’s a collection of nodes, where each node might link to one, or two, or more nodes.
它是节点的集合,每个节点可能链接到一个、两个或多个节点。
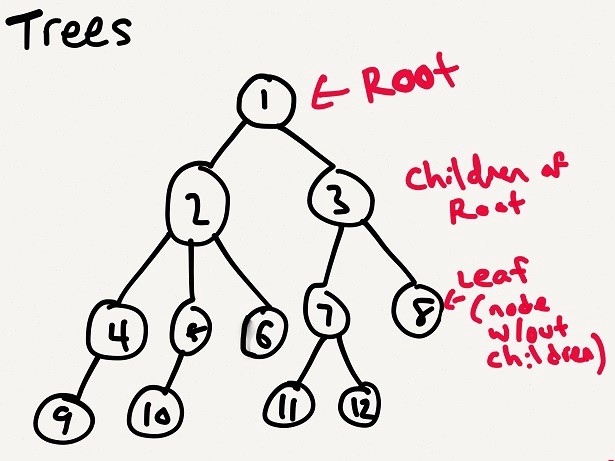 Un árbol - richardkho.com
Un árbol - richardkho.com
Terminologías del árbol Terminología del árbol
Hay algunas terminologías que vienen con el árbol. Puedes encontrar más sobre ellos aquí. Son esenciales para comprender y trabajar con los árboles. Hay algunos términos que vienen con este árbol. Puedes encontrar más información sobre ellos aquí. Son esenciales para comprender y estudiar los árboles.
Árboles binarios Árbol binario
Un árbol binario es simplemente un árbol con un máximo de dos nodos secundarios por cada nodo principal. Los árboles binarios se utilizan a menudo para implementar una maravillosa estructura de búsqueda llamada “árbol de búsqueda binaria” o “BST”. Un árbol binario es un árbol con como máximo dos nodos secundarios para cualquier nodo principal. Los árboles binarios se utilizan a menudo para implementar una elegante estructura de búsqueda llamada “árbol de búsqueda binaria” o “BST”.
##Árboles de búsqueda binaria (BST) Árbol de búsqueda binaria (BST)
It’s a specific type of binary tree, where the left child node is less than its parent, and a right child node is greater than its parent.
它是一种特定类型的二叉树,其中左子节点小于其父节点,而右子节点大于其父节点。
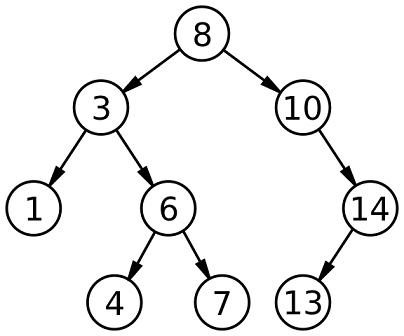 Un árbol de búsqueda binaria (BST) - Wikipedia Un árbol de búsqueda binaria (BST) - Wikipedia
Un árbol de búsqueda binaria (BST) - Wikipedia Un árbol de búsqueda binaria (BST) - Wikipedia
¿Cómo funcionan los árboles de búsqueda binaria? ¿Cómo funcionan los árboles de búsqueda binarios?
La regla es que el nodo hijo izquierdo debe ser menor que sus padres, y un nodo hijo derecho debe ser mayor que sus padres, y esa regla se sigue en todo el árbol. La regla es que el nodo hijo izquierdo debe ser más pequeño que su nodo padre, y el nodo hijo derecho debe ser más grande que su nodo padre, y esta regla continúa en el árbol.Y a medida que insertamos nuevos nodos con valores, siempre se seguirá la regla para garantizar que el árbol permanezca ordenado. Cuando insertamos un nuevo nodo con un valor, siempre se seguirán reglas para garantizar que el árbol permanezca ordenado.
Por lo tanto, es una estructura de datos que naturalmente permanece ordenada y a veces se la llama “Un árbol ordenado” o “Un árbol ordenado”. Por lo tanto, es una estructura de datos que mantiene naturalmente el orden y, a veces, se la denomina “árbol ordenado” o “árbol ordenado”.
Almacenamiento de nodos como pares clave-valor Almacenamiento de nodos como pares clave-valor
Los árboles de búsqueda binarios se utilizan a menudo para almacenar pares clave-valor, es decir, los nodos constan de una clave y un valor asociado. Y es la clave que se usaría para ordenar los nodos en consecuencia en un árbol de búsqueda binario. Los árboles de búsqueda binaria se utilizan normalmente para almacenar pares clave-valor, es decir, los nodos constan de una clave y un valor asociado. Ésta es la clave para ordenar los nodos en un árbol de búsqueda binario.
Duplicados
No puede tener claves duplicadas, del mismo modo que no tiene claves duplicadas en una tabla hash o incluso en una matriz. No puede haber claves duplicadas, al igual que no puede haber claves duplicadas en una tabla hash o incluso en una matriz.
Agregar y acceder a nodos Agregar y acceder a nodos
Agregar y acceder a nodos sigue la misma regla mencionada anteriormente. Si el nodo actual es menor que, vaya a la derecha, si es mayor que, vaya a la izquierda. Agregar y acceder a nodos sigue las mismas reglas que las anteriores. Si el nodo actual es más pequeño, vaya a la derecha, si es mayor, vaya a la izquierda.
Recuperar nodos en orden Recuperar nodos en orden
El otro beneficio es que los árboles de búsqueda binarios permanecen ordenados. Entonces, si recuperamos los elementos de izquierda a derecha, de abajo hacia arriba, los sacaremos todos en orden. Otro beneficio es que los árboles de búsqueda binarios mantienen el orden. Entonces, si recuperamos los elementos de izquierda a derecha y de abajo hacia arriba, los ordenaremos.
Árbol desequilibrado Árbol desequilibrado
Es cuando el árbol tiene más niveles de nodos en el lado derecho que en el izquierdo (o viceversa). Cuando hay más nodos en el lado derecho del árbol que en el izquierdo (y viceversa).
Aunque es inusual que suceda este tipo de cosas, no siempre podemos garantizar que la forma en que se agregan los datos nos permita construir un árbol con una estructura perfectamente simétrica hasta el final. Aunque esto rara vez sucede, no siempre podemos garantizar que agreguemos datos de una manera que nos permita construir un árbol con una estructura completamente simétrica.
En este caso decimos que nuestro árbol está desequilibrado; Hay más niveles de un lado que del otro. Y tendríamos que realizar más comprobaciones para buscar, insertar o eliminar valores en el lado derecho que en el izquierdo (o viceversa). En este caso decimos que el árbol está desequilibrado; un lado tiene más niveles de energía que el otro. Necesitamos realizar más comprobaciones para buscar, insertar o eliminar cualquier valor a la derecha que a la izquierda (o viceversa).
Implementaciones del árbol de búsqueda binaria Implementación del árbol de búsqueda binaria
De lo que hemos estado hablando es de la idea abstracta de una estructura de datos de árbol de búsqueda binaria. Sin embargo, existen varias implementaciones de esta idea de árbol de búsqueda binario que son árboles de búsqueda binarios autoequilibrados. Lo que hemos estado discutiendo es la idea abstracta de una estructura de datos de árbol de búsqueda binaria. Sin embargo, existen varias implementaciones de esta idea de árbol de búsqueda binario que son árboles de búsqueda binarios autoequilibrados.
La idea importante al equilibrar un árbol de búsqueda binario es que el número de niveles sea aproximadamente igual entre sí. No tenemos tres niveles a la izquierda y veinte a la derecha. La idea importante al equilibrar un árbol de búsqueda binario es que el número de niveles sea aproximadamente igual. No hay tres pisos a la izquierda ni veinte pisos a la derecha.
Ejemplos de árboles con autoequilibrio podrían ser: árboles Rojo-Negro, AVL o Adelson-Velskii y Landis, Splay, Scapegoat y más. Ejemplos de árboles autoequilibrados pueden ser: árboles rojo-negros, AVL o Adelson-Velskii y Landis, árboles Splay, árboles chivos expiatorios, etc.
Árbol de búsqueda binaria versus tabla hash Árbol de búsqueda binaria versus tabla hash
Ambos son rápidos para insertar, eliminar y acceder a cualquier elemento, incluso en tamaños grandes. Pero, como los árboles de búsqueda binarios permanecen ordenados, nos permiten sacar todos los elementos del árbol en orden, mientras que la tabla hash no garantiza un orden específico. Ambos métodos proporcionan una inserción y eliminación rápidas y un acceso rápido a cualquier elemento, incluso a los más grandes. Sin embargo, dado que los árboles de búsqueda binaria mantienen el orden, nos permiten sacar todos los elementos del árbol en orden, mientras que las tablas hash no pueden garantizar un orden específico.
Montón de montones
Los montones generalmente se implementan utilizando la idea de un árbol binario, no un árbol de búsqueda binario, pero sí un árbol binario. Son una forma de implementar otros tipos de datos abstractos como la cola de prioridad. El montón generalmente se implementa utilizando la idea de un árbol binario, no un árbol de búsqueda binario, sino un árbol binario. Son una forma de implementar otros tipos de datos abstractos, como colas de prioridad.
It’s a specific type of binary tree, where we add nodes from top to bottom, left to right, and child nodes must be less (or greater) than or equal their parents.
这是一种特定类型的二叉树,我们从上到下、从左到右添加节点,子节点必须小于(或大于)或等于它们的父节点。
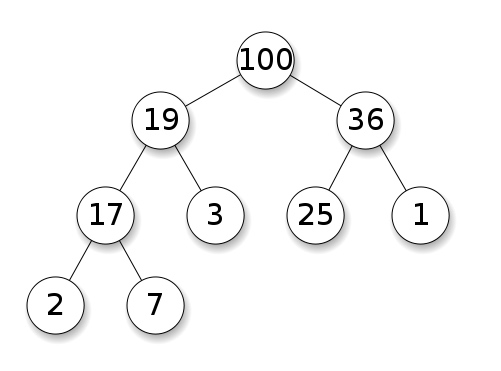 Max Heap - Wikipedia El montón más grande - Wikipedia
Max Heap - Wikipedia El montón más grande - Wikipedia
Por lo tanto, completamos completamente cualquier nivel antes de pasar al siguiente. Por lo tanto, no tenemos que preocuparnos de que el árbol se desequilibre como puede hacerlo un árbol de búsqueda binario. Así llenaremos por completo cualquier nivel antes de pasar al siguiente nivel. Por lo tanto, no tenemos que preocuparnos de que el árbol se desequilibre como un árbol de búsqueda binario.
Montón mínimo versus máximo
Un montón mínimo establece que cualquier nodo secundario debe ser mayor (o igual) que su nodo principal, mientras que un montón máximo establece que cualquier nodo secundario debe ser menor (o igual) que su nodo principal. Sin embargo, no nos importa si un nodo es menor o mayor que su hermano. Min-heap establece que cualquier nodo hijo debe ser mayor que (o igual que) su nodo padre, mientras que max-heap establece que cualquier nodo hijo debe ser menor que (o igual que) su nodo padre. Sin embargo, no nos importa si un nodo es más pequeño o más grande que sus hermanos.
¿Cómo funcionan los montones? ¿Cómo funciona el montón?
Entonces, en el caso de Min Heap: Entonces, para un montón mínimo:1. Seguimos agregando elementos de arriba a abajo, de izquierda a derecha. 2. Luego, compárelo con el nodo padre; ¿Es menor que su padre? Luego, compárelo con el nodo padre; ¿Es menor que su padre? 3. Si es así, intercambie el nodo con su padre. 4. Continúe realizando los pasos 2 al 3 hasta que el nodo sea mayor que su padre (o se convierta en el nodo raíz). como se muestra. Continúe ejecutando los pasos 2 a 3 hasta que el nodo sea más grande que su padre (o se convierta en el nodo raíz).
Este pequeño intercambio de nodos es la forma en que un montón se mantiene organizado. Este pequeño intercambio de nodos es la forma en que el montón se mantiene organizado.
El montón no está completamente ordenado El montón no está completamente ordenado
A diferencia de un árbol de búsqueda binario, que permanece ordenado y donde podemos recorrer fácilmente el árbol y recuperar todo en orden. A diferencia de los árboles de búsqueda binarios, que mantienen el orden, podemos recorrer fácilmente el árbol y recuperar todo en orden.
Porque si observa que en cualquier nivel particular más allá de la raíz, los valores no tienen que estar en ningún orden específico, siempre y cuando todos sean mayores (o menores) que su padre. Porque si observa, en cualquier nivel particular después de la raíz, los valores no tienen que aparecer en ningún orden particular, siempre y cuando todos sean mayores (o menores) que su padre.
Uno de los beneficios de esto es que un montón no tiene que reorganizarse tanto como podría ser necesario con un árbol de búsqueda binario. Un beneficio de esto es que el montón no tiene que reorganizarse tanto como lo hace con un árbol de búsqueda binario.
De lo único que podemos estar seguros es que el nodo principal siempre será menor o mayor que sus nodos secundarios y, por lo tanto, el valor mínimo o máximo siempre estará en la parte superior. Una cosa de la que podemos estar seguros es que un nodo padre siempre es más pequeño o más grande que sus hijos, por lo que el valor mínimo o máximo siempre está en la parte superior.
Y, por lo tanto, los montones son más útiles para la idea de una cola de prioridad. Por lo tanto, el montón es más útil para el concepto de colas de prioridad.
##Gráficos Gráficos
Las limitaciones de un árbol ya no existen aquí. Un nodo puede vincularse a muchos otros nodos, sin una secuencia específica ni un nodo raíz. Las limitaciones de los árboles ya no existen. Un nodo se puede vincular a muchos otros nodos sin ningún orden en particular y sin un nodo raíz.
Es una colección de nodos, donde un nodo puede vincularse a muchos otros nodos, sin una secuencia específica, sin un nodo raíz. Es una colección de nodos donde un nodo se puede vincular a varios otros nodos, sin ninguna secuencia particular y sin un nodo raíz.
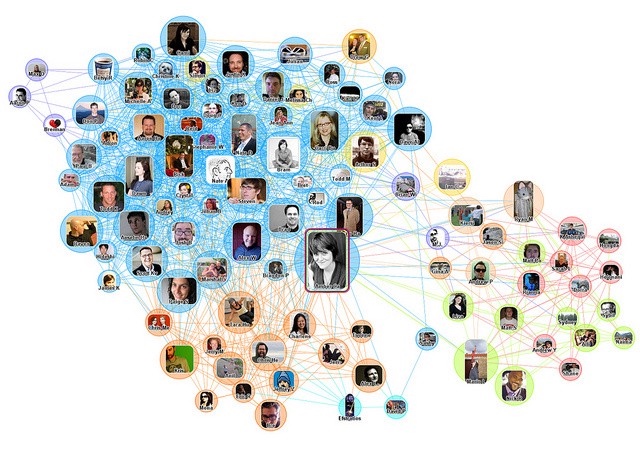 Un gráfico de una red social.
Diagrama de red social
Un gráfico de una red social.
Diagrama de red social
Teoría de grafos en matemáticas Teoría de grafos en matemáticas
Porque los gráficos en informática están estrechamente vinculados con la teoría de grafos en matemáticas. Es común escuchar el uso de términos matemáticos. Entonces, en teoría de grafos, llamamos a los nodos “vértices” y los enlaces entre ellos se denominan “bordes”. Porque los gráficos en informática y la teoría de gráficos en matemáticas están estrechamente relacionados. Es muy común utilizar términos matemáticos. Por lo tanto, en teoría de grafos, llamamos a los nodos “vértices” y a los enlaces entre ellos “aristas”.
Uso de gráficos Uso de gráficos
Podríamos usar un gráfico para modelar una red social con cada nodo como una persona. O modelar las distancias entre ciudades. Podríamos modelar una red ethernet en una oficina, en un edificio completo o en una ciudad. Podemos usar un gráfico para modelar una red social con nodos para cada persona. Alternativamente, modele la distancia entre ciudades. Podemos modelar una red Ethernet en una oficina, un edificio completo o una ciudad.
Gráficos directos e indirectos Gráficos directos e indirectos
También podemos decir si esos bordes deberían tener una dirección hacia ellos o no. También podemos decir si estos bordes deberían tener una dirección.
En algunas situaciones, tiene sentido que cualquier arista, cualquier conexión entre dos vértices, sea sólo unidireccional; Entonces, el nodo A está conectado al nodo B, mientras que lo contrario no es cierto; El nodo B NO está conectado al nodo A. En algunos casos, cualquier arista, cualquier conexión entre dos vértices, es unidireccional; por tanto, el nodo A está conectado al nodo B, pero no al revés; El nodo B no está conectado al nodo A.
En otras situaciones, es posible que desees poder seguir ese borde, ese vínculo, en cualquier dirección; Entonces, el nodo A está conectado al nodo B, y también el nodo B está conectado al nodo A. En otros casos, es posible que desees seguir este borde, este vínculo, en cualquier dirección; El nodo A se conecta al nodo B y el nodo B se conecta al nodo A.
Gráficos ponderados Gráfico ponderado
También puedes darle un peso a cada borde; asociando un número, con cada una de las aristas. También puedes darle un peso a cada borde; asociar un número con cada arista.
Podrías hacer esto para representar, por ejemplo, las distancias entre ciudades, si estuvieras intentando calcular la ruta más corta entre varias ubicaciones. O bien, podría utilizar un peso para indicar qué aristas tienen prioridad sobre otras aristas. Podrías representar, por ejemplo, la distancia entre ciudades si quisieras calcular la ruta más corta entre varias ubicaciones. Alternativamente, puede utilizar pesos para indicar qué bordes se prefieren sobre otros.
##Tipos de datos abstractos (ADT) tipos de datos abstractos (adt)
Antes de profundizar en los tipos de datos abstractos, qué son y la diferencia entre ellos y otros conceptos. Definamos qué se entiende por tipo de datos. Antes de profundizar en los tipos de datos abstractos, comprendamos qué son y en qué se diferencian de otros conceptos. Definamos qué significan los tipos de datos.
Tipo de datos Tipo de datos
El tipo de datos de una variable determina los valores que puede contener, además de las operaciones que se pueden realizar sobre ella.
Los tipos de datos constan de: tipos de datos primitivos, complejos o compuestos y abstractos. Los tipos de datos incluyen: tipos de datos básicos, tipos de datos complejos o tipos de datos compuestos y tipos de datos abstractos.
Un tipo de datos abstractos (ADT) Tipo de datos abstractos (ADT)Es un tipo de datos, al igual que los tipos de datos primitivos enteros y booleanos. Un ADT consta no sólo de operaciones, sino también de valores de los datos subyacentes y de restricciones sobre las operaciones.
Es un tipo de datos, al igual que los tipos de datos primitivos enteros y booleanos. ADT contiene no solo operaciones, sino también los valores de los datos subyacentes y las restricciones de las operaciones.
Una restricción para una pila sería que cada pop siempre devuelve el elemento enviado más recientemente que aún no se ha popeado. La restricción de la pila es que cada pop siempre devuelve el elemento enviado más recientemente que aún no se ha popeado.
La implementación real de un ADT se abstrae y no tenemos que preocuparnos por ella. Entonces, cómo se implementa realmente una pila no es tan importante. Una pila podría implementarse, y a menudo se implementa, detrás de escena utilizando una matriz dinámica, pero en su lugar podría implementarse con una lista vinculada. Realmente no importa. La implementación real de ADT es abstracta y no es necesario que nos preocupemos. Entonces, no importa cómo se implemente la pila. Las pilas pueden implementarse, y generalmente se implementan, mediante matrices dinámicas internas, pero también se pueden implementar mediante listas vinculadas. Realmente no importa.
Listas, pilas, colas y más son tipos de datos abstractos. Listas, pilas, colas, etc. son todos tipos de datos abstractos.
Un tipo de datos abstracto y una estructura de datos Tipo de datos abstracto y una estructura de datos
ADT no es una alternativa a una estructura de datos, son conceptos diferentes. ADT no reemplaza las estructuras de datos, son conceptos diferentes.
Cuando decimos estructura de datos de la pila, nos referimos a cómo se implementan y organizan las pilas en la memoria. Pero, cuando decimos ADT de pila, nos referimos al tipo de datos de pila que tiene un conjunto de operaciones definidas, las restricciones de operaciones y los valores posibles. Cuando hablamos de estructura de datos de la pila, nos referimos a cómo se implementa y organiza la pila en la memoria. Sin embargo, cuando decimos ADT de pila, nos referimos a un tipo de datos de pila que tiene un conjunto definido de operaciones, restricciones de operación y valores posibles.
No nos importa la implementación subyacente, al igual que cuando usamos números enteros, nos abstraemos de cómo se representan los números enteros en la memoria, solo nos interesan las operaciones (suma, resta,…) y los valores posibles (…, −2, −1, 0, 1, 2,…). No nos importa la implementación subyacente, ya que cuando trabajamos con números enteros, nos alejamos de la representación de números enteros en la memoria, solo nos interesan las operaciones (suma, resta,…) y los valores posibles (…−2−1,0,1,2,…).
Las estructuras de datos pueden implementar uno o más tipos de datos abstractos (ADT) particulares, que especifican las operaciones que se pueden realizar en una estructura de datos. Una estructura de datos puede implementar uno o más tipos de datos abstractos (ADT) específicos, que especifican las operaciones que se pueden realizar en la estructura de datos.
Un tipo de datos abstracto NO es una clase abstracta Un tipo de datos abstracto NO es una clase abstracta
Ambos no tienen nada que ver el uno con el otro. Una clase abstracta define sólo las operaciones, a veces con comentarios que describen las restricciones, dejando la implementación real a las clases herederas. Ninguno tiene nada que ver con el otro. Las clases abstractas solo definen operaciones, a veces con anotaciones que describen restricciones, dejando la implementación real a las clases heredadas.
Aunque los ADT suelen implementarse como interfaces (clases abstractas) como en Java. Por ejemplo, la interfaz List en Java define las operaciones de List ADT, mientras que las clases heredadas definen la implementación real (estructura de datos). Mientras que los anuncios generalmente se implementan como interfaces (clases abstractas), como en Java. Por ejemplo, la interfaz List en Java define las operaciones de List ADT, mientras que las clases heredadas definen la implementación real (estructura de datos).
Pero este no es siempre el caso. Por ejemplo, Java tiene una clase de pila. Es una clase concreta normal, pero una pila también es un tipo de datos abstracto, es decir, representa la idea de tener una estructura de datos de último en entrar, primero en salir. Entonces, stack es una clase concreta real y también es un tipo de datos abstracto. Pero este no es siempre el caso. Por ejemplo, Java tiene una clase de pila, que es una clase concreta normal, pero la pila también es un tipo de datos abstracto, es decir, representa una estructura de datos de último en entrar, primero en salir. Stack es una clase concreta y un tipo de datos abstracto.
Un tipo de datos abstracto es un concepto teórico Un tipo de datos abstracto es un concepto teórico
Un tipo de datos abstracto (ADT) es un concepto teórico que es irrelevante para la programación de palabras clave. El tipo de datos abstracto (ADT) es un concepto teórico que no tiene nada que ver con las palabras clave de programación.
Entonces, si tenemos una pila, tenemos una estructura de datos de último en entrar, primero en salir, que podemos empujar, abrir y mirar. Eso es lo que esperamos que pueda hacer una pila. Ya sea que una pila se implemente como una clase concreta o lo que sea, todavía tiene la idea de una estructura de datos de último en entrar, primero en salir. Entonces, si tenemos una pila, tenemos una estructura de datos LIFO que podemos empujar, abrir y mirar. Esto es lo que esperamos que haga la pila. Independientemente de si la pila se implementa como una clase concreta o algo más, todavía tiene el concepto de una estructura de datos de último en entrar, primero en salir.
##Conclusión Conclusión
Decidir sobre la estructura de datos Determinar la estructura de datos
Hay algunas preguntas clave que debe hacerse antes de decidir sobre la estructura de datos. Antes de decidirse por una estructura de datos, es necesario plantearse algunas preguntas clave
*¿Cuántos datos tienes? ¿Cuántos datos tienes?
- ¿Con qué frecuencia cambia? ¿Con qué frecuencia cambia?
- ¿Necesitas ordenarlo, necesitas buscarlo? ¿Más rápido para acceder, insertar o eliminar? ¿Más rápido para acceder, insertar o eliminar?
Si hay un lugar donde solo tienes cantidades triviales de datos, no importará mucho. A menos, por supuesto, que esas cantidades de datos cambien con tanta frecuencia o que tenga grandes cantidades de datos. Si sólo hay una pequeña cantidad de datos en algún lugar, no importa. A menos, por supuesto, que estos volúmenes de datos cambien con mucha frecuencia o que tenga muchos datos.### Estructuras de datos inmutables Estructuras de datos inmutables Ahora, un principio general de que las estructuras de datos inmutables o de tamaño fijo tienden a ser más rápidas y más pequeñas en la memoria que las mutables. Ahora bien, un principio general es que las estructuras de datos inmutables o de tamaño fijo tienden a ser más rápidas y más pequeñas en memoria que las estructuras mutables.
¿Por qué deberíamos restringir las características de las matrices? La razón es que cuantas más restricciones tenga (como tamaño fijo, tipo de datos específico,…), más rápida y pequeña podrá ser su estructura de datos. ¿Por qué limitar las características de las matrices? La razón es que cuantas más restricciones (como tamaño fijo, tipo de datos específico…), más rápida y pequeña será la estructura de datos.
El problema de tener una estructura de datos con muchas características (no restringidas) es que el compilador no puede asignar la cantidad ideal de espacio, por lo tanto, debe introducir gastos generales para respaldar la flexibilidad de la estructura de datos (como diferentes tipos de datos,…). El inconveniente de las estructuras de datos con muchas características (sin restricciones) es que el compilador no puede asignar una cantidad ideal de espacio y, por lo tanto, debe introducir gastos generales para respaldar la flexibilidad de la estructura de datos (como diferentes tipos de datos,…).
Mejore el rendimiento de su código Mejore el rendimiento de su código
Si está mirando el código existente para ver qué mejorar, entonces vea lo que contenga la mayor cantidad de datos. No hay mejor manera de aprovechar al máximo estas estructuras de datos que ver algunas de las mejoras de rendimiento que puede obtener, simplemente cambiando de una estructura a otra. Si está mirando el código existente para ver dónde necesita mejorar, observe dónde se guarda la mayor cantidad de datos. Cuando ve que puede obtener algunas mejoras de rendimiento simplemente cambiando de una estructura a otra, no hay mejor manera de aprovechar al máximo estas estructuras de datos.
Diferencias de idiomas Diferencias de idiomas
Los algoritmos utilizados con cada estructura de datos difieren de un idioma a otro, y la implementación real de la estructura de datos difiere de un idioma a otro. Por lo tanto, vale la pena examinar detenidamente la documentación del idioma. Los algoritmos utilizados por cada estructura de datos varían de un idioma a otro, y la implementación real de la estructura de datos varía de un idioma a otro. Por lo tanto, es necesario revisar cuidadosamente la documentación del idioma.
What to read next
Want more posts about Algorithms?
Posts in the same category are usually the best next step for reading more on this topic.
View same categoryWant to keep following #Algorithms?
Tags are useful for related tools, specific problems, and similar troubleshooting notes.
View same tagWant to explore another direction?
If you are not sure what to read next, return to the homepage and start from categories, topics, or latest updates.
Back home